Dr Rajiv Desai
An Educational Blog
SYNTHETIC BIOLOGY (SYNBIO)
Synthetic Biology (synbio):
_______

Scientists Elizabeth Allman and Kristin O’Brien teach a course in synthetic biology at the University of Alaska Fairbanks. O’Brien said that the goal of synthetic biology is not to build “better organisms” but rather to create biological machines.
_______
Prologue:
The advent of digital technology is considered one of the biggest revolutions of all time for how quickly and deeply it changed the world forever. Even more powerful revolution is coming, which goes under the name of synthetic biology. The potential of this discipline is very well understood in the biological scientific world. It is time I make general public aware of the impact it will have on our lives. Synthetic biology brings together a bewildering number of disciplines: biotechnology, molecular biology, systems biology, biophysics, computer engineering, genetic engineering, and more. Synthetic biology will allow scientists and engineers to create biological systems that do not occur naturally as well as to re-engineer existing biological systems to perform novel and beneficial tasks. The term “synthetic biology” was introduced in 1978 by molecular biologist and geneticist Wacław Szybalski. Synthetic biology is considered as an amalgamation of principles of engineering and biology. At its core, it’s all about the selective assembly of genetic information. This is where the connection with computer science comes into play. Synthetic biologists aren’t just copying and pasting existing DNA from one place to another—they’re looking to figure out how specific sequences work and then putting them together into new configurations. The idea is that you can figure out what given segments of DNA do and then patch them together, much as you would with lines of computer code, effectively programming cells to behave in new ways. The scientists involved treat DNA a bit like a computer programme. The aim is to rewrite life’s internal operating system: design a new programme, print it out and run it in a cell which has been cleaned of its own genetic material to perform functions that may or may not be found in nature or create genetic machines from scratch. Now we can read and write the genetic code, put it in digital form and translate it back into synthesized life. Ten years ago, genetic engineering was limited to cutting and pasting DNA from existing organisms. Today’s biologists can write down gene sequences that have never existed anywhere, place an order over the Internet, and receive the desired DNA by return mail. As the cost of sequencing and DNA synthesis continues to drop, ambitious ideas for synthetic biology are becoming more affordable and achievable. In Boston, scientists and students conduct so called “synbio” projects developing odorless E. coli cells meant to synthesize wonder protein containing essential amino acids. Synthetic biology can create synthetic food, chemicals, biofuels, diagnostics, antibiotics and even building materials. It’s easy to imagine nightmarish synbio-powered science fiction scenarios such as terrorists designing custom viruses designed to target specific populations. Alternately, seemingly benign lab-grown organisms might behave in unexpected ways when they interact with ecosystems, threatening the natural balance. The danger is not just bio-terror, but bio-error. And, at a more structural level, some fear that these technologies could suddenly disrupt industries such as farming, potentially driving billions deeper into poverty. But that’s all very far away. In many ways, it’s the very definition of an emerging field. Its promises are enormous, but progress remains incremental.
______
“A Scientist discovers that which exists; an Engineer creates that which never was.”
– Theodore von Karmen
_______
Note:
Please read my articles ‘Genetically Modified’ and ‘Gene Therapy’ published earlier in this website. A genetically modified organism (GMO) is an organism (plant/ animal/ microorganism etc.) whose genetic material (DNA) has been altered using genetic engineering techniques by either adding a gene from a different species or over-expressing/ silencing a pre-existing native gene. Genetic material in an organism can be altered without genetic engineering techniques which include mutation breeding where an organism is exposed to radiation or chemicals to create a non-specific but stable change, selective breeding (plant breeding and animal breeding), hybridizing and somaclonal variation. However, these organisms are not labelled as GMO. Gene therapy can broadly be considered any treatment that changes gene function to alleviate a disease state. Gene therapy means man-made transfer/alteration/ expression/suppression of DNA/RNA in human/animal cells for the purpose of prophylaxis and/or treatment of a disease state. Replacing a defective gene by normal gene is one of the types of gene therapy. Other types include gene editing, gene silencing, insertion of novel genes, gene reprogramming, DNA vaccine etc. Gene therapy is one of the methods of genetic engineering and in the puritan medical terminology; any individual who has received gene therapy necessarily becomes genetically modified organism (GMO). Synthetic biology is an extreme version of genetic engineering and organism created by synthetic biology is labelled as synthetically modified organism (SMO).
_______
Abbreviations and synonyms:
XNA = xeno-nucleic acids
SB = synthetic biology = synbio
AL = artificial life
AI = artificial intelligence
bp = base pairs
Mbp = million bp
GMO = genetically modified organisms
GE = genetic engineering
SMO = synthetically modified organisms
JCVI = J. Craig Venter Institute in Rockville, Maryland.
CRISPR = Clustered Regularly Interspaced Palindromic Repeats
PCR = polymerase chain reaction
SBPs = Synthetic biology projects
_______
Terminology:
Here’s a list of some important terms that will help you understand what we’re talking about when discussing synbio technology.
_
Amino acid: The building block of proteins, which are essential to all life forms. There are twenty-two different amino acids, twenty of which are encoded by human genes and two are produced by other biological processes. These amino acids, also called residues, can be strung together in different combinations, each combination resulting in a unique protein.
_
Protein: A biological polymer made of amino acids strung together in a specific sequence.
_
Base: One of five chemical structures that can make up part of a nucleoside. The names of the bases are adenine (A), cytosine (C), guanine (G), thymine (T) and uracil (U). Adenine, cytosine, and guanine are used in both DNA and RNA whereas thymine is only used in DNA and uracil is its RNA counterpart.
_
Base pair: A specific pairing of bases that enable the helical structure of both DNA and RNA. Cytosine always pairs with guanine using three hydrogen bonds, and adenine with thymine (in DNA) or uracil (in RNA) with two hydrogen bonds
_
Nucleoside: Nucleosides consist of a ribose (or deoxyribose) sugar linked to a base. They are strung together to form DNA and RNA, with a phosphate group linking each nucleoside to the next.
_
Nucleotide: Nucleotides are the building blocks of nucleic acids; they are composed of three subunit molecules: a nitrogenous base, a five-carbon sugar (ribose or deoxyribose), and phosphate group. Nucleotide is nucleoside with phosphate.
_
Codon: A sequence of three nucleotides that codes for a specific amino acid.
_
Oligonucleotide (oligo): A short DNA or RNA polymer that is usually less than 100 nucleotides in length. It is often man-made (synthetic DNA or RNA).
_
Recombinant DNA: DNA that has been formed artificially by combining constituents from different organisms. Recombinant DNA (rDNA) molecules are DNA molecules formed by laboratory methods of genetic recombination (such as molecular cloning) to bring together genetic material from multiple sources, creating sequences that would not otherwise be found in the genome.
_
Synthetic DNA: DNA generated using synthetic biology tools rather than extracted from a living organism. The resulting synthetic DNA can be created in exactly the same sequence as the DNA from a living organism. Synthetic DNA cannot create new organisms (even microscopic ones) from scratch, but can be used to add beneficial character traits to a plant (self-fertilizing, drought tolerant) or engineer new drugs or vaccines like artemisinin for malaria.
_
Part (Biological part): is a sequence of DNA that encodes for a biological function, for example promoters or protein coding sequences. At its simplest, a basic part is a single functional unit that cannot be divided further into smaller functional units. Basic parts can be assembled together to make longer, more complex composite parts, which in turn can be assembled together to make devices that will operate in living cells.
_
BioBricks: Standard synthetic DNA sequences of known structure and function that can be used as “Lego-like” building blocks. These can be combined in different ways to generate a specific form and function. When inserted into living organisms, BioBricks create new, or replicate existing, biological systems. Over 20,000 parts are currently available in the Registry of Standard Biological Parts.
_
DNA-based circuits: The rational design of DNA sequences to create biological circuits with predictable, discrete functions, which can be combined in various cell hosts.
_
Chassis: The cell or organism into which BioBricks are inserted, producing a new biological system.
_
Minimal genome: It is generally defined as the smallest set of genes that allows for replication of the organism in a particular environment. It is the minimal number of parts (genes) needed for life, to serve as a chassis for engineering minimal cell factories for new functions.
_
Cloning: Molecular cloning is the process of inserting foreign DNA into a cell in order to create many copies of it and/or translate it into protein.
_
CRISPR/Cas9: A naturally-occurring system that has recently been used as a synthetic biology tool to edit genes. This system allows for the precise inactivation or recoding of any gene through the insertion, deletion or substitution of nucleotide sequences.
_
Data storage: A term that refers to any method used to store and archive digital data. Synthetic DNA can be used to store digital data, which researchers predict would be error-free when recovered after up to 1 million years.
_
DNA synthesis: A process for producing DNA from individual nucleotides in the laboratory. These DNA fragments can be used as gene parts or building blocks to assemble whole genes or libraries. They are also used ubiquitously throughout academia and industry to study biology and develop medical products, such as vaccines and diagnostic tests
_
Engineering Biology: another term used to refer to synthetic biology (synbio).
_
Expression: The process by which genetic information stored in DNA is transformed into a cellular function. Expression is a-2 step process, first transcription of DNA into RNA, and second translation into protein. Example of expression is production of insulin to process sugar.
_
Gene: The basic unit of heredity; a specific DNA sequence that codes for a protein or RNA required for the organism to develop and function.
_
Genome: The complete set of genetic information of an organism, stored in genes made of DNA (most often) or RNA (rare).
_
Gene editing: The ability to insert a beneficial sequence, replace a mutated sequence or remove a diseased sequence of DNA using systems such as CRISP/Cas9.
_
Gene regulation: The control of gene expression. This can be effected by turning the expression of genes on and off at specific times through modulation of both direct and indirect factors such as promoters and enhancers.
_
Genetic engineering: Direct human manipulation of an organism’s genetic material, to add new traits not already found in that organism, or to delete an unwanted disease gene.
_
iGEM (international Genetically Engineered Machine competition): A foundation dedicated to advancement of synthetic biology through education and competition. In its annual worldwide competition, college and high school level participants use standard parts and their own design to build new biological systems.
_
Mutation: Change in a gene that occurs randomly or in response to radiation or chemical mutagens. Alternatively, using the synthesis of DNA, specific mutations can be designed on purpose by researchers for precise and controlled experimentation.
_
Nanobiology: A branch of biology that deals with biological interactions at a very small (nano) scale, often involving structures that are only millionths of an inch in size.
_
Pathway: In biology, a pathway describes a series of actions between molecules that can lead to a change in a cell and/or a product such as sugar, protein, fat or organic molecules. A pathway is usually encoded as a string of genes in a long fragment of DNA.
_
PCR (Polymerase Chain Reaction): It is a technique used in molecular biology to amplify a single copy or a few copies of a segment of DNA across several orders of magnitude, generating thousands to millions of copies of a particular DNA sequence through the action of polymerases.
_
Sequence: The specific order in which amino acids, deoxynucleotides, and ribonucleotides are strung together to form a specific protein, DNA or RNA, respectively.
_
Sequencing: Process by which scientists determine the specific order of base pairs within DNA, RNA, or protein.
_
Living modified organism: Any living organism that possesses a novel combination of genetic material obtained through the use of modern biotechnology.
_
Living organism: Any biological entity capable of transferring or replicating genetic material, including sterile organisms, viruses and viroids.
_
Protocell (artificial cell): Protocells are living cells constructed from scratch capable of reproduction, self-maintenance, metabolism and evolution. Bottom-up synthetic biology approach produces protocells cells and compartments.
_
Xenobiology: The study and development of life forms based on biochemistry not found in nature. This includes xeno-nucleic acids XNA (synthetic alternatives to the natural nucleic acids DNA and RNA) and amino acids that are not found in the natural genetic code of organisms. Xenobiology could provide a biosafety tool by preventing interactions between synthetic organisms and the natural world (xeno-nucleic acids can prevent genetic exchange with wild organisms, as they cannot hybridise with natural genetic material).
_
Digital logic gate: An idealized or physical device that implements Boolean logic (such as AND, OR, NOT) on one or more inputs to produce a single output
_
Orthogonal biosystems: Engineering cells/organisms to include systems or parts not found in nature to impart new capacities or chemistry. Orthogonal systems operate independently of the cell’s natural machinery.
_
Bionanoscience: Utilising and exploiting synthetic molecular (nano) machines based on cellular systems
_
Biofuels: Sources of energy derived from biomass such as plants, algae and animal waste products. The use of biofuels could substantially reduce greenhouse gas emissions by recycling carbon dioxide from the air and replacing fossil fuels such as oil. Synthetic biology tools are often used to in the development of biofuels.
_______
_______
DNA and RNA:
Deoxyribonucleic acid (DNA) is a molecule that carries the genetic instructions used in the growth, development, functioning and reproduction of all known living organisms and many viruses. DNA and RNA are nucleic acids; alongside proteins, lipids and complex carbohydrates (polysaccharides), they are one of the four major types of macromolecules that are essential for all known forms of life. Most DNA molecules consist of two biopolymer strands coiled around each other to form a double helix. The two DNA strands are termed polynucleotides since they are composed of simpler monomer units called nucleotides. Each nucleotide is composed of one of four nitrogen-containing nucleobases—either cytosine (C), guanine (G), adenine (A), or thymine (T)—and a sugar called deoxyribose and a phosphate group. The nucleotides are joined to one another in a chain by covalent bonds between the sugar of one nucleotide and the phosphate of the next, resulting in an alternating sugar-phosphate backbone. The nitrogenous bases of the two separate polynucleotide strands are bound together according to base pairing rules (A with T, and C with G) with hydrogen bonds to make double-stranded DNA. The total amount of related DNA base pairs on Earth is estimated at 5.0 x 10^37 and weighs 50 billion tonnes.
_
The structure of part of a DNA double helix:
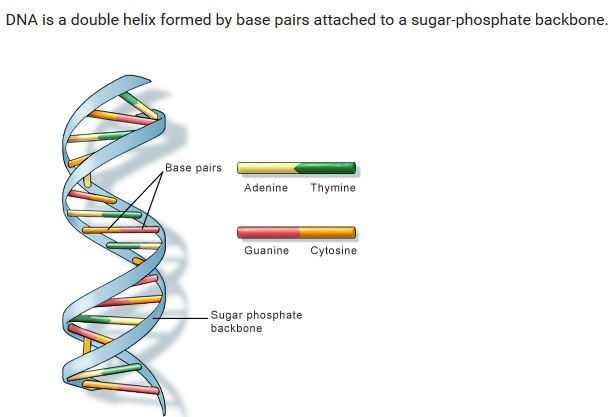
In living organisms, DNA does not usually exist as a single molecule, but instead as a pair of molecules that are held tightly together. These two long strands entwine like vines, in the shape of a double helix. The nucleotide contains both a segment of the backbone of the molecule (which holds the chain together) and a nucleobase (which interacts with the other DNA strand in the helix). A nucleobase linked to a sugar is called a nucleoside and a base linked to a sugar and one or more phosphate groups is called a nucleotide. A polymer comprising multiple linked nucleotides (as in DNA) is called a polynucleotide.

__
__
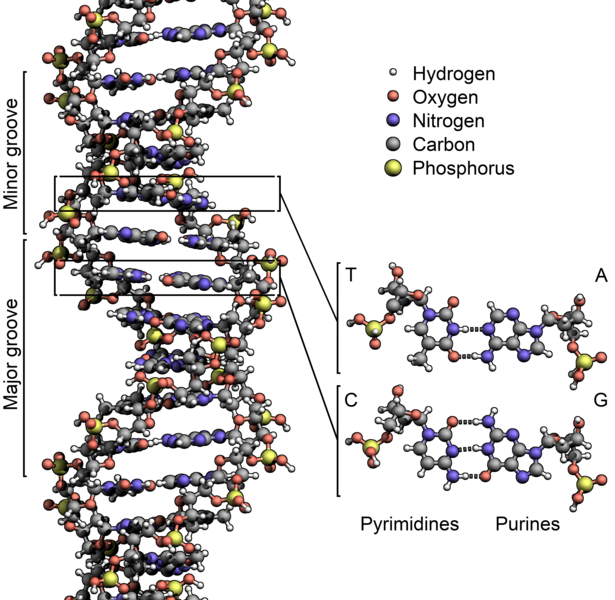
Atoms in DNA:
Figure below shows atoms in the DNA molecule colour-coded by element and the detailed structure of two base pairs are shown in the bottom right.
__
DNA stores biological information. DNA is a molecule that contains the instructions an organism needs to develop, live and reproduce. These instructions are found inside every cell, and are passed down from parents to their children. The DNA backbone is resistant to cleavage, and both strands of the double-stranded structure store the same biological information. This information is replicated as and when the two strands separate. A large part of DNA (more than 98% for humans) is non-coding, meaning that these sections do not serve as patterns for protein sequences. The two strands of DNA run in opposite directions to each other and are thus antiparallel. Attached to each sugar is one of four types of nucleobases (informally, bases). It is the sequence of these four nucleobases along the backbone that encodes biological information. The order of these bases is what determines DNA’s instructions, or genetic code. Similar to the way the order of letters in the alphabet can be used to form a word, the order of nitrogen bases in a DNA sequence forms genes, which in the language of the cell, tells cells how to make proteins. The entire human genome contains about 3 billion bases and about 20,000 genes. RNA strands are created using DNA strands as a template in a process called transcription. Under the genetic code, these RNA strands are translated to specify the sequence of amino acids within proteins in a process called translation. The regular structure and data redundancy provided by the DNA double helix make DNA well suited to the storage of genetic information, while base-pairing between DNA and incoming nucleotides provides the mechanism through which DNA polymerase replicates DNA, and RNA polymerase transcribes DNA into RNA.
_
DNA is a long polymer made from repeating units called nucleotides. The structure of DNA is dynamic along its length, being capable of coiling into tight loops, and other shapes. In all species it is composed of two helical chains, bound to each other by hydrogen bonds. Both chains are coiled round the same axis, and have the same pitch of 34 ångströms (3.4 nanometres). The pair of chains has a radius of 10 ångströms (1.0 nanometre). According to another study, when measured in a different solution, the DNA chain measured 22 to 26 ångströms wide (2.2 to 2.6 nanometres), and one nucleotide unit measured 3.3 Å (0.33 nm) long. Although each individual nucleotide repeating unit is very small, DNA polymers can be very large molecules containing millions to hundreds of millions of nucleotides. For instance, the DNA in the largest human chromosome, chromosome number 1, consists of approximately 220 million base pairs and would be 85 mm long if straightened.
_
A gene is a sequence of DNA that contains genetic information and can influence the phenotype of an organism. Within a gene, the sequence of bases along a DNA strand defines a messenger RNA sequence, which then defines one or more protein sequences. The relationship between the nucleotide sequences of genes and the amino-acid sequences of proteins is determined by the rules of translation, known collectively as the genetic code. The genetic code consists of three-letter ‘words’ called codons formed from a sequence of three nucleotides (e.g. ACT, CAG, TTT). In transcription, the codons of a gene are copied into messenger RNA by RNA polymerase. This RNA copy is then decoded by a ribosome that reads the RNA sequence by base-pairing the messenger RNA to transfer RNA, which carries amino acids. Since there are 4 bases in 3-letter combinations, there are 64 possible codons (64 possible permutations, or combinations of three-letter nucleotide sequences that can be made from the four nucleotides). Of the 64 codons, 61 represent 20 natural amino acids, and three are stop signals. For example, the codon CAG represents the amino acid glutamine, and TAA is a stop codon. The genetic code is described as degenerate, or redundant, because a single amino acid may be coded for by more than one codon. When codons are read from the nucleotide sequence, they are read in succession and do not overlap with one another.
__
Within eukaryotic cells, DNA is organized into long structures called chromosomes. During cell division these chromosomes are duplicated in the process of DNA replication, providing each cell its own complete set of chromosomes. Eukaryotic organisms (animals, plants, fungi, and protists) store most of their DNA inside the cell nucleus and some of their DNA in organelles, such as mitochondria or chloroplasts. In contrast, prokaryotes (bacteria and archaea) store their DNA only in the cytoplasm. Within the eukaryotic chromosomes, chromatin proteins such as histones compact and organize DNA. These compact structures guide the interactions between DNA and other proteins, helping control which parts of the DNA are transcribed.
_
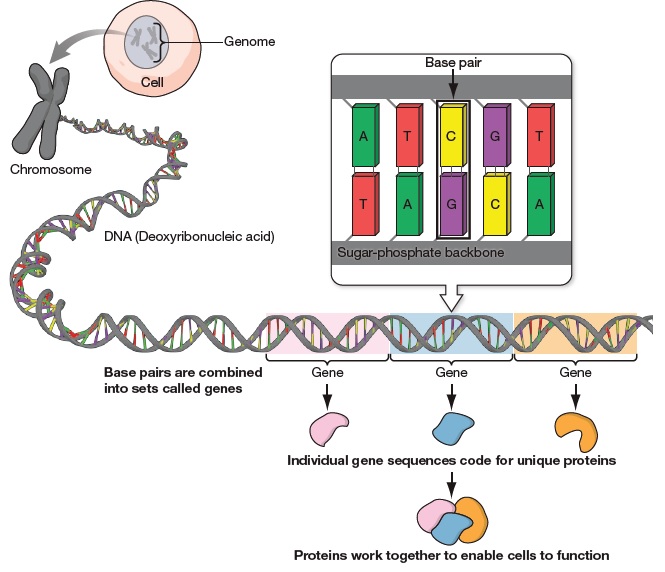
Figure below depicts protein synthesis from genetic code:
_
RNA:
Like DNA, RNA (ribonucleic acid) is assembled as a chain of nucleotides, but unlike DNA it is more often found in nature as a single-strand folded onto itself, rather than a paired double-strand. In RNA, adenine and uracil (not thymine) link together, while cytosine still links to guanine. Cellular organisms use messenger RNA (mRNA) to convey genetic information (using the letters G, U, A, and C to denote the nitrogenous bases guanine, uracil, adenine, and cytosine) that directs synthesis of specific proteins. In protein synthesis RNA molecules direct the assembly of proteins on ribosomes. This process uses transfer RNA (tRNA) molecules to deliver amino acids to the ribosome, where ribosomal RNA (rRNA) then links amino acids together to form proteins. Many viruses encode their genetic information using an RNA genome. Some RNA molecules play an active role within cells by catalyzing biological reactions, controlling gene expression, or sensing and communicating responses to cellular signals.
_
Figure below depicts differences between DNA and RNA:
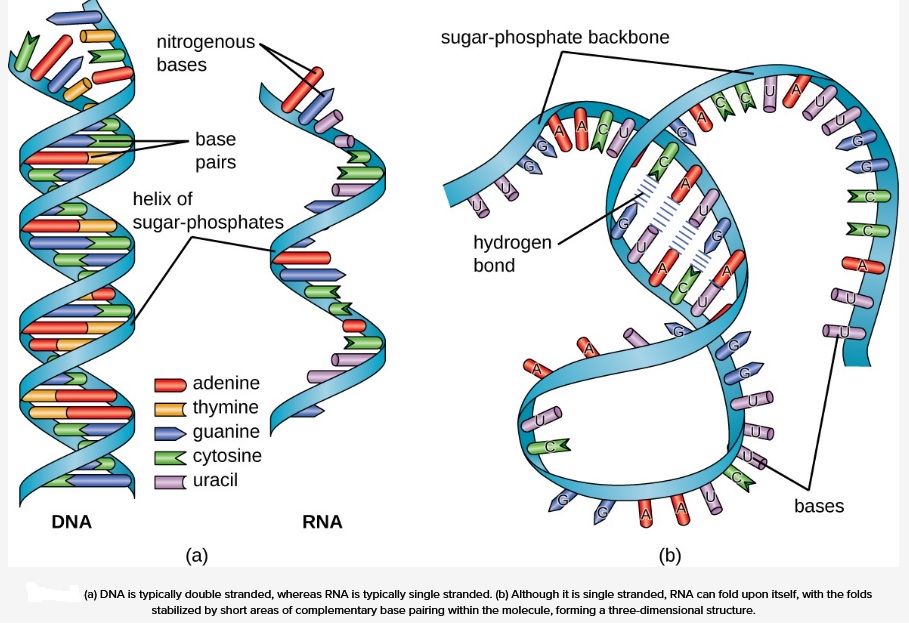
_
_
Table below shows differences between DNA and RNA:
| DNA | RNA | |
| Difference: | 1. Found in nucleus 2. sugar is deoxyribose 3. Bases are A,T,C,G | 1. Found in nucleus and cytoplasm 2.sugar is ribose. 3. Bases are A,U,C,G |
| Bases & Sugars: | DNA is a long polymer with a deoxyribose and phosphate backbone and four different bases: adenine, guanine, cytosine and thymine | RNA is a polymer with a ribose and phosphate backbone and four different bases: adenine, guanine, cytosine, and uracil |
| Definition: | A nucleic acid that contains the genetic instructions used in the development and functioning of all known living organisms | RNA, single-stranded chain of alternating phosphate and ribose units with the bases adenine, guanine, cytosine, and uracil bonded to the ribose. RNA molecules are involved in protein synthesis and sometimes in the transmission of genetic information. |
| Job/Role: | Medium of long-term storage and transmission of genetic information | The main job of RNA is to transfer the genetic code need for the creation of proteins from the nucleus to the ribosome. This process prevents the DNA from having to leave the nucleus, so it stays safe. Without RNA, proteins could never be made. |
| Stands for: | DeoxyriboNucleicAcid | RiboNucleicAcid |
| Predominant Structure: | Typically a double- stranded molecule with a long chain of nucleotides | A single-stranded molecule in most of its biological roles and has a shorter chain of nucleotides |
| Pairing of Bases: | A-T(Adenine-Thymine), G-C(Guanine-Cytosine) | A-U(Adenine-Uracil), G-C(Guanine-Cytosine) |
| Stability: | Deoxyribose sugar in DNA is less reactive because of C-H bonds. Stable in alkaline conditions. DNA has smaller grooves where the damaging enzyme can attach which makes it harder for the enzyme to attack DNA. | Ribose sugar is more reactive because of C-OH (hydroxyl) bonds. Not stable in alkaline conditions. RNA on the other hand has larger grooves which makes it easier to be attacked by enzymes. |
| Unique features | The helix geometry of DNA is of B-Form. DNA is completely protected by the body i.e. the body destroys enzymes that cleave DNA. DNA can be damaged by exposure to Ultra-violet rays. | The helix geometry of RNA is of A-Form. RNA strands are continually made, broken down and reused. RNA is more resistant to damage by Ultra-violet rays. |
_
Genome size:
Genome size is the total amount of DNA contained within one copy of a single genome. It is typically measured in terms of mass in picograms [trillionths of a gram, abbreviated pg] or less frequently in Daltons or as the total number of nucleotide base pairs typically in megabases (millions of base pairs, abbreviated Mb or Mbp). One picogram equals 978 megabases.
_
bp = base pair (e.g. A with T)
1 kb = 1000 bp (e.g. viral genome)
1Mb = 1000,000 bp (e.g. bacterial genome)
I Gb = 1000,000,000 bp (e.g. mammal genome)
_
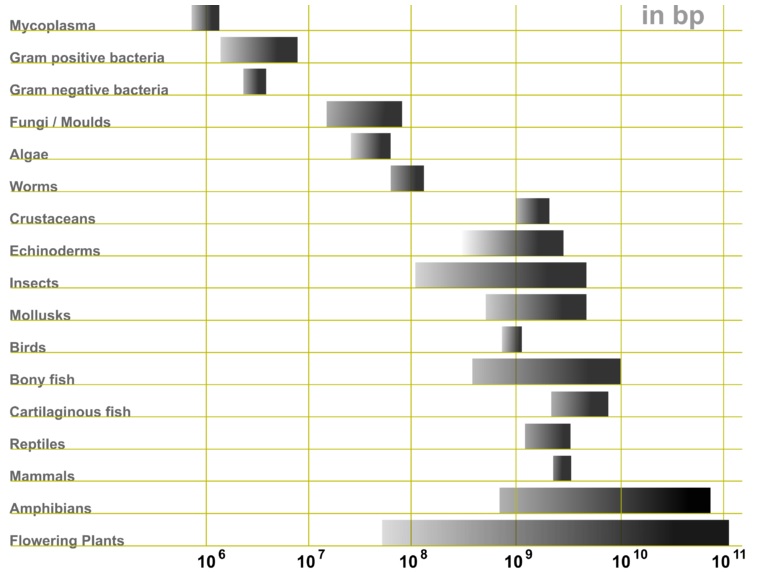
_
The figures above and below show genome size ranges (in base pairs) of various life forms.
_

_
DNA is exceedingly simple. Think of it like a language, but with only four letters — A, C, G, T. The complex ways in which these letters can be combined gives rise to life. These four letters build words, sentences, paragraphs, chapters and books — one for each living organism on Earth. It is a living code — the “biocode.” Each genome is an autobiography. The letters and words explain traits like eye, hair and skin color, genetic health problems and myriad other traits. DNA can be a crystal ball — like when it tells us whether a newborn has a genetic disease or not — and it holds clues to our past. Our DNA is the DNA of our distant ancestors. In fact, we are almost 99 percent chimpanzee, human beings’ nearest relative. If you look back through the four billion years of life, you’ll find that 37 percent of our genes come from single-celled bacterial ancestors. Being able to read out our DNA opens the doors to a range of possibilities, but it also brings talk of privacy breaches, genetic discrimination, eugenics, designer babies, de-extinction and new life forms. It is already possible to recreate deadly viruses from the digital copies of their genomes. World leaders ranked synthetic biology threats as one of the top risks facing the world at the 2015 Davos summit. DNA research is a field where what once seemed like science fiction is becoming reality. Heather Dewey-Hagborg, an artist, started picking up genetic trash on the streets of New York and using the analysis of a few genes, like those for eye color and gender, created faces she then 3D printed. Companies have sprung up to offer 3D mug shot services to police. Comb your hair in public and you could be leaving behind a DNA hologram of yourself. This raises deep questions about the possibility of widespread genetic surveillance.
______
Information storage in DNA:
We’re getting better at shrinking the physical size of data storage devices while simultaneously increasing the stoarge capacity, with hundreds of gigabytes of data squeezing onto devices that fit in the palm of a hand. But far more data is produced each year than our current technology will be able to keep up with as the world’s total data heads towards an estimated 44 trillion GB by 2020. Unfortunately, even the best of our current range of devices are only relatively short-term solutions to the problem. Hard drives, and optical storage such as DVDs and Blu-Ray discs, are vulnerable to damage and degradation, with a life expectancy of a few decades at best. Scientists are increasingly looking to nature’s hard drive, DNA, as a potential solution to both the capacity and longevity problems. DNA digital data storage refers to any scheme to store digital data in the base sequence of DNA. This technology uses artificial DNA made using commercially available oligonucleotide synthesis machines for storage and DNA sequencing machines for retrieval. This type of storage system is more compact than current magnetic tape or hard drive storage systems due to the data density of the DNA. It also has the capability for longevity, as long as the DNA is held in cold, dry and dark conditions, as is shown by the study of woolly mammoth DNA from up to 60,000 years ago, and for resistance to obsolescence, as DNA is a universal and fundamental data storage mechanism in biology. These features have led to researchers involved in their development to call this method of data storage “apocalypse-proof” because “after a hypothetical global disaster, future generations might eventually find the stores and be able to read them.” It is, however, a slow process, as the DNA needs to be sequenced in order to retrieve the data, and so the method is intended for uses with a low access rate such as long-term archival of large amounts of scientific data. Scientists can encode vast amounts of digital information onto a single strand of synthetic DNA. In 2012, George M. Church encoded one of his books about synthetic biology in DNA. The 5.3 Mb of data from the book is more than 1000 times greater than the previous largest amount of information to be stored in synthesized DNA. A similar project had encoded the complete sonnets of William Shakespeare in DNA. In March 2017, scientists at Columbia University and the New York Genome Center published a method known as DNA Fountain which allows perfect retrieval of information from a density of 215 petabytes per gram of DNA. The technique approaches the Shannon capacity of DNA storage, achieving 85% of the theoretical limit. Using this method, they were also able to perfectly retrieve an operating system called KolibriOS, the French movie Arrival of a Train at La Ciotat, a $50 Amazon gift card, a computer virus, a Pioneer plaque and a study by Claude Shannon, all with a total of 2.14 megabytes.
______
DNA information stored as digital data on computer:
Each of the 3 billion DNA base pairs in a human genome can be encoded by two bits—750 megabytes for the entire genome. But considerable data about each base is usually collected, and genes are often sequenced many times to ensure accuracy, so it’s common to save around 100 gigabytes when sequencing a human genome with a machine made by industry leader Illumina. Keeping this much data about every person on the planet would require about as much digital storage as was available in the whole world in 2010. The trick, then, will be to save less. Harvard geneticist George Church says that eventually only the differences between a newly sequenced genome and a reference genome will need to be stored. Since individual genomes vary by less than 1% from each other, they can be losslessly compressed to roughly 4 megabytes. So entire human genome information could be stored in as little as 4 megabytes.
_____
_____
Living system to biological machine:
__
Living systems:
Over the long time period of biological evolution, living systems have developed and evolved using key fundamental mechanisms that distinguish them from non-living systems. All life forms are composed of molecules (proteins, lipids, sugars, DNA, RNA) that are, in themselves, non-living. This has led to the conceptually difficult question – how could life have arisen from a collection of non-living molecules? The origin and definition of life poses a number of questions. The widely accepted biochemical definition of life is that localised molecular assemblages are considered to be alive if they are able to continually regenerate, replicate and evolve. Regeneration and replication requires the living system to have the ability to import, process and transform molecules from the environment into cellular aggregates; whereas evolution requires heritable variation in cellular processes. Living systems have all the machinery to achieve these requirements. They store the instructions for life in informational chemical polymers (such as DNA and RNA) and they have metabolic systems that chemically regulate and regenerate cellular components – all of which are be contained within a physical container. The totality of this is a living cell, the simplest form of life. More complex forms of life, like plants and mammals, comprise many cells working together in a coordinated and regulated manner – but at a different scale to molecular or unicellular living systems. The need to define living systems at different physical scales arises from the ability to visualise and interpret living systems at scales from near atomic resolution (10^-9 m); to the sub-cellular (10^-6 m); to the multi-cellular (10^-3 m); to the whole organism (10^-1 m). Such advances have been primarily driven by technology developments in imaging, resulting from interdisciplinary research involving engineers, physical scientists and life scientists. One of the current challenges in bioscience is the need to integrate biological information from different physical scales, whilst simultaneously considering living processes as interconnected systems and networks. Systems biology is the attempt to meet these requirements; it is now driving research and thinking in life sciences.
_
Self-organisation:
One key underlying process that has enabled primitive life to form is the ability of non-living molecules to self-organise. The main chemical principle that allows such self-organisation is the ability of molecules to form non-covalent bonds, i.e. a type of chemical bond that does not involve the sharing of electrons. Such bonds are much weaker than covalent bonds and can be readily made and broken. For example, with just a few chemical building blocks (G, C, A, T), strands of nucleic acids can pair up to form large DNA or RNA molecules – allowing the storage and retrieval of information that is mediated though the formation and breaking of weak hydrogen bonds. The ability to break and reform non-covalent bonds is a key feature of living systems.
Noise:
However ordered the appearance of living systems may be, the biochemical events that underpin such systems are in part random. This leads to the difficult question: how do living systems function and process information when the underlying molecular events are random? This is beautifully illustrated when gene expression is measured in single living cells – as opposed to populations of cells. However reproducible and regular cell population measurements are, single cells often show fluctuations and significant differences in gene expression – suggesting that the molecular events that underpin cellular physiology are in fact stochastic. It is now well established that cells exhibit significant noise in many biochemical processes. This has led to the proposal that noise is an important part of living systems. An example of this can be seen in the generation of errors in DNA replication that lead to mutation, which ultimately drives evolution. This does not fully explain how complex, robust and highly orchestrated cell behaviour is determined by random molecular events. However, living systems are not random – in fact cellular events are highly ordered and precisely regulated, despite the stochastic nature of the molecular events that underpin them. Since living systems have evolved to be highly robust in their behaviour, any biochemical noise within the systems is therefore tolerated as part of the living process.
Feedback and cell signalling:
The regulation and control of biological processes is a major aspect of living systems that allows organisms to be responsive to both their external environment and internal physiological state. The use of feedback in biological regulation has a long history dating back to the work of Eduard Pflüger in the 1870s.The concept of biological feedback has led to various theories and models of physiological homeostasis, pattern formation, metabolic flux and transcriptional self-repression. Underlying these models is a simple feedback loop, where an output from a process can be fed back to the input either positively or negatively. Feedback loops are fundamental processes in electronics and computing. Many signalling processes in biology have now been identified as being analogous to processes in engineering. In biology, the concept of feedback is usefully applied to intracellular signalling systems that propagate specific cellular behaviour. In mammals, it is estimated that there are 3000 signalling proteins and around 50 secondary messengers (usually small chemicals that, together, build hundreds of cell-specific signalling systems). Many signalling molecules have upstream regulators and specific downstream targets which form part of a complex web of interactions, biochemical networks and pathways. These allow living systems to be responsive to their internal and external state. Within this complex network of signalling pathways there exist multiple feedback loops that result in biological outcomes such as oscillations, polarisation, robustness and bi-stability. Biological systems display a large variety of feedback loops including positive and negative, dual negative and dual positive, mixtures of both, and multiple feedback functions.
Biological complexity:
As illustrated above, living systems are often highly complex. The interdependent network of biochemical pathways, transcriptional circuits and spatial temporal signalling poses considerable challenges for researchers aiming to elucidate design principles of living systems. However, the development of technology, such as high-throughput (rapid) DNA sequencing, is providing rich data sets. Many of the analytical and modelling techniques which have been developed in systems biology can be applied to synthetic biology.
_
Living systems are problem-solving systems. Even “simple” bacteria and viruses have solved the problem of surviving in every environment in which life can exist. They inhabit niches that are nearly completely isolated in the depths of the earth or in hyper-dense diverse, competitive communities in top soils or around plant roots. It is extraordinary how robust these organisms can be to changes in their environment. No one appreciates this capability more than biological engineers who have yet to learn to design systems that are similarly flexible yet conserve designed function.
________
Is Living Cell a Machine?
The organism-machine analogy lied at the very heart of the matter. Machine analogies are everywhere in biology today! Molecular biologists speak of protein complexes as ‘molecular machines’; developmental biologists speak of the unfolding of development as the execution of a ‘program’ encoded in the genome; and evolutionary biologists refer to natural selection as an engineer and to adaptations as products of design. “What I cannot create, I do not understand.” This quote of the American physicist Richard Feynman can be also applied to the life sciences. Traditionally, biological research follows the paradigm of pure observation and description: biological matter is examined as it is normally found in nature. However, a mechanistic point of view on biological life has been established in the life sciences due to the knowledge gained from molecular and cell biology. Within that, a cell can be considered as a highly complex factory, which is equipped with “machines” that perform variety of different tasks. Machines can be dismantled and designed. Thus, a new research discipline – the so-called Synthetic Biology, has recently evolved in the life sciences. Within Synthetic Biology, the biological matter shall not only be observed, but also engineered.
_
The main argument against the machine conception of organisms is that an organism is intrinsically purposive whereas machines are extrinsically so. The intrinsic vs. extrinsic purposiveness distinction is meant to encapsulate most (if not all) the major differences between organisms and machines by appealing to what prima facie appears to be their most obvious similarity, namely the fact that they operate towards the attainment of particular ends. However, the key point is that they do so in fundamentally different respects. A machine is extrinsically purposive in the sense that it works/functions towards an end that is external to itself; that is, it does not serve its own interests but those of its maker or user. An organism, on the other hand, is intrinsically purposive in the sense that its activities are directed towards the maintenance of its own organization; that is, it acts on its own behalf. The intrinsic purposiveness of organisms is grounded on the fact that they are self-organizing, self-producing, self-maintaining, and self-regenerating systems. Conversely, the extrinsic purposiveness of machines is grounded on the fact that they are organized, assembled, maintained, and repaired by external agents. An organism maintains its integrity and autonomy as a whole by regulating, repairing, and regenerating its parts, whereas a machine relies on outside intervention not just for its construction and assembly, but also for its maintenance and repair. This is a crucial difference, which underlies why talk of design is appropriate when discussing machines but not organisms, why reductionism suffices as an explanatory strategy in the context of machines but not organisms, and why we speak of machines that malfunction in ways that we don’t about organisms. Organisms, whether conscious of their own existence or not, function and operate in ways that ensure the maintenance of their own organization, and hence the continuation of their own existence. What an organism does (and that includes all the physiological and biochemical reactions that take place within it) ultimately serves the purpose of maintaining its own existence through time. The organism needn’t be aware of this for it to be true. Of course, staying alive is not the only purpose in life. Reproduction is also of central importance, and depending on what branch of biology you specialize in you may be inclined to believe that it is more important. But the fact of the matter is that one can survive without reproducing, but one cannot reproduce without surviving (at least, survive until one can reproduce!). So the challenge of staying alive is the most basic, and most formidable, of all of life’s goals. And for this reason it provides a useful means of distinguishing the biological from the mechanical.
_
Synthetic organisms and living machines:
The difference between a non-living machine such as a vacuum cleaner and a living organism as a lion seems to be obvious. The two types of entities differ in their material consistence, their origin, their development and their purpose. This apparently clear-cut borderline has previously been challenged by fictitious ideas of “artificial organism” and “living machines” as well as by progress in technology and breeding. The emergence of novel technologies such as artificial life, nanobiotechnology and synthetic biology are definitely blurring the boundary between our understanding of living and non-living matter. The rise of digital and biological technologies in the second half of the twentieth century has allowed for novel approaches to artificial forms of life. In vitro fertilization (IVF) allowed the fertilization of a human egg and thereby the production of a human embryo in the lab. Yet, the product of this procedure is still controlled by a natural design and is in that respect not more artificial than a naturally conceived human being. The progress in computer technology has led to the development of disciplines called artificial life (AL) and artificial intelligence (AI). The term “artificial life” usually refers to technologies more related to artificial intelligence than synthetic biology although there are overlaps between AL and synthetic biology, particularly in the field of protocells. Human beings can produce digital “organisms” that reproduce, evolve and learn and thereby develop in unpredictable ways. They have life-like functions, but given that these “organisms” do not exist physically but only in a virtual world, they are so fundamentally different from natural life that there remains a clear boundary between natural life and life-like entities produced by computer technology. Synthetic biology adds a new chapter to the story of human-made life. Synthetic biology is an emerging technology at the interface between biotechnology, chemistry, engineering and computer science. Very different types of outputs, from genetically engineered bacteria to chemically synthesized genomes, to chemically assembled cells or even computer models of an artificial metabolism can all be considered intermediate- or end-products of synthetic biology. This multidisciplinary and multi-approach field has the unifying goal of producing and designing new forms of life (Deplazes 2009). In some respects the IVF and AL approaches are combined in synthetic biology. On the one hand, synthetic biologists use the basic natural mechanisms for their products, which means that they are trying to produce organic cellular structures controlled by a genome. On the other hand, their products should be regulated and controlled by a human design, similarly to computers. Depending on the approach, one or the other aspect (the usage of basic natural mechanisms as in IVF or the control by a human design as in AL) is more prominent. Interestingly, the aim of producing novel types of living organisms in synthetic biology not only implies the production of living from non-living matter, but also the idea of using living matter and turning it into machines, which are traditionally considered non-living. It can be said that synthetic biology as a whole approaches the borderline between living and non-living matter from both sides, the living and the inanimate.
_
Synthetic life:
One important topic in synthetic biology is synthetic life that is created in vitro from biomolecules and their component materials. Synthetic life experiments attempt to either probe the origins of life, study some of the properties of life, or more ambitiously to recreate life from non-living (abiotic) components. Synthetic biology attempts to create new biological molecules and even novel living species capable of carrying out a range of important medical and industrial functions, from manufacturing pharmaceuticals to detoxifying polluted land and water. In medicine, it offers prospects of using designer biological parts as a starting point for an entirely new class of therapies and diagnostic tools. In the area of synthetic biology, a living “artificial cell” has been defined as a completely synthetically-made cell that can capture energy, maintain ion gradients, contain macromolecules as well as store information and have the ability to mutate. Nobody has been able to create such an artificial cell. The first living organism with ‘artificial’ DNA was produced by scientists at the Scripps Research Institute as E. coli was engineered to replicate an expanded genetic alphabet. A completely synthetic genome was produced by Craig Venter, and his team introduced it to genomically emptied bacterial host cells, and allowed the host cells to grow and replicate.
_____
_____
Introduction to synthetic biology:
Humans have been manipulating the genetic code for thousands of years, by selectively breeding plants and animals with desired characteristics. As we have learned how to read and manipulate the genetic code, we have started to take genetic information from one organism and transfer it to another. This process we call genetic engineering, and it has enabled researchers to develop different varieties of plants and animals. One of the most recent advances in genetic engineering is synthetic biology, which combines engineering and biology to design and develop novel organisms not found in nature. Proponents of synthetic biology will tell you that we’ve been playing with genetics since the dawn of agriculture—and that new technologies simply allow us to do so with greater precision, care, and understanding. The bigger issue may be that there aren’t clearly defined regulatory standards for synthetic biology. Drug and food safety regulations can still apply, but that’s mostly about how products created through these studies make their way to market—which is a long way off for most work in the area. Researchers have laid out possible regulatory models, but for now most norms are informal, if they exist at all.
_
An engineer is defined as a person who designs, builds, or maintains engines and machines. Imagine applying the engineering skills to a biological system. Biological life is a beautiful and complex world, and we are still very far from comprehending its origins or purpose. Nevertheless, we now know enough to be able to look at it as we would look at an ensemble of complex microscopic machines made of biological parts and engines. Every living cell is a little world in itself with tightly controlled and regulated mechanisms. Once understood, these mechanisms can be used to improve our quality of life. The beauty of synbio is its applicability to solving different problems of our modern society from bioremediation to sustainable energy production, molecular medicine or material science. Feeding nearly 10 billion people by 2050 while fuelling their cars and clearing up their waste threatens to exhaust the planet’s handling capacity. Synthetic biology may provide at least some of the answer. Scientists have already developed genetically modified crops that can provide higher yields from less land and more resistance to drought, disease and pests. But SB plants perform photosynthesis more efficiently by harvesting light from wider regions of the spectrum, or even capture nitrogen directly from the air so they won’t need nitrogen fertiliser. New microbes are being designed that eat and degrade toxic pollutants or turn agricultural waste into electricity.
_
Synthetic biology combines molecular biology and systems biology with engineering principles to design biological systems and bio-factories. The aim is to create improved biological functions to address current and future challenges. Synthetic biology will change the way we create energy, produce food, optimize industrial processing, and detect, prevent, and cure disease. Through science and engineering, this unique area enables researchers to study, alter, create, and re-create highly complex pathways, DNA sequences, genes, and natural biological systems, in order to understand and answer some of life’s most challenging questions. When leading genomic scientist, J. Craig Venter announced in May 2010 that he’d created the first self-replicating organism with a totally synthetic genome (the genetic material of an organism), it was the first time many people had heard of synthetic biology. Venter did not actually create a synthetic living organism—rather his research team created a synthetic copy of a bacterium’s DNA, which, when transplanted into an organism, took over its operation. Nonetheless it was a giant step for synthetic biology, a cutting-edge area of science that combines engineering with biology to construct living organisms from chemical ingredients, much like electrical engineers build computer chips. Synthetic biology, or synbio, has the potential to fabricate pharmaceuticals, detect toxic chemicals, break down pollutants, fix defective genes, wipe out cancer cells, generate hydrogen for clean fuel, produce biofuels, and much more. In the process of trying to manufacture living systems, scientists can also learn a great deal about natural biological processes. But synbio’s great promise must be weighed against the potential risks it holds for our health and safety, and for the environment.
_
Synbio involves the insertion of synthesized genetic parts (synthesized DNA, RNA or ribosomes, where proteins are built) into living cells to program their inner workings. Over the past decade, advancements in reading DNA (DNA sequencing) and replicating DNA (DNA synthesis) have helped further the progress of synbio research. Unlike genetic engineering, which transplants genes from one living organism into another, synbio actually constructs the new genes or genomes it uses from short strands of synthesized DNA made in a DNA synthesizer from inert chemicals. Synbio can involve natural genes that have been redesigned to be more efficient, natural genes that are revamped to function in a new way or completely new artificial genes—some of which have no counterpart in nature. According to biological weaponry experts Jonathan Tucker and Raymond Zilinskas, synbio has a number of different offshoots. Genome construction and design involves redesigning the genomes of microbes to make them more efficient or enable them to perform new tasks. One variation of this is the development of a simplified microbial genome into which new genes with specific functions can be transplanted to create synthesized organisms with new capabilities. Applied protein design includes modifying the genes that provide the genetic instructions for producing certain proteins—for example, redesigning enzymes to be more efficient, or to better tolerate heat or acidity. Completely new amino acids have been created and introduced into proteins to alter their properties. Microbes are also being engineered to synthesize natural products. Yeast cells have been redesigned to produce a compound called artemisinic acid, which is used to make artemisinin, a drug that treats malaria.
_
DNA, like any other form of information, can be both written and read. For DNA, reading is done by DNA sequencing and writing by gene synthesis. Most of molecular biology over the last decade has focused on reading and analyzing naturally occurring DNA sequences as revealed by massive worldwide sequencing efforts. In contrast, the emerging field of Synthetic Biology aims to write new genetic information, thereby creating designed non-natural genes, proteins, biological processes and organisms. Gene synthesis was conceived as a means of gene acquisition in the 1970s and early 1980s, but was soon overtaken by cloning from libraries and later by PCR. More recently, protein and DNA sequences have become easier to obtain electronically through databases than physically from library clones. At the same time gene synthesis technology has matured. Direct synthesis of genes is rapidly becoming the most efficient way to make functional genetic constructs and enables applications such as codon optimization, making RNAi resistant genes and protein engineering. RNA interference (RNAi) is a biological process in which RNA molecules inhibit gene expression or translation, by neutralizing targeted mRNA molecules. Synthetic Biology is the convergence of molecular biology and engineering principles that is underpinned by increasingly efficient technologies for creating full length genes, operons and even genomes denovo. Codon optimization for heterologous protein expression has been shown to often drastically increase protein expression levels. Central to such efforts is the ability to design the genetic constructs as easily as possible while considering multiple design parameters in parallel. For example, considerations such as codon bias use in the desired expression system, avoidance of mRNA secondary structures, degree of sequence identity to homologs and the presence or absence of specific restriction sites or motifs must all be considered simultaneously.
____
The emerging area of synthetic biology can be described as the design and construction of novel biologically based parts, devices and systems, as well as redesigning existing natural biological systems for useful purposes. It incorporates the principles of engineering (e.g. modularity, abstraction and orthogonality) into classical biotechnology. Just as engineers now design integrated circuits based on the known physical properties of materials and then fabricate functioning circuits and entire processors (with relatively high reliability), synthetic biologists will soon design and build engineered biological systems. Unlike many other areas of engineering, however, biology is nonlinear and less predictable, and much less is known about parts and how they interact. Hence, the overwhelming physical details of natural biology (gene sequences, protein properties, biological systems) must be organized and recast via a set of design rules that hide information and manage complexity, thereby enabling the engineering of multicomponent integrated biological systems. Only when this is accomplished will designs of significant scale be possible. Synthetic biology involves applying the principles of engineering and chemical design to biological systems and includes two closely-related capabilities both of which may have wide utility in commerce and medicine.
- Parts for Design and Assembly.
While the transfer of already existing genes from one cell to another characterized an earlier phase of the field of biotechnology, synthetic biology involves the design, assembly, synthesis, or manufacture of new genomes, biological pathways, devices or organisms not found in nature. These operations are made possible by recent advances in DNA synthesis and DNA sequencing, providing standardized DNA “parts,” modular protein assemblies, and engineering models.
- Re-Design Existing Genes.
A second capability of synthetic biology involves the re-design of existing genes, cells or organisms for the purpose of gene therapy. Modification of existing genes in living animal and human cells is enabled by engineered nucleases such as meganucleases, zinc finger nucleases, transcription activator-like effector-based nucleases, and the CRISPR-Cas system. Progress in this branch of synthetic biology has yielded remarkable therapeutic advances in gene therapy well beyond the achievements of conventional drugs and biologic agents.
_
The Synthetic Biology toolbox is evolving rapidly as molecular biology advances and researchers adapt and adopt tools from diverse fields. These include Design tools (Software and bioinformatics), DNA construction tools (cloning, genome-editing, oligo synthesis etc.), and Diagnostic tools (phenotyping, imaging techniques, transcriptomics, proteomics, and metabolomics). Compared to earlier genetic modification (gene-by-gene) approaches and genome-scale metabolic engineering, Synthetic Biology has the potential to reduce the time and costs involved in creating artificial biosynthetic pathways and/or making new microbial strains for bio-based production of chemicals/ compounds. Synthetic biology uses tools and concepts from physics, engineering, and computer science to build new biological systems. Much of synthetic biology research focuses on reprogramming cells by changing their DNA. Once reprogrammed, cells can take on new, specialized purposes, such as creating sustainable chemicals, next generation materials, or targeted therapeutics.
_
Synthetic biology combines various disciplines:
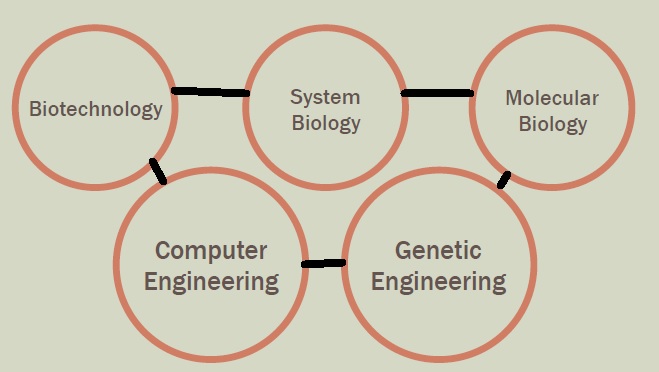
Synthetic biology is an interdisciplinary branch of biology and engineering. The subject combines various disciplines from within these domains, such as biotechnology, evolutionary biology, genetic engineering, molecular biology, molecular engineering, systems biology, biophysics, and computer engineering. Descriptions of synthetic biology depend on how the user approaches it, as a biologist or as an engineer. Originally seen as a subset of biology, in recent years the role of electrical and chemical engineering has become more important. For example, one description designates synthetic biology as “an emerging discipline that uses engineering principles to design and assemble biological components”. Another description, by Jan Staman Director of the Rathenau Institute in The Hague in 2006, portrayed it as “a new emerging scientific field where ICT, biotechnology and nanotechnology meet and strengthen each other”.
_
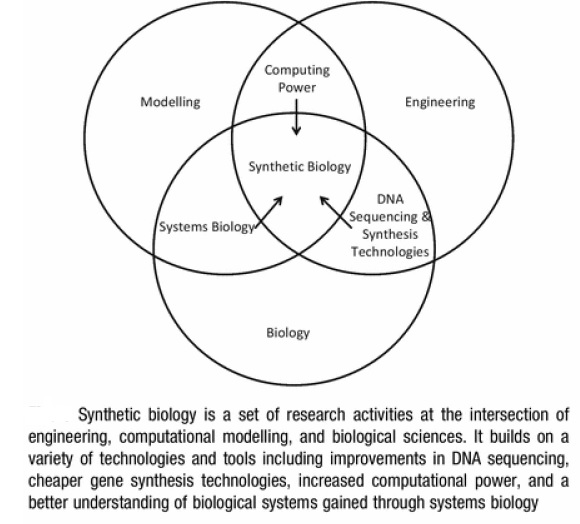
_
Synthetic biology uses the engineering principles of modularity, characterisation (in vitro, in vivo, reference parts under different conditions), and standardisation. Many of the methods and techniques which are used in this context are derived from other fields. Synthetic biology applies knowledge from a variety of disciplines like molecular biology, chemistry, biotechnology, information technology and engineering. Foundational science for synthetic biology includes genomics, structural biology, biochemistry, systems biology, molecular and cell biology, chemical biology, protein engineering and design, and tissue engineering and biomaterials. Platform technology is a suite of tools and methods which can be applied across a range of fields. Standard systems are produced from standard devices that are produced from standard parts (or components, in this case a sequence of DNA with certain characteristics).
_

_______
Definitions of synthetic biology:
The definition of synthetic biology is debated, not only among natural scientists and engineers but also in the human sciences, arts and politics. One popular definition is “designing and constructing biological modules, biological systems, and biological machines for useful purposes.” However, the functional aspects of this definition are rooted in molecular biology and biotechnology. As usage of the term has expanded to many interdisciplinary fields, synthetic biology has been recently defined as the artificial design and engineering of biological systems and living organisms for purposes of improving applications for industry or biological research. This exciting field is evolving so rapidly that no widely accepted definitions exist. Common to many explanations is the idea of synthetic biology as the application of engineering principles to the fundamental components of biology.
_
Below I have listed several of the more commonly referenced definitions:
- Synthetic biology is a) the design and construction of new biological parts, devices and systems and b) the re-design of existing natural biological systems for useful purposes.
- Synthetic biology is an emerging area of research that can broadly be described as the design and construction of novel artificial biological pathways, organisms or devices, or the redesign of existing natural biological systems.
- Synthetic biology is a maturing scientific discipline that combines science and engineering in order to design and build novel biological functions and systems. This includes the design and construction of new biological parts, devices, and systems (e.g., tumor-seeking microbes for cancer treatment), as well as the re-design of existing, natural biological systems for useful purposes (e.g., photosynthetic systems to produce energy).
- Synthetic biology is perhaps best defined by some of its hallmark characteristics: predictable, off-the-shelf parts and devices with standard connections, robust biological chassis (such as yeast and E. coli) that readily accept those parts and devices, standards for assembling components into increasingly sophisticated and functional systems and open-source availability and development of parts, devices, and chassis.
- Synthetic biology is the engineering of biology: the synthesis of complex, biologically based (or inspired) systems which display functions that do not exist in nature. This engineering perspective may be applied at all levels of the hierarchy of biological structures – from individual molecules to whole cells, tissues and organisms. In essence, synthetic biology will enable the design of ‘biological systems’ in a rational and systematic way.
- Synthetic biology is broadly defined as the design and construction of new biological parts, devices and systems that do not exist in the natural world and also the redesign of existing natural biological systems to perform specific tasks systems for useful purposes.
- The deliberate design of biological systems and living organisms using engineering principles.
- The use of computer-assisted, biological engineering to design and construct new synthetic biological parts, devices and systems that do not exist in nature and the redesign of existing biological organisms, particularly from modular parts.
- A field that aims to create artificial cellular or non-cellular biological components with functions that cannot be found in the natural environment as well as systems made of well-defined parts that resemble living cells and known biological properties via a different architecture.
- A new research field within which scientists and engineers seek to modify existing organisms by designing and synthesising artificial genes or proteins, metabolic or developmental pathways and complete biological systems in order to understand the basic molecular mechanisms of biological organisms and to perform new and useful functions.
_
Although there is no universally accepted definition, that provided by the European Commission constitutes a robust framework for understanding synthetic biology.
“Synthetic biology is the application of science, technology, and engineering to facilitate and accelerate the design, manufacture, and/or modification of genetic materials in living organisms to alter living or non-living materials”.
The proposed definition is meant to cover various concepts including standardization, modularization, and refactoring as well as tools such as bioCAD software, metabolic engineering, xenobiology, and automated cloning.
_____
Synbio is inspired by the convergence of nanoscale biology, computing and engineering. Using a laptop computer, published gene sequence information and mail-order synthetic DNA, just about anyone has the potential to construct genes or entire genomes from scratch. It is now possible for a teenager in her basement to create a new species from genetic code using freely available tools on the Internet. A new startup, Arcturus, for example, lets people anywhere engineer microorganisms with a few clicks on their laptop. And the new gene editing tool CRISPR, with its ability to cut and splice genes, is enabling medical work previously impossible, including work towards treating cancer, other diseases and even aging. Naturally occurring biological systems are more complex and difficult to manipulate than anyone imagined 10 or 20 years ago. There are myriad technical problems in getting these systems to act the way we want. With synthetic biology, however, scientists hope to leapfrog these problems. One of synthetic biologists’ hopes is that by building biological systems from the ground up, they can create biological systems that will function like computers or factories, producing the products we want, when we want and in the amounts we want. Scientists also believe that creating these products through synthetic systems will be safer than merely trying to manipulate naturally occurring systems to produce them.
_
There are two types of synthetic biologists. The first group uses unnatural molecules to mimic natural molecules with the goal of creating artificial life. The second group uses natural molecules and assembles them into a system that acts unnaturally. In general, the goal is to solve problems that are not easily understood through analysis and observation alone and it is only achieved by the manifestation of new models. So far, synthetic biology has produced diagnostic tools for diseases such as HIV and hepatitis viruses as well as devices from biomolecular parts with interesting functions. The term “synthetic biology” was first used on genetically engineered bacteria that were created with recombinant DNA technology which was synonymous with bioengineering. Later the term “synthetic biology” was used as a mean to redesign life which is an extension of biomimetic chemistry, where organic synthesis is used to generate artificial molecules that mimic natural molecules such as enzymes. Synthetic biologists are trying to assemble unnatural components to support Darwinian evolution. Recently, the engineering community is seeking to extract components from the biological systems to test and confirm them as building units to be reassembled in a way that can mimic the living nature. In the engineering aspect of synthetic biology, the suitable parts are the ones that can contribute independently to the whole system so that the behavior of an assembly can be predicted. DNA consists of double-stranded anti-parallel strands each having four various nucleotides assembled from bases, sugars and phosphates which are made of carbon, nitrogen, oxygen, hydrogen and phosphorus atoms. In the Watson-Crick model, A pairs with T and G pairs with C although occasionally some diversity exists. This simplification doesn’t exist in proteins. With analysis and observation alone, scientists convince themselves that the paradigms are the truth and if the data contradicts the theory, the data normally is discarded as an error, whereas DNA synthesis encourages scientists to cross into the new land and define new theories. The combination of chemistry, biology and engineering can create artificial Darwinian systems.
_
Synthetic Biology is an engineering discipline and as such needs standard parts that can be put together using bioinformatic and simulation tools to build circuits that will introduce or modify biological functions. This would imply that only projects that involve the use of standardized parts (genes, proteins, circuits…) could be considered proper Synthetic Biology projects. Synthetic Biology can operate at every level, from proteins to organs. Thus, we could consider the 20 amino acids as the standard parts, protein design algorithms and protein structure databases as the simulation and bioinformatic tools, and the resulting newly engineered macromolecule as the new biological function. A similar analogy could be performed at higher levels, with genes and their regulatory transcription factors being the standard parts, cell‐modelling software and databases the simulation, and bioinformatic tools and the resulting modified cell representing the new biological function. Emerging from basic science, well-characterised biological components are provided, from which standard modular parts are constructed. These modular/molecular parts are nucleic acids and proteins, and the aim is to assemble them in a way to predict their behaviour. They are used to design proteins with novel functions, to build genetic circuits (biological parts designed to perform specific logical functions), or synthetic genomes. Redesigning of a system includes transcriptional, translational and post-translational parameters, and standard optimisation and control engineering approaches to find the best parameter choice to achieve a desired objective. Like in other fields of engineering, standard systems can be produced from standard devices, i.e. functional combinations of parts, which, in turn, are produced from standard parts (or components). It becomes clear that standardisation is a key prerequisite to engineering efforts, the results of which are verified by combining simulations and analytical methods. The design and generation of new biological parts for the modular construction of biological genetic systems is a key aspect of synthetic biology. Basic prerequisites for a synthetic biology approach are sufficient data on genes, proteins and metabolites, the decline of costs and increase in efficiency of oligonucleotide synthesis, and the development of precise techniques for studying cellular metabolism. Breakthrough technologies to enable efficient and successful use of synthetic biology are, inter alia, improved DNA synthesis, advances in high-throughput DNA sequencing and large-scale biomolecular modelling of metabolic and signalling networks. Furthermore, detailed knowledge of the host cell (referred to as “chassis”), thorough characterisation of parts, their functional behaviour and compatibility, and the possibility to assemble multiple DNA sequences is necessary.
_
Key aspects of an engineering approach are purpose-orientation, deep insight into the underlying scientific principles, a hierarchy of abstraction including suitable interfaces between and within the levels of the hierarchy, standardization, and the separation of design and fabrication. Synthetic biology investigates possibilities to implement these requirements into the process of engineering biological systems. This is illustrated on the DNA level by the implementation of engineering-inspired artificial operations such as toggle switching, oscillating, or production of spatial patterns. On the protein level, the functionally self-contained domain structure of a number of proteins suggests possibilities for essentially Lego-like recombination which can be exploited for reprogramming DNA binding domain specificities or signalling pathways. Alternatively, computational design emerges to rationally reprogram enzyme function. Finally, the increasing facility of de novo DNA synthesis – synthetic biology’s system fabrication process – supplies the possibility to implement novel designs for ever more complex systems. Some of these elements have merged to realize the first tangible synthetic biology applications in the area of manufacturing of pharmaceutical compounds.
_
Synthetic biology distinguishes itself from other engineering and scientific disciplines in both its approach and its choice of object. This emerging field uses the insights of scientific biological inquiry but formulates new rules for engineering purposes. Synthetic biology should be considered a hybrid discipline, combining elements of both engineering and science to achieve its goal of engineering synthetic organisms. Living systems are highly complex, and we currently lack a great deal of information about how these systems work. One reason is that biological systems possess a degree of integration of their parts far greater than that of non-living systems. Breaking down organisms into a hierarchy of composable parts, although useful as a tool for conceptualization, should not lull the reader into thinking that these parts can be assembled ex nihilo. Because we do not yet know how to confer the properties of life onto an aggregate of physically dynamic, but ‘dead’ material systems, composing artificial living systems requires the use and modification of natural ones. Therefore, assembly of parts occurs in a biological milieu, within an existing cellular context. This has profound implications for the abstraction of biological components into devices and modules and their use in design.
______
______
Core synthetic-biology products:
Synthetic DNA
XNA
Chassis organisms
Synthetic genes
Biobrick parts
Delivery plasmids
Synthetic cells
Production systems
__
Enabling technologies:
DNA sequencing
DNA synthesis and assembly
Genome editing
Bioinformatics and specialty media
Genome Engineering
Microfluidics technologies
Biological components and integrated systems technologies
Pathway engineering
Synthetic microbial consortia
Biofuels technologies
__
Enabled Products:
Pharmaceuticals
Chemicals
Biofuels
Agriculture
Diagnostic tools
Environment
Biomaterial
Research & Development
______
______
Classification of activities in synthetic biology:
- Device fabrication and characterisation
–Input devices: cell surface proteins, sensors, input parts
–Regulatory elements: inverters, logic gates, transcription, translation, phosphorylation, etc.
–Output devices: pathways, etc.
- System design and synthesis
–Developing a hierarchy of parts, devices and systems (standardized)
–Creation of synthetic organisms: top-down, bottom-up. Building gene networks and circuits, programmable systems
–Building artificial cells or compartments, either replicating or not
–Materials and nano-technology
–Developing genomes from using non-natural nucleotides, proteins from non-natural amino acids
–In-cell synthesis of chemicals, materials and biopharmaceuticals
- Enabling Infrastructure
–DNA synthesis and sequencing
–Micro-fluidics
–Protein engineering, directed evolution
–Computer aided design tools: simulation of gene circuits
–Measurement, measurement of noise and variation
_____
_____
Goals of synthetic biology:
Synthetic biologists are working to develop:
- The design of new function vastly more efficient, safe, understandable, and predictable;
- Standardized biological parts — identify and catalog standardized genomic parts that can be used (and synthesized quickly) to build novel biological systems;
- Applied protein design — re-design existing biological parts and expand the set of natural protein functions for new processes;
- Natural product synthesis — engineer microbes to produce all of the necessary enzymes and biological functions to perform complex multistep production of natural products; and
- Synthetic genomics — design and construct a ‘simple’ genome for a natural bacterium.
______
______
Synthetic biology and synthetic genomics:
Synthetic genomics has been defined as the engineering and manipulation of an organism’s genetic material on the scale of the whole genome, based on technologies to design and chemically synthesize pieces of DNA and to assemble them to long, chromosome-sized fragments. These can serve as entire genomes of viruses or bacteria. Compared with traditional genetic engineering, where typically only very few nucleotides or genes in an organism are altered (mostly based on recombinant DNA technology), synthetic genomics thus allows to simultaneously change a large number of nucleotides or gene loci all over the genome by gene synthesis. Since synthetic biology aims to engineer complex biological features and to effectively integrate them into organisms as well as to construct entire, new organisms, the field may increasingly integrate, require and converge with synthetic genomics. In fact, approaches to apply synthetic biology ideas have begun to go far beyond first combinations of very few natural “parts”, for example, to build reporter genes responsive to heavy-metal ions. Increasingly complex gene circuits have been generated, such as those used to detect multiple changes in cancer cells, or computer-modelled, sophisticated non-natural metabolic pathways to produce chemicals and fuels have been constructed. Furthermore, synthetic genomics techniques have been used to reconstruct viruses including polio virus or the virus of the 1918 influenza pandemic, to introduce genome-wide changes for designing vaccine candidates from the poliovirus and influenza viruses, or to generate a first bacterial (Mycoplasma) cell controlled by a chemically synthesized genome upon transplantation into a related recipient cell. More papers include a definition of “synthetic biology” compared to “synthetic genomics”. Following analysis of the two terms, they appear to be interchangeable; no clear difference between them could be found in various publications.
König et al. (2013) tried to differentiate between “synthetic biology” and “synthetic genomics”:
- Synthetic biology is the design and construction of biological components, functions and organisms (that do not exist in nature) and the redesign of existing biological systems (to perform new functions)
- Synthetic genomics encompasses technologies for the generation of chemically synthesised genomes to allow for simultaneous multiple changes to the genetic material of organisms.
Following this depiction, the aims of synthetic biology are to systematically improve existing biological systems and create new ones (Arpino et al. 2013). With this in mind, synthetic biology is characterised by a dual definition, aiming on the one hand to construct new biological parts (e.g. promoters, terminators, open reading frames), devices (combinations of parts) and systems (biological entities, from biological structures to organisms), and on the other hand to re-design existing parts (Porcar and Pereto 2012). To achieve these aims, a specific objective is designed a priori and the functionality for defined inputs and outputs is specified. Synthetic biology seeks to model and construct biological components, functions and organisms that do not exist in nature or to redesign existing biological systems to perform new functions. Synthetic genomics, on the other hand, encompasses technologies for the generation of chemically-synthesized whole genomes or larger parts of genomes, allowing to simultaneously engineer a myriad of changes to the genetic material of organisms. Engineering complex functions or new organisms in synthetic biology are thus progressively becoming dependent on and converging with synthetic genomics. While applications from both areas have been predicted to offer great benefits by making possible new drugs, renewable chemicals or clean energy, they have also given rise to concerns about new safety, environmental and socio-economic risks – stirring an increasingly polarizing debate.
______
______
Synthetic biology vs. genetic engineering:
_
Synthetic biology is genetic engineering 2.0.

Synthetic biology (synbio) is an extreme version of genetic engineering. Instead of swapping genes from one species to another (as in conventional genetic engineering), synthetic biologists employ a number of new genetic engineering techniques, such as using synthetic (human-made) DNA to create entirely new forms of life or to “reprogram” existing organisms to produce chemicals that they would not produce naturally. The difference is in the approach. Whereas genetic engineering projects are usually ad hoc, synthetic biology aims to apply proper engineering principles such as standardisation, modularisation, and reusability. Synthetic biologists create and use libraries of standard parts that are characterised, so they can be easily reused in projects. A part could be a gene, a terminator, a promoter, etc. Synthetic biology also has greater ambitions. The focus is on creating whole systems/circuits of genetic regulation. This means there is a need for computational modelling and understanding of how biological systems work.
_
Rather than constituting a strictly defined field, synthetic biology may be best described as an engineering-related approach to rationally design and construct biological compounds, functions and organisms not found in nature, or to redesign existing biological parts and systems to carry out new functions. It integrates different scientific disciplines, including molecular and systems biology, chemistry, (bio-)physics, computer-aided modelling and design as well as an engineering-based notion of generating and using interchangeable “biological parts” (such as regulatory DNA and RNA elements, or coding sequences for proteins/protein domains) . Compared to “traditional” genetic engineering, which mostly enhances existing biological functions or transfers them between organisms based on the modification or transfer of one or very few genes, synthetic biology work may be characterized as involving the combination of multiple genes, newly constructed “biological parts” or the use of non-natural molecules to enhance traits or to construct new biological pathways and functions – and (in the future) entire organisms. Furthermore, rational design processes are increasingly guided by in silico modelling. However some work from genetic engineering and molecular biology from the last 20-25 years overlaps with today’s synthetic biology concepts of generating new biological parts and systems with new functions. Examples of this are reporter gene systems to indicate water and soil contaminants or gene expression pattern in organisms, as well as conditional gene expression systems for mammalian cells controlled by antibiotics such as tetracycline. Who would deny that they were generated based on the rational combination of “biological parts” with known function (i.e. regulatory DNA-elements and DNA sequences encoding proteins/protein domains) or even by constructing new “parts” (if we think of the hybrid transcriptional regulators made of viral and bacterial protein domains that confer tetracycline-control to mammalian cells) – and that they have generated new functions?
___
For millennia, humans have genetically manipulated species of its interest, like cattle, wolves and boars. Although in most of human history this enhancement of organisms was not done in a lab and the molecular mechanisms were unknown, the essence and result are the same as in modern genetic engineering: improving features of a wild organism by modifying its genome. Nowadays the scientific community refers to genetic engineering as efforts performed by recombinant DNA technologies and molecular cloning. With modern genetic engineering, it is possible to recombine, cut and paste genes from one organism into another target organism. For example, researchers led by Eric Poelscha at the Mayo Clinic engineered mutant domestic cat embryos by inserting the Green Fluorescent Protein isolated from jellyfish into the cat’s genome. This glowing feline was created in the need of a better model organism for the study of the cat’s HIV. This is how genetic engineering is a changing term that nowadays refers to direct lab manipulation of an organism’s genome to improve a specific feature. Synthetic biology, on the other hand, is a much newer term that claims to be a new field within the biological sciences. Similar to genetic engineering, the definition of synthetic biology has also changed over time. The term synthetic biology was first used on genetically engineered bacteria that were created with recombinant DNA technology which was synonymous with bioengineering. Later the term synthetic biology was used as a mean to redesign life. It seems that synthetic biology originated from genetic engineering but nowadays it implies the application of various scientific and intellectual areas. Synthetic biology aims to design and create full genetic systems that can be implemented in an organism in order to perform a self-regulated task. This does not imply just recombining DNA, but designing and modelling a novel pathway by assembling many different pieces of genetic material collected and characterized from natural organisms. For example, Chris Anderson from UC Berkeley has been working on the development of a bacterial system that would be capable of avoiding the immune system, sense tumor cells, and invade and self-destruct after a programed time. Also, synthetic biology pioneer, J. Craig Venter has developed an alga that is capable of producing biofuels from carbon dioxide in the environment, a double win. According to synthetic biologists, organisms like these would be considered new species, unlike the cat with a jellyfish gene, but a complete biological system that could not have evolved from nature and would even have to be classified in a separate domain of life.
_
Fundamental differences between Synthetic Biology and Genetic Engineering:
- Synthetic biology is based on the intentional design of artificial biological systems, rather than on an understanding of natural biology.
- Synthetic biology’s practitioners are not, as a rule, biologists or even molecular biologists. Many are computer scientists or come from disciplines that do not study or work with whole organisms, but instead apply an even more mechanistic, reductionist perspective to living systems than do traditional genetic engineers.
___
Are Synthetically Modified Foods (SMO) the New GMOs?
A technology has just hit the market that brings new questions and concerns to the GMO debate. Synthetic biology, or “synbio,” doesn’t just change the makeup of certain natural entities; it actually grows new organisms that make things more efficiently than nature does. By taking genes from a plant and giving them to yeast, scientists employ the process of fermentation to create the same compound that plant produces. Proponents of synbio tout a long list of benefits. Synbio doesn’t require any land, which means it doesn’t harm the environment the way farming does and isn’t subject to uncontrollable factors like weather. It also doesn’t require any laborers, can be sold at a lower price, and will even have a better taste than the products it replaces. They also claim that each synbio product has undergone rigorous safety testing, and, since they are chemically identical to the natural products they mimic, they can be technically viewed as “natural.” This opens up a big question about synbio products: should they be allowed to be marketed as “natural”? And should products with synbio ingredients be labelled? Critics point out that these products are slipping through a regulatory loophole that allows them to avoid government regulation, safety assessment, and labelling. They argue that consumers don’t know the difference between completely natural and synthetic, and that there needs to be a more transparent process in place to flag when a product uses synbio ingredients.
_
Synthetic vanilla:
The first and only synbio product on the market today is synbio vanillin, an alternative to artificial vanilla flavor. To create this synbio yeast, synthetic DNA is designed on a computer and inserted into the DNA of naturally occurring yeast. This is very different from traditional methods of selectively breeding naturally occurring yeast for various purposes, such as brewing beer or baking bread. In selective breeding, no foreign genetic matter that does not occur naturally in yeast is inserted into the yeast genome. The synbio yeast are fed sugar and biosynthesize vanillin through a fermentation process. The artificial vanilla that most people are used to buying is made from petrochemicals and paper mill waste—not exactly healthy stuff—and so the makers of synbio vanillin see their product as a “natural” alternative. However, you won’t know if you’re eating something that uses it—International Flavors & Fragrances , the company that makes it, isn’t revealing the food companies that use it. In the synbio pipeline are saffron, stevia, the antioxidant reservatrol, and maybe even synbio dairy, which wouldn’t require any cows at all. As this technology rolls out, the questions continue to roll in. What does “natural” really mean? Do consumers deserve to know if their products have been made in a lab? Do we need more assessment of the health impacts of synbio foods? The science is solid, the benefits are big, but the questions are serious.
_
Synthetic antimalarial drug artemisinin:
Synthetic biology has sometimes been called “genetic engineering that works”: using the same cut-and-paste biotechnological methods but with a sophistication that gets results. That definition is perhaps a little unfair because “old-fashioned” genetic engineering worked perfectly well for some purposes: by inserting a gene for making insulin into bacteria, for example, this compound, vital for treating diabetes, can be made by fermentation of microorganisms instead of having to extract it from cows and pigs. But deeper interventions in the chemical processes of living organisms may demand much more than the addition of a gene or two. Such interventions are what synthetic biology aims to achieve. Take the production of the antimalarial drug artemisinin, the discovery of which was the subject of the 2015 Nobel Prize in medicine. This molecule offers the best protection currently available against malaria, working effectively when the malaria parasite has developed resistance to most other common antimalarials. Artemisinin is extracted from a shrub cultivated for the purpose, but the process is slow and has been expensive. (Prices have dropped recently.) Over the past decade researchers at the University of California, Berkeley, have been attempting to engineer the artemisinin-making machinery of the plant into yeast cells so that the drug can be made cheaply by fermentation. It’s complicated because the molecule is produced in a multistep process involving several enzymes that have to transform the raw ingredient stage by stage into the complex final molecule, with each step being conducted at the right moment. In effect this means equipping yeast with the genes and regulating processes needed for a whole new metabolic pathway, or sequence of biochemical reactions—an approach called metabolic engineering, amounting to the kind of designed repurposing of an organism that is a core objective of synthetic biology. Yeast cells have been redesigned to produce a compound called artemisinic acid, which is used to make artemisinin. Artemisinin precursor synthesis in yeast is often called the poster child of synthetic biology—not just because it works (the process is now entering commercial production) but because it has unambiguously benevolent and valuable aims. Creating useful products, advocates say, is all they are trying to do: not some Frankenstein-style creation of unnatural monstrosities but the efficient production of much-needed drugs and other substances, ideally using biochemical pathways in living organisms as an alternative to the sometimes toxic, solvent-laden processes of industrial chemistry. Imagine bacteria and yeast engineered to make “green” fuels, such as hydrogen or ethanol, fed by plant matter and negating the need to mine and burn coal and oil. Imagine easily biodegradable plastics produced this way rather than from oil. Craig Venter, who made his name (and money) developing genome-decoding technologies, has made such objectives a central element of the research conducted at his J. Craig Venter Institute (JCVI) in Rockville, Maryland. Recently scientists at JCVI announced that they have devised ways to engineer microalgae called diatoms, using the methods of synthetic biology, so that they join bacteria and yeast as vehicles for making biofuels and other chemicals.
______
______
Synthetic biology and systems biology:
Systems biology is a discipline that models processes (e.g. regulatory networks), and iteratively tests and improves these models. It emerged from molecular biology, when the progress in automated DNA sequencing and improved computational tools allowed scientists to combine experimentation and computation to reverse-engineer cellular networks. It is an “interdisciplinary approach that attempts to develop and test holistic models of living systems.” Systems biology lays the basis for engineering organisms, i.e. synthetic biology, and includes, inter alia, novel approaches like nanoreactors, attempts to redesign networks and pathways, and includes the synthesis of complete chromosomes. It is based on either a “top-down” systems approach that “uses quantitative modelling to identify and describe the underlying biosynthetic and regulatory networks of a system” or a “bottom-up” approach that “attempts to model the systems-wide phenotypes that emerge from component interactions”. Systems biology studies complex biological systems as integrated wholes, using tools of modelling, simulation, and comparison to experiment. The focus tends to be on natural systems, often with some (at least long term) medical significance. Synthetic biology studies how to build artificial biological systems for engineering applications, using many of the same tools and experimental techniques. But the work is fundamentally an engineering application of biological science, rather than an attempt to do more science. The focus is often on ways of taking parts of natural biological systems, characterizing and simplifying them, and using them as a component of a highly unnatural, engineered, biological system. Systems Biology and Synthetic Biology should be differentiated. While both disciplines consider modelling and simulation as important tools, Systems Biology aims at the quantitative understanding of natural biological systems, and not at the engineering of new functions, or properties. Of course Synthetic Biology benefits enormously from Systems Biology studies, since engineering of a biological system requires at least some understanding of it. On the other hand, Systems Biology benefits enormously from engineering concepts applied to network components (e.g., switches, amplifiers and control elements) and network properties (e.g., robustness and modularity), and such studies have provided invaluable insight into module behavior, while abstracting the details of molecular interactions.
__
Synthetic biology and discovery biology:
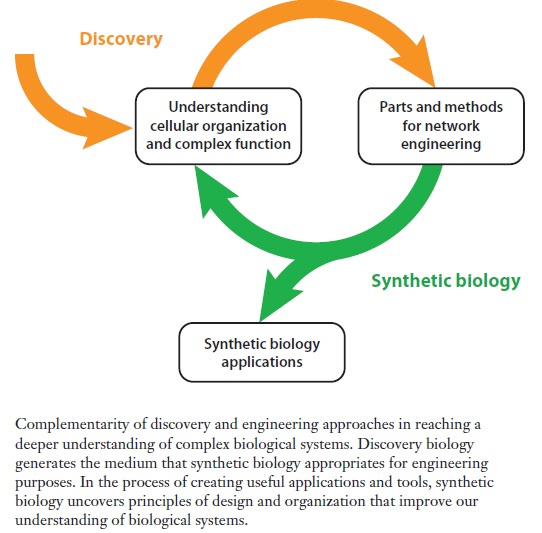
In the future, we foresee a deepening of the relationship between synthetic biology and discovery biology: Advances in discovery biology can be viewed as grist for the biological engineer, while the organizational and functional principles uncovered using synthetic biology will inform and advance discovery. Thus, the flow of information between the two approaches is not unidirectional, but rather a state of cyclical positive feedback.
_
Synthetic biology and biotechnology:
It is also important to differentiate Synthetic Biology from Biotechnology. Thus, improving the production of a certain metabolite by tinkering with some of the components of a metabolic network will fall within the realm of Biotechnology. On the other hand, the introduction of several exogenous enzymes in an organism to produce a new compound will fall within the scope of Synthetic Biology. Many approaches are in the interphase between conventional biotechnology practice and synthetic biology.
_
Synthetic biology and metabolic engineering:
Metabolic engineering may be defined as the optimisation of genomic and regulatory processes within cells and tissues with the aim of increased production of desired substances and/or the reduction of unwanted substances; it can lead to more energy efficient biochemical processes and reduce large-scale production costs. It is about the design, engineering and optimisation of pathways for the production of a variety of products, including fuels, materials and chemicals. As maximising the production of a desired metabolite generally involves quantitative evaluation and adjustment of cellular metabolism, synthetic biology approaches may contribute tremendously to the possible outcomes. Concomitantly, however, it is difficult to draw clear borders between the two disciplines.
_

Figure above illustrates overlap between metabolic engineering and synthetic biology by the use of three different approaches to produce a desirable product. (a) The first approach is a traditional approach in biotech where a naturally producing organism is selected as the cell factory for production of the desirable product. Typically the flux toward the product is naturally low but through the use of classical strain improvement or the use of directed genetic modifications, that is, metabolic engineering, it is possible to increase the flux toward the product. (b) In the second approach, the platform cell factory does not naturally produce the product of interest. Through insertion of a synthetic pathway in the organism (illustrated by the red pathway), the cell factory can produce the product, often in small amounts initially. However, through pathway optimization the flux through this synthetic pathway can be increased to ensure a high flux toward the product. This approach clearly applies concepts from both metabolic engineering and synthetic biology. (c) In the last approach a complete synthetic cell is constructed such that it is dedicated to produce the desirable product.
____
____
History and evolution of synthetic biology:
_
Timeline of synthetic biology evolution:
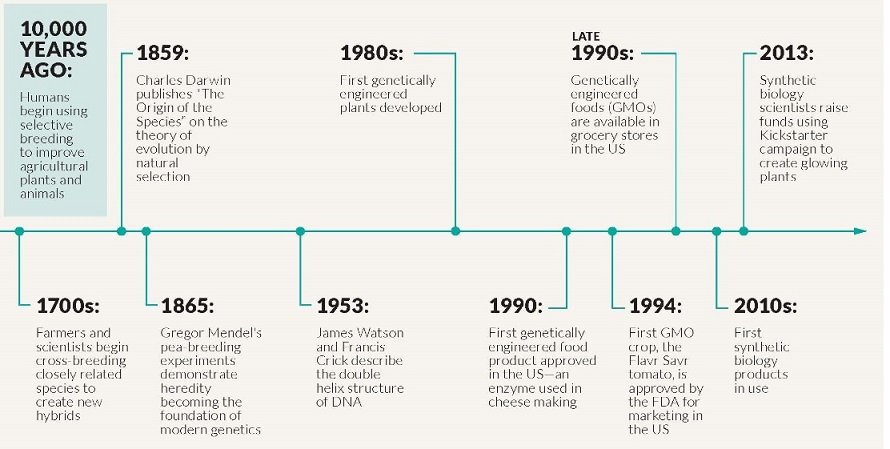
_
The first identifiable use of the term “synthetic biology” was in Stéphane Leduc’s publication of Théorie physico-chimique de la vie et générations spontanées(1910) and his La Biologie Synthétique (1912). Contemporary understanding of synthetic biology was given by Polish geneticist Wacław Szybalski in a panel discussion during Eighteenth Annual “OHOLO” Biological Conference on Strategies for the Control of Gene Expression in 1973 Zichron Yaakov, Israel. When in 1978 Arber, Nathans and Smith won the Nobel Prize in Physiology or Medicine for the discovery of restriction enzymes, Wacław Szybalski wrote in an editorial comment in the journal Gene:
“The work on restriction nucleases not only permits us easily to construct recombinant DNA molecules and to analyze individual genes, but also has led us into the new era of synthetic biology where not only existing genes are described and analyzed but also new gene arrangements can be constructed and evaluated.” A notable advance in synthetic biology occurred in 2000, when two articles in Nature by Michael B. Elowitz and Stanislas Leibler discussed the creation of synthetic biological circuit devices of a genetic toggle switch and a biological clock by combining genes within E. coli cells.
_
In the 1970s, genetic engineering was the hot new technology in which DNA molecules from one organism could be spliced into another organism’s DNA. Today, synthetic biology could likewise revolutionize our way of life. But synthetic biology is orders of magnitude beyond genetic engineering because it can create completely novel DNA sequences. By human “intelligent design,” synthetic biologists could conceivably create new life-forms previously unknown to this planet. The last 10 years have been a time of tremendous improvement in the ease of specific techniques associated with synthetic biology, and this, along with rapidly falling costs and the dispersion of experimental approaches once thought to be the domain of elite biologists, has resulted in the dissemination of synthetic biology widely (among sectors and academic approaches) and deeply (from Nobel Prize winners to high school students).
Recent results of such experiments include:
–The construction of an infectious poliovirus genome from oligonucleotides (short fragments of DNA that are strung together in the laboratory)
–The reconstruction of bacteriophage T7 to simplify its genome (demonstrating that naturally occurring genomes can be systematically redesigned and rebuilt for further research or for specific applications)
–The synthesis of a 582,970-base-pair genome of Mycoplasma genitalium (showing that the full genome of a replicating organism can be constructed in the laboratory)
–Practical application like production of precursor to the malarial drug artemisinin is successful.
Although other biotechnologies could in many cases be applied to essentially the same purposes, the combination of easy access to synthesized DNA, powerful computers to aid design, and the distribution of these technologies to users beyond the “traditional biologist” have raised unique safety and security concerns about synthetic biology. Drew Endy, an assistant professor of biological engineering at MIT, is concerned about these issues. He spoke before a Princeton University audience at a Carnegie Corporation International Peace and Security-sponsored biodefense seminar. He described some of the biological experiments his undergraduate students have done. For example, three freshman and two sophomores reprogrammed the bacterium Escherichia coli to give off the scent of wintergreen while it grew and multiplied and bananas when senescent. It took them about 16 weeks to do this. Endy estimated that as the technology improves, this work will become easier and faster. He argued that humans have altered their environment for years by building structures such as houses and bridges with rocks and other materials. Life-forms could be the logical next step in human engineering. However, one could argue that not all human structures have been beneficial to the overall environment: Dams might provide us with hydroelectric power, but they also severely damage the natural landscape. Engineering new life-forms could have far more devastating consequences because biological ecosystems are interdependent and extremely complex.
_____
_____
Categories and Sub-fields of synthetic biology:
_
Categories of synthetic biology:
O’Malley et al (2008) have defined three broad categories to SynBio: (i) DNA-based device construction; (ii) genome-driven cell engineering and (iii) protocell creation. They suggest that each of these approaches encompasses different views about concepts such as genetic determinism and complexity and each will also give rise to different issues in domains such as intellectual property. Characterising SynBio into these categories offers an opportunity to begin to conceive of its many layers and will be important to any identification, synthesis and normative determination over the ethical issues that will arise. Most importantly, the categories reflect distinctive approaches to biological investigation, which can be characterized in terms of different attitudes towards genetic determinism, cellular context and complexity (in relation to concepts of modularity and emergence).

_
Subfields of synthetic biology:
SB is the design and construction of new biological systems not found in nature. It aims at creating novel organisms for practical purposes but also at gaining insights into living systems by re-constructing them. SB as a scientific and engineering field currently includes the following subfields (Schmidt et al. 2009):
- Engineering DNA-based biological circuits, including but not limited to standardized biological parts;
- Defining a minimal genome/minimal life (top-down approach);
- Constructing so-called protocells, i.e. living cells, from scratch (bottom-up approach);
- Creating orthogonal biological systems based on a biochemistry not found in nature e.g. XNA (Xenonucleic acid);
- Gene and genome synthesis (DNA synthesis).
_________
Today, synthetic biology encompasses several different engineering strategies, including genome design and construction, applied protein design, natural product synthesis, and the construction of functional genetic circuits in cells and microorganisms. Each of these subfields is worth considering briefly.
_
- Genome Design and Construction:
One goal of synthetic biology is to “redesign” the genomes of existing microbes to make them more efficient or program them to carry out new functions. In 2005, for example, Leon Y. Chan and his co-workers at M.I.T. simplified the genome of a bacteriophage (a virus that attacks bacteria but is harmless to humans) called T7 by separating overlapping genes and editing out redundant DNA sequences to facilitate future modifications.
Minimal genomes:
The intention here is to define the minimum number of genetic instructions, genes, needed for an organism to survive. Most of the research has been carried out on bacteria in which genes are progressively eliminated, so revealing those which are essential to life and those which are not. Early estimates put the minimum required number at 500–800 genes, but subsequent work has suggested that it may be as low as 300–400. Using this knowledge it becomes possible to design and build cell factories, the output of which will depend on what additional genes are added to the minimal set required simply to sustain the organism’s existence. The production of minimal genome microbes entails experiments designed to determine the smallest number of genes required for a bacterium to survive and follows the top-down approach to synthetic biology. Craig Venter’s team at the Institute for Genomic Research began to experiment with the bacterium Mycoplasma genitalium in the 1990s. This research built on a survey of the M. genitalium genome using random sequencing [Peterson 1993] and resulted in the estimation of a gene complement of 470 coding regions for such things as DNA repair, energy metabolism and other essential processes [Fraser et al 1995]. This figure was reduced to 386 essential genes by 2005. The production of minimal living genomes is undertaken to produce a ‘chassis’ that can have other synthetic pathways added [ETC 2007], thereby enabling various products to be made from the same basic organism. It is hoped that these basic cells could be utilised for such things as producing efficient fuel alternatives or as a means to slow climate change. A full knowledge of which genes are essential to do what also helps the bioengineer not only to create new and specialised organisms by eliminating unwanted genes, but to build novel organisms from scratch. In the future one might envisage a kind of core genome available off-the-shelf.
Synthetic genomics:
“Synthetic genomics” refers to the set of technologies that makes it possible to construct any specified gene (or full genome) from short strands of synthetic DNA called “oligonucleotides,” which are produced chemically and are generally less than100 base-pairs in length. In August 2002, Eckard Wimmer, a virologist at the State University of New York at Stonybrook, announced that over a period of several months his research team had assembled live, infectious poliovirus from customized oligonucleotides mail-ordered from a commercial supplier, using a map of the viral genome available on the Internet. In 2003, Hamilton Smith and his colleagues at the Venter Institute developed a faster method for genome assembly, using synthetic oligonucleotides to construct a bacteriophage called φX174 (containing 5,386 DNA base-pairs) in only two weeks. Most recently, in 2005, scientists at the U.S. Centers for Disease Control and Prevention synthesized the so-called Spanish influenza virus which was responsible for the 1918-19 flu pandemic that killed between 50 million and 100 million people worldwide. In the near future, synthetic genomics technology should make it possible to recreate any existing virus for which the complete DNA sequence is known. At the same time, the advent of high-throughput DNA synthesis machines will cause the associated costs to drop precipitously, continuing the existing trend. In the year 2000, the price of custom oligonucleotides was about $10 per DNA base-pair; by early 2005, Blue Heron Biotechnology of Bothell, Washington was charging only $2 per base-pair (discounted to $1.60 for new customers). In December 2004, George M. Church of Harvard Medical School and Xiaolian Gio of the University of Houston announced that they had invented a new “multiplex” DNA synthesis technique that Church claims will eventually reduce the cost of DNA synthesis to 20,000 base-pairs per dollar. If his prediction is borne out, it will transform the economics of genome synthesis.
_
- Applied Protein Design:
In the early 1980s, Kevin Ulmer of Genex Corporation conceived the idea of systematically altering the genes that code for certain proteins to achieve desired modifications in protein stability and function. Since then, protein-engineering technology has been applied to develop enzymes that have improved catalytic efficiency or altered substrate specificity, or that can tolerate high temperatures and acidity levels. Today, engineered enzymes are utilized in laundry detergents and in various industrial processes. Another approach to protein engineering involves going beyond the repertoire of the 20 amino-acid building blocks found in nature. For example, a team of chemists headed by Peter G. Schultz at Lawrence Berkeley National Laboratory has expanded the genetic code to specify unnatural amino acids, which can be substituted into proteins to modify their stability as well as their catalytic and binding properties. This technique has made it possible to design protein-based drugs that can resist rapid degradation in the body.
_
- Natural Product Synthesis:
Recombinant-DNA technology has long permitted the replication of single genes in plasmids (small loops of bacterial DNA), a technique known as “molecular cloning,” followed by the expression of the encoded proteins in bacteria or yeast cells. Useful proteins such as human insulin can be produced cheaply with this technique. Now, with the advent of synthetic biology, scientists are engineering microbes to perform complex multi-step syntheses of natural products by assembling “cassettes” of animal or plant genes that code for all of the enzymes in a synthetic pathway. For example, Jay Keasling, a professor of chemical engineering at the University of California, Berkeley, is using synthetic-biology techniques to program yeast cells to manufacture the immediate precursor of the drug artemisinin, a natural product that is highly effective in treating malaria. At present, this compound must be extracted chemically from the sweet wormwood plant, an annual indigenous to China and Vietnam. The extraction of artemisinin is difficult and expensive, however, reducing its availability and affordability in developing countries. Keasling’s group is trying to reduce the cost of the drug by engineering a metabolic pathway for the synthesis of its immediate precursor, artemisinic acid, in yeast. Thus far, the Berkeley researchers have assembled a cassette of several genes from sweet wormwood that code for the series of enzymes needed to make artemisinic acid, and inserted this cassette into baker’s yeast (Saccharomyces cerevisiae). The scientists are now “tuning” the expression levels of each gene so that the entire multi-enzyme pathway functions efficiently. This task is far more complex than traditional experiments involving the cloning and expression of individual genes. Once the engineered yeast cells have been coaxed into producing high yields of the artemisinin precursor, it should be possible to manufacture this compound cheaply and in large quantities by fermentation, a process similar to brewing beer. The same approach could be used to mass-produce other drugs that are currently available in limited quantities from natural sources, such as the anti-cancer drug taxol and the anti-HIV compound prostratin.
_
- Synthetic Biomolecules:
The search for interchangeable parts through protein modification has proven complex due to the secondary and tertiary structural features of these molecules. The modification of amino acid sequences after they have been transcribed from genes in the cell can greatly alter the functionality of the sequence, offering some explanation for the observed discrepancy between low gene number and increased complexity in the higher animals. British scientists [van Kasteren et al. 2007] have recently developed a chemical tagging system that utilises established GM techniques (the LacZ reporter enzyme scaffold) to attach post-translation modifications to amino acid sequences, thereby producing proteins that have functions such as detecting mammalian brain inflammation and disease. Other examples of protein modification include such things as the construction of a synthetic mimic of erythropoietin that has a prolonged circulation time in the body [Kochendoerfer et al 2003].
_
- Creation of Standardized Biological Parts and Circuits:
Perhaps the most ambitious subfield of synthetic biology involves efforts to develop a “tool box” of standardized genetic parts with known performance characteristics — analogous to the transistors, capacitors, and resistors used in electronic circuits — from which bioengineers can build functional devices and, someday, synthetic microorganisms.
_
Modular Components, Pathway Engineering:
Whereas other disciplines in biology are seen to struggle with modelling and describing the complexity of systems, the engineering perspective strips the system to its bare bones and then develops a ‘limited number of well characterized, standardized objects’ [Pleiss 2006], which can be modelled using present computing capacity. These standardized objects, or interchangeable parts [Benner and Sismour 2005], represent a top-down approach to synthetic biology and can be built from first principles, in a hierarchical manner, into complex systems, in which each component and its interactions are known. This predictability means that at every level in the hierarchy in a system, the details of how the components are constructed from parts is irrelevant. Thereby the abstraction of design and fabrication can be accomplished, meaning that complex machines can be developed from a small number of basic modular elements. To achieve this engineering abstraction, research is intensively focused both on the standardization of these interchangeable parts and the decoupling of complex systems into more manageable components [Endy 2005]. This allows for researchers dispersed across the world to collaborate independently.
_
The Synthetic Biology Working Group at M.I.T. is attempting to turn this concept into a reality by developing a comprehensive set of genetic building blocks, along with standards for characterizing their behavior and the conditions that support their use. In the summer of 2004, the group established a Registry of Standard Biological Parts. The registry is made up of components called “BioBricks,” short pieces of DNA that constitute or encode functional genetic elements. Examples of BioBricks are a “promoter” sequence that initiates the transcription of DNA into messenger RNA, a “terminator” sequence that halts RNA transcription, a “repressor” gene that encodes a protein that blocks the transcription of another gene, a ribosome-binding site that initiates protein synthesis, and a “reporter” gene that encodes a fluorescent jellyfish protein, causing cells to glow green when viewed through a fluorescence microscope. A BioBrick must have a genetic structure that enables it to send and receive standard biochemical signals and to be cut and pasted into a linear sequence of other BioBricks, in a manner analogous to the pieces in a Lego set. As of early April 2006, the BioBricks registry contained 167 basic parts, including sensors, actuators, input and output devices, and regulatory elements. Also included in the registry were 421 composite parts, and an additional 50 parts were being synthesized or assembled. Emulating the approach employed by open-source software developers, the M.I.T. group has placed the registry on a public website (http://parts.mit.edu/) and invited all interested researchers to comment on and contribute to it. The ultimate goal of this effort is to develop a methodology for the assembly of BioBricks into circuits with practical applications, while eliminating unintended or parasitic interactions that could compromise the characterized function of the parts. To date, BioBricks have been assembled into a few simple genetic circuits. One such circuit renders a film of bacteria sensitive to light, so that it can capture an image like a photographic negative. In other experiments, BioBricks have been combined into devices that function as logic gates and perform simple Boolean operations, such as AND, OR, and NOT. For example, an AND operator generates an output signal when it gets a biochemical signal from both of its inputs; an OR operator generates a signal if it gets a signal from either input; and a NOT operator (or inverter) converts a weak signal into a strong one, and vice versa. The long-term goal of this work is to convert bioengineered cells into tiny programmable computers, so that it will be possible to direct their operation by means of chemical signals or light.
_
The Synthetic Biology Working Group has realized one of synbio’s main goals: the creation of a “toolkit” of standardized genetic parts with specific characteristics and functions. The Registry of Standard Biological Parts now contains over 15,000 genetic parts (these “BioBricks” consist of short strands of DNA) that can be mixed and matched like Legos to create new synthetic organisms or systems. Catalogued by function, such as the production or degradation of chemicals, killing cells, sensing odors, or intercellular communication, the parts can be ordered from the site by almost anyone. In fact, each year the International Genetically Engineered Machine (iGEM) competition sends undergraduate students toolkits of BioBricks and invites them to submit their creations.
_
- Orthogonal biosystems:
The genetic information that all living systems require to function is stored, in coded form, in the sequence of the four types of sub-unit that go to make up the long chains of their DNA molecules. Researchers have been experimenting with various ways of modifying the system so that it can carry the instructions for making types of protein unknown in nature. Even more radical is the notion of synthesising and using alternatives to DNA to create a new type of genetic material. Any such alternative molecule would need properties comparable to those of DNA – information storage, the ability to self-replicate etc. – and should be able to act in a similar way. Living systems relying on an alternative of this kind might be unable to interact with conventional (DNA-based) life forms. This could have potential safety benefits.
_
- Artificial Cells (protocell):
The creation of artificial cells operates through a bottom-up process, as opposed to the top-down strategies so far described [ETC 2007]. Scientists such as Steen Rasmussen, who was awarded a $5m grant from the Los Alamos National Laboratory, are attempting to build life-like cells from scratch [ETC 2007]. They place three components at the centre of that project: a system of metabolism; an information-storing molecule; and a membrane to hold it together. Rasmussen’s team is developing a protocell. The protocell is different from naturally occurring cells, or minimal living organisms, perhaps most evidently in the use of Peptide Nucleic Acid (PNA) in place of DNA. PNA uses peptides in place of the DNA sugar-phosphate backbone. Rasmussen’s lab is just one of the 13 partners in the PACE (Programmable Artificial Cell Evolution) consortium. This research network aims to produce self-organising, evolvable, life-like systems to make the next generation of self-repairing computer and robotics technologies and to ‘direct all kinds of complex production and remediation on the nanoscale’.
______
______
Top-down and bottom-up approaches of synthetic biology:
Research within synthetic biology can be explored through one of two approaches: top-down, or bottom-up. In the top-down approach, synthetic cells are created by stripping or replacing the genomes of living organisms (cells, bacteria or viruses), reducing their complexity, and only retaining minimum substances to maintain the essential life. In the bottom-up approach, artificial cells are constructed by assembling non-living components to form an integral that can replicate essential properties of natural cells. The behaviour of synthetic biology parts within a particular host has to be defined to render it repeatable (Kitney and Freemont 2012). Numerous genes are involved in cellular communication while others have been shown to be non-essential to cell functioning. It was early suggested that it would be possible to reduce genome complexity to a minimal set of genes able to sustain (under given external conditions) cell life and reproduction. This idea is exploited in the so-called top-down approach. The bottom-up approach starts constructing artificial cell from scratch: a life-like entity is built by assembling of molecular components. These can be of biological nature or instead completely ad hoc chemical components. Between these two approaches is the concept of xenobiology, which aims at the construction of functional alternative nucleic acids (Porcar and Pereto 2012).
_
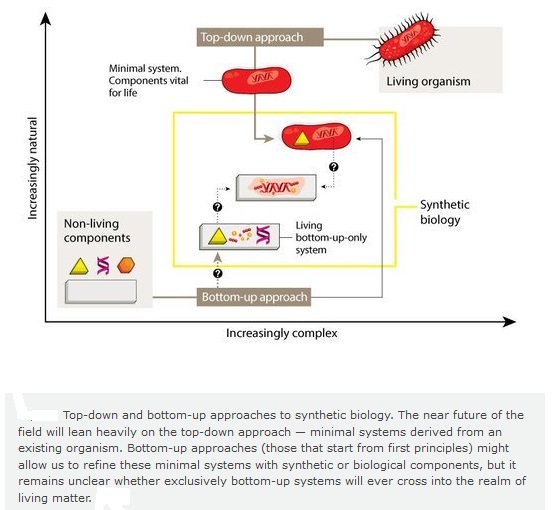
_
Top-down approach:
The top-down approach attempts to eliminate the problem of natural complexity by removing it, e.g. by stripping a genome of all genetic material that is not absolutely essential for replication and functionality. Top-down approach aims at reducing the genome to the minimal set of genes to sustain life under defined conditions. These minimal cells, also termed “chassis”, serve as platform cell factories into which synthetic elements can be added. The preferred platforms are well-studied model organisms like Escherichia coli or yeast, which may also be used as hosts for the expression of plant pathways. Here genetic constitution of existing cells is reprogrammed in order to modify them or even to create a completely new organism. Promising initial achievements in this direction have been reported by the American biochemist Craig Venter and his co-workers in the case of simple bacteria. However, this method requires existing and already functioning, i.e. living organism. Hence, due to the complexity of biological cells, it is more difficult to investigate the basic principles of life by means of the Top-down approach. The top-down approach aims at simplifying already reduced cells to get a “chassis” for synthetic biology devices to be mounted on and has been tried in bacteria and yeast. Non-essential genes – commonly responsible for adaptation to stress or altered environmental conditions – are removed, as are intergenic regions. Specific sequences are removed from an organism, new ones are synthesised in the laboratory and are then transplanted back into the organism. Using this process, the J. Craig Venter Institute have successfully created the first self-replicating synthetic bacterial cell.
_
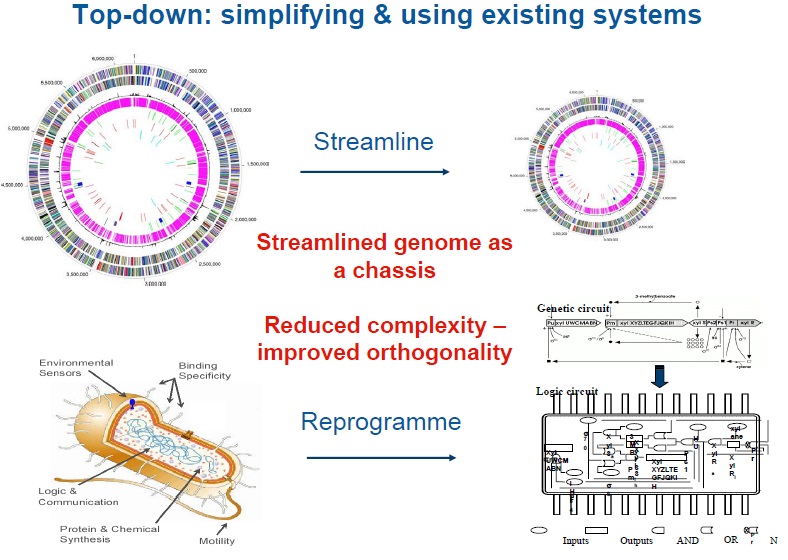
_
A core undertaking in synthetic biology is the “minimal genome” concept, i.e. the minimal set of genes required to allow cellular life, onto which genes can be added and then transplanted into a chassis. The minimal genome contains the simplest possible components to sustain reproduction, self-maintenance and evolution. To develop a core or minimal chassis the genome is reduced to a functionally useful set of genes. The result should be a simple, predictable and programmable chassis that is able to propagate in a safe and controllable manner, including mechanisms preventing unintended release into the environment and ensuring isolation from other organisms. The minimal genome allows avoiding potential risks by, e.g., minimising the potential of cells to propagate under natural environmental conditions and excluding pathogenicity. The aim is to generate simple cellular systems, which may be used to answer scientific questions concerning the systematic interplay of cellular modules.
_
A significant challenge to engineering in biology is the inherent complexity of the cells in which the modified DNA, i.e. the biopart, is embedded in order to produce the desired device or system. It is important that the synthetic device or system is either decoupled from the metabolic processes inherent to the viability of the cell or does not adversely affect these processes. One approach to this problem is to simplify the chassis by reducing the genome and hence the complexity of the chassis. Researchers adopting this approach draw inspiration from refactoring, a process used to streamline computer software without affecting functionality. Oligonucleotides harvested from a photolithographic or inkjet manufactured DNA chip combined with DNA mismatch error-correction allows inexpensive large-scale changes of codons in genetic systems to improve gene expression or incorporate novel amino-acids. The synthetic DNA is optimised for the functionality within the chassis – which is the host for the reaction to take place, whether it is a simple biological switch, an oscillator or a biosensor. The chassis is often referred to as the ’hardware’ in synthetic biology and the synthetic DNA as the software. By far the most common chassis in use today is E. coli. However, there are a number of other natural chassis in use. The most common are listed below, with a brief explanation of each type and an example of their use. In order to successfully use a particular chassis, it is essential to understand in as much detail as possible how it will behave to the presence of synthetic DNA circuits. A key point to understand is that, by definition, chassis are living organisms whose response to the injection of synthetic DNA may be difficult to determine. In addition, for a given set of tasks one type of chassis may perform better than another. One recent example of this is described in the paper published in Science by the J. Craig Venter Institute. This involved the synthesis and reconstruction of a simple bacterium M. genitalium which comprises 589,000 bp. The bacterium was sequenced and then reconstructed. The DNA sequence was divided into cassettes of 24,000 bp and the cassettes were sent to gene synthesis companies (principally Blue Heron and GeneArt) for synthesis. What is important to understand is that the data sent to theses, gene foundries was purely alphanumeric. The cassettes were then synthesised and the DNA returned to the Venter Institute. The cassettes were then reassembled in one eighth and one quarter whole genome sections using E. coli. However, it was found that the half and whole genome could not be reconstructed in E. coli. The Venter Institute scientists discovered that the final reconstruction could be carried out successfully in yeast.
_
Examples of natural chassis:
Listed below are a few of the most common chassis currently in use. As synthetic biology develops the number and type of chassis will inevitably increase as a wider range of applications are catered for.
- Escherichia coli: a bacterium which is normally found in the lower intestine of warm blooded animals. Because E. coli can be grown easily and has relatively simple genetics which can be easily manipulated, non-infective lab-strains can be constructed and it is one of the most common model organisms used in molecular biology. At this time, it is also the most common chassis used in synthetic biology.
- Bacillus subtilis: a non-pathogenic bacterium which is frequently found in soil. Like E. coli, B. subtilis is easily manipulated in relation to genetic changes. It is therefore quite widely used in a range of laboratory studies. It is sometimes used in the place of E. coli because certain of its properties are more amenable to some specific forms of genetic manipulation related to synthetic biology (DNA circuits can be easily integrated into the B. subtilis genome).
- Mycoplasma: a bacterium which does not have a cell wall. In terms of synthetic biology, the most well known form is M. genitalium. This is because (as described above) it was the bacterium which was synthesised by the Venter Institute. Because Mycoplasma tends to be unstable, it is not normally used as a chassis in synthetic biology.
- Yeast: there are large numbers of species of yeast. The species which are mainly used as a chassis in synthetic biology are Saccharomyces cerevisiae. Yeast is widely used in molecular biology, particularly in relation to research on the eukaryotic cell, which links directly into human biology. Yeasts are used as a chassis in synthetic biology and appear to be (under specific circumstances) able to accommodate larger sequences of modified DNA than E. coli.
- Pseudomonas putida: whilst it is sometimes used as a chassis in synthetic biology, its use is nowhere near as common as E. coli, B. subtilis and yeast
_
A chassis derives from a well-known, safe platform cell factory, involving the reconstruction of a completely synthetic pathway and the alteration of metabolic fluxes (Nielsen and Keasling 2011). In industrial production a few fungal and bacterial cell factories are used, e.g. Saccharomyces cerevisiae for the production of fuels, Escherichia coli for producing pharmaceuticals, or Corynebacterium glutamicum for the production of amino acids. Escherichia coli, for example, is an ideal test bed for synthetic biology endeavours because of the already established deep mechanistic understanding of its biology, its ease of genetic manipulation and the relatively large number of well-studied gene regulatory systems .
____
Semi-Synthetic living organism:
Synthia:
_
On June 28, 2007, a team at the J. Craig Venter Institute published an article in Science Express, saying that they had successfully transplanted the natural DNA from a Mycoplasma mycoides bacterium into a Mycoplasma capricolum cell, creating a bacterium which behaved like a M. mycoides. On May 21, 2010, Science reported that the Venter group had successfully synthesized the genome of the bacterium Mycoplasma mycoides from a computer record, and transplanted the synthesized genome into the existing cell of a Mycoplasma capricolum bacterium that had had its DNA removed.
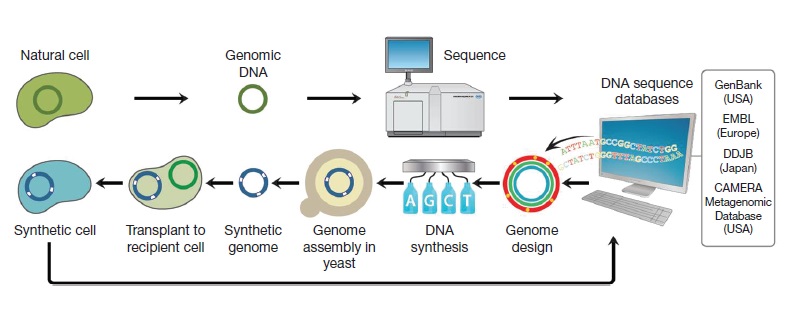
The “synthetic” bacterium was viable, i.e. capable of replicating billions of times. The team had originally planned to use the M. genitalium bacterium they had previously been working with, but switched to M. mycoides because the latter bacterium grows much faster, which translated into quicker experiments. Venter describes it as “the first species…. to have its parents be a computer”. The transformed bacterium is dubbed “Synthia”. Scientists who were not involved in the study caution that it is not a truly synthetic life form because its genome was put into an existing cell.
_
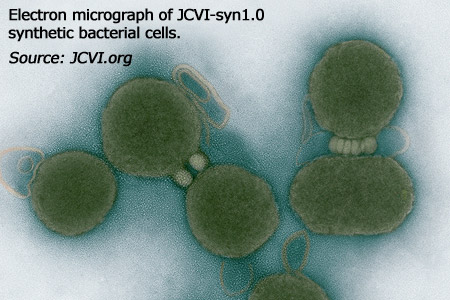
_
In the past few years, the researchers used their in-house technique for whole-genome design and synthesis to reduce the JCVI-syn1.0 initial genome from 1079 to 531 kilobases, corresponding to only 473 genes (and now called JCVI-syn3.0). When the JCVI-syn3.0 was transplanted into a viable cell, it produced polymorphic colonies similar to the one of the original JCVI-syn1.0 genome.
__
Synthetica is a domain of synthetic biologically engineered organisms:
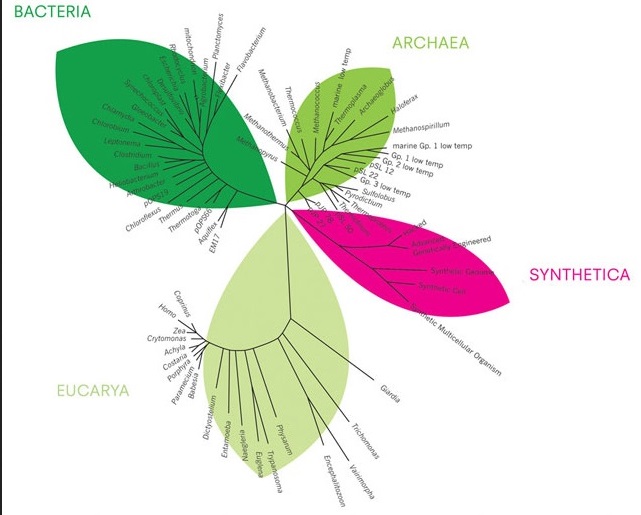
__
__
Prevent spread of genetic information from synthetic cell to natural cell:

_____
Artificial yeast (Saccharomyces cerevisiae) chromosome:
The DNA of eukaryotes—animals, plants, fungi and so on—is both more abundant and more complex than that of prokaryote. It may have hundreds of millions, even billions of letters and it is organised into several elongated chromosomes inside a cell’s nucleus. Synthesising a eukaryote’s genome is thus a far harder task than creating its prokaryote equivalent. But if biology is ever to be brought within the realm of technology in the ways that physics and chemistry have been, it is an essential task. In March 2014, Jef Boeke of the Langone Medical Centre at New York University, published that his team has synthesized one of the S. cerevisiae 16 yeast chromosomes, the chromosome III, that he named synIII. The procedure involved replacing the genes in the original chromosome with synthetic versions and the finished human made chromosome was then integrated into a yeast cell. The first synthetic yeast chromosome (synthetic chromosome 3 or synIII) comprised of 272,871 base pairs. Scientists have made the first artificial chromosome which is both complete and functional in a milestone development in synthetic biology, which promises to revolutionise medical and industrial biotechnology in the coming century. The researchers built the artificial chromosome from scratch by stitching synthetic strands of DNA together in a sequence based on the known genome of brewer’s yeast. The synthetic yeast chromosome was based on chromosome number 3, but scientists deleted large parts of it that were considered redundant and introduced further subtle changes to its sequence – yet the chromosome still functioned normally and replicated itself in living yeast cells. The researchers who have devised artificial yeast chromosome are members of a consortium called the Synthetic Yeast Genome Project (Sc2.0). In March 2017, 6 yeast chromosomes were reported to have been synthesized. They predict that a completely synthetic yeast genome comprised of its entire complement of 16 chromosomes could be made within four years.
_
Synthesis of synthetic chromosome of yeast:
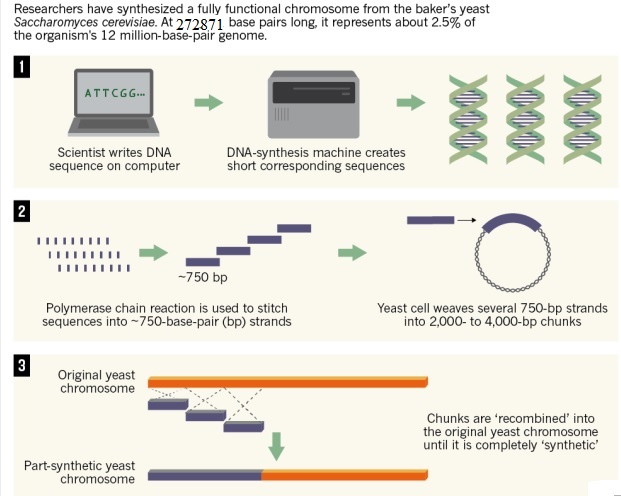
_
Biostudio: Synthetic Biology Software:
The first time geneticist Jef Boeke designed a synthetic chromosome, he sometimes wrote and edited its DNA sequence in a Microsoft Word document. His goal was to create a slightly altered version of yeast chromosome 3. Painstakingly, Boeke went through the code, making changes that he thought would be scientifically interesting or that would make the chromosome more stable. This misery drove him to seek help from student Sarah Richardson in his neighbor Joel Bader’s lab, who wrote scripts to automate some of the most tedious steps. This was the embryonic beginning of what was to become the genome design software called BioStudio. BioStudio allowed Boeke’s team to take the normal yeast genome and make the deletions, insertions, and changes they wanted, making genetic tinkering as easy as cut and paste. The program also includes a version control feature akin to Word’s track changes, recording each edit of the genome so it can easily be reversed if it’s later found to be detrimental to the yeast’s survival. The BioDesign software makes genetic tinkering as easy as cut and paste. Once BioStudio was fully up and running, Boeke’s team designed the full genome of what they call Sc2.0, referencing the scientific name for brewer’s yeast, Saccharomyces cerevisiae. Overall, their Sc2.0 genome design is 8 percent shorter than the original yeast genome, and it includes 1.1 Mb (or roughly a million) changes. While BioStudio has been invaluable for the synthetic yeast project, the researchers aren’t sure whether it will be useful for other synthetic biology projects. If you want to make the kinds of changes they made for yeast, it’s very straightforward but for other types of changes you’d have to write the code.
_____
_____
Bottom-up approach:
Bottom-up synthetic biology broadly falls into two categories: (i) artificial cells, which are newly designed microbes containing entirely synthetic DNA; and (ii) in vitro life, where biochemical reactions placed together can carry out the functions of life and act as artificial cells. Some of the more controversial and thought-provoking topics of synthetic biology and modern science fall into bottom-up category, including the creation of artificial cells and the search for the minimal biological system that can be called life. Ultimately, bottom-up synthetic biology aims to give us new cells that are rationally engineered to act as specialised chassis. These would be more useful to biotechnology than existing natural cells for a variety of reasons.
A few examples of the advantages of artificial cells are:
- Using engineered cells would be more predictable than using natural cells that we don’t fully understand.
- Artificial cells can be engineered to be streamlined for one task only, allowing them to use fewer resources than natural cells.
- Cells constructed from the bottom up can be made dependent on specific conditions, which can be used to prevent them from thriving outside of the desired environment.
_
This approach involves basic building units (parts) that are assembled from pieces of synthesised DNA, and used to design and construct devices (multiple parts with defined functions), pathways and ultimately whole designer genomes. A number of approaches to assemble synthetic genomes have been developed that are based on standardisation of parts to facilitate assembly. In this case the scientists assemble new biomimetic structures that should imitate the functions of biological cells by using biochemical components, such as lipids, proteins and DNA, which are non-living matter. Nowadays, scientists assume that a basic requirement for the origin of life – so to speak the “germ cell” – was the compartmentalization of small spaces. Therefore, one of the first steps is the establishment of very small, semi-permeable compartments in form of manipulable droplets and lipid vesicles. At the same time, a modular “building block” system of the most important components should be composed and installed into the compartments in order to perform cellular functions, such as metabolism and energy production. Thus, by means of the Bottom-up concept, Synthetic Biology becomes independent of microorganisms, which bring along their own evolutionary history, and can also specifically adapt the newly designed structures to the relevant requirements.
_
Organisms are designed from scratch:
BioBricks are pre-made sequences of DNA with specific functions, and are freely available for researchers to order. They can be combined to build more complex sequences, which can then be incorporated into living cells to construct a new genome. This process uses engineering approaches such as the standardisation of parts, to create new biological systems.
_
The main tool here is the computer. Researchers work with the code of existing organisms’ genetic material as essentially a text file, tweaking it, deleting parts, adding parts, adding parts from other organisms, whatever they want. Then they need to take that information and turn it into physical DNA. So they use a DNA synthesis machine that creates actual DNA from the necessary molecules. DNA that has been made by a machine is considered “synthetic DNA.” The researchers have to get that DNA into the organism of choice, and the techniques here can vary depending on the type of cell. DNA, made up of four nucleotide molecules in a sequence, is a code that can be edited and written—not unlike software. The commercialization of DNA sequencing (the reading of an organism’s code) and synthesis (the writing of that code) has accelerated since the mapping of the human genome was completed in 2003. In the past few years new robotics, computational biology, and gene-editing and gene-synthesis technologies have emerged to make synthetic biology efficient and cost-effective. The highly touted Crispr tool, for instance, can snip DNA sequences and insert desired features, while technology from startup Twist Bioscience speeds up gene synthesis by miniaturizing the chemical reaction on silicon. Costs are also falling fast.
_
In molecular biology, the scientific platform for transgenic modification of agricultural plants, takes DNA from genes and rearranges them cuttings of different magazines. However molecular biology is “slow and messy” and you have to experiment to check that your new DNA “message” works to express the desired trait. By contrast, the synthetic biologist designs the desired DNA sequence on a computer, based on knowledge about the sequencing of the whole genome of a simple organism, such as a bacterium. The synthetic biologist specifies the length of the desired genetic sequence in the genome and a specific combination of four bases to transform the computer design into a synthetic DNA sequence. You email your design to a DNA sequencing shop, such as Codon Devices. The shop reads your design, and sequences the DNA with already standardized DNA bits (sometimes call bio-bricks) that have been “cut” by enzymes and mails you your synthetic DNA sequence in a plasmid in a test tube. You are now ready to “play” with the synthetic DNA, for example in a fermentation tank to produce cellulosic biofuels, to see if the in silico computer design “boots up” in vivo in a cellular environment, i.e., whether it lives or doesn’t and if it lives, how the synthetically altered cell mutates. For the bottom-up-approach the whole minimal sequence is compiled from scratch, synthesised and transferred into a suitable cellular casing. After pioneering work in 2007, the approach has been successfully used in Mycoplasma genitalium and Mycoplasma mycoides/Mycoplasma capricolum (Lartigue et al. 2007; Gibson et al. 2008; Gibson et al. 2010). Three major research endeavours may be identified: the large scale synthesis of microbial genomes, the redesign of metabolic pathways (production of desirable compounds), and the rational design of genetic logic devices from modular DNA parts (Agapakis et al. 2012).
_
Protocell:
The artificial cell, built from scratch, is a unique compartment with a structure and an organisation similar to a bacterium. ATP and GTP are used as energy sources in the first stages of the development. For the information part, the synthetic DNA programmes would be expressed with the transcription and translation machineries extracted from an organism. The physical boundary of the artificial cell would be a phospholipid bilayer. Lipid bilayers are also the natural template for membrane proteins. The cell wall, anchored to the lipid membrane, provides the structural strength to the bacterium. The fabrication of a stable compartment with an active interface is one of the most challenging steps in the synthesis of a DNA-programmed artificial cell. The efficient insertion of membrane proteins into the bilayer is the real current limitation to the development of an active interface. Membrane proteins can be also expressed and integrated into phospholipid bilayers. A living organism is an open system made of hundreds of chemical reactions whose properties go beyond the DNA programme. A continuous uptake of energy and a continuous elimination of reaction by-products are critical for any living systems as well as for a synthetic cell. The construction of an artificial cell requires the development of an artificial environment. The external medium has to be an isotonic non-dissipative feeding solution that maintains physiological conditions by exchanges of low molecular mass nutrients, nucleotides and amino acids through the phospholipid membrane. Selective exchanges, osmotic pressure problems, and efficient transcription/translation are among the issues that must be solved to obtain an initial workable microscopic vesicle.
_
Researchers make Artificial Cells that can replicate themselves: a 2015 study:
A team of Japanese biologists has created artificial cells similar to those that might have first existed on Earth to better understand how they might have started to divide and evolve, according to a study published today in Nature Communications. The researchers made a “protocell” made of DNA and proteins packaged inside lipids, which are fatty compounds meant to mimic the cell membrane. These spheres aren’t alive, but the DNA in them contains instructions to replicate under the right conditions. By changing the pH of the spheres’ environment, the researchers were able to trigger the cells to divide. But the hard part was replenishing the spheres’ supplies so that they could start the division process over again, as real cells do. To work around this, the researchers designed the newly split protocells to combine with other cell-like structures nearby. It worked—the spheres had three successful generations in the lab.
_
Synopsis of bottom-up approach:
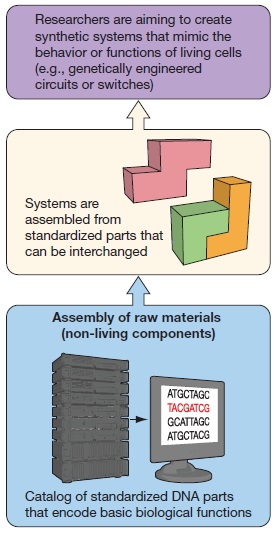
_______
_______
Xenobiology:
Xenobiology describes a form of biology that is not (yet) familiar to science and is not found in nature. In practice it describes novel biological systems and biochemistries that differ from the canonical DNA-RNA-20 amino acid system. For example, instead of DNA or RNA, Xenobiology explores nucleic acid analogue Xeno Nucleic Acid (XNA) as information carriers and novel nucleotides X & Y as unnatural base pair (UBP). It also focuses on an expanded genetic code and the incorporation of non-proteinogenic amino acids into proteins.
_
- Nucleic acid analogue:
Nucleic acid analogues are compounds which are analogous (structurally similar) to naturally occurring RNA and DNA, used in medicine and in molecular biology research. Nucleic acids are chains of nucleotides, which are composed of three parts: a phosphate backbone, a pentose sugar, either ribose or deoxyribose, and one of four nucleobases. An analogue may have any of these altered. Typically the analogue nucleobases confer, among other things, different base pairing and base stacking properties. Examples include universal bases, which can pair with all four canonical bases, and phosphate-sugar backbone analogues such as XNA.
Novel backbone:
Xeno nucleic acid:
Xeno nucleic acid (XNA) is a synthetic alternative to the natural nucleic acids DNA and RNA as information-storing biopolymers that differs in the sugar backbone. In XNA nucleotides, the deoxyribose and ribose sugar groups of DNA and RNA have been replaced. As of 2011, at least six types of synthetic sugars have been shown to form nucleic acid backbones that can store and retrieve genetic information. These substitutions make XNAs functionally and structurally analogous to DNA and RNA, but they also make them unnatural and artificial. XNA exhibits a variety of structural chemical changes relative to its natural counterparts. Types of synthetic ‘XNA’ created so far include 1,5-anhydrohexitol nucleic acid (HNA) and cyclohexene nucleic acid (CeNA), Threose nucleic acid (TNA), glycol nucleic acid (GNA), locked nucleic acid (LNA), and peptide nucleic acid (PNA). Research is now being done to create synthetic polymerases to transform XNA. Although the genetic information is still stored in the four canonical base pairs (unlike other nucleic acid analogues), natural DNA polymerases cannot read and duplicate this information. Thus the genetic information stored in XNA is “invisible” and therefore useless to natural DNA-based organisms.
_
- Novel base pair (X and Y nucleotides):
Unnatural base pair (UBP): expanded genetic alphabet:
_
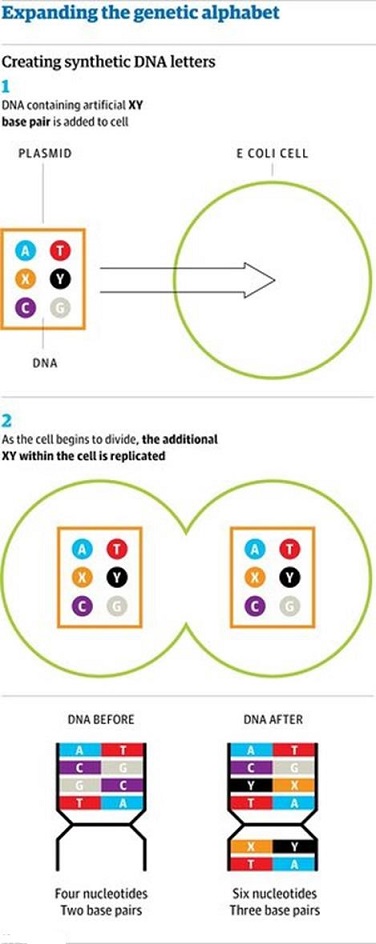
An unnatural base pair (UBP) is a designed subunit (or nucleobase) of DNA which is created in a laboratory and does not occur in nature. In 2012, a group of American scientists led by Floyd Romesberg, a chemical biologist at the Scripps Research Institute in San Diego, California, published that his team designed an unnatural base pair (UBP). The two new artificial nucleotides or Unnatural Base Pair (UBP) are d5SICS and dNaM. More technically, these artificial nucleotides bearing hydrophobic nucleobases, feature two fused aromatic rings that form a (d5SICS–dNaM) complex or base pair in DNA. The Scripps researchers chemically created these two new nucleotides, which they called X and Y. In 2014 the same team from the Scripps Research Institute reported that they synthesized a stretch of circular DNA known as a plasmid containing natural T-A and C-G base pairs along with the best-performing UBP Romesberg’s laboratory had designed, and inserted it into cells of the common bacterium E. coli that successfully replicated the unnatural base pairs through multiple generations. In effect, the bacteria have a genetic alphabet of six letters rather than four, perhaps allowing them to make novel proteins that could function in a completely different way from those created naturally. This is the first known example of a living organism passing along an expanded genetic alphabet to subsequent generations. This was in part achieved by the addition of a supportive algal gene that expresses a nucleotide triphosphate transporter which efficiently imports the triphosphates of both d5SICSTP and dNaMTP into E. coli bacteria. Then, the natural bacterial replication pathways use them to accurately replicate the plasmid containing d5SICS–dNaM. The successful incorporation of a third base pair is a significant breakthrough toward the goal of greatly expanding the number of amino acids which can be encoded by DNA, from the existing 20 amino acids to a theoretically possible 172, thereby expanding the potential for living organisms to produce novel proteins. The artificial strings of DNA do not encode for anything yet, but scientists speculate they could be designed to manufacture new proteins which could have industrial or pharmaceutical uses.
_

_
From the moment life gained a foothold on Earth the diversity of organisms has been written in a DNA code of four letters. The latest study moves life beyond G, T, C and A – the molecules or bases that pair up in the DNA helix – and introduce two new letters of life: X and Y. Romesberg said that organisms carrying his “unnatural” DNA code had a built-in safety mechanism. The modified bugs could only survive if they were fed the chemicals they needed to replicate the synthetic DNA. Experiments in the lab showed that without these chemicals, the bugs steadily lost the synthetic DNA as they could no longer make it.
__
- Novel tRNA encoding non-natural aminoacids (Expanded genetic code):
An expanded genetic code is an artificially modified genetic code in which one or more specific codons have been re-allocated to encode an amino acid that is not among the 20 encoded proteinogenic amino acids.
The key prerequisites to expand the genetic code are:
- the non-standard amino acid to encode,
- an unused codon to adopt,
- a tRNA that recognises this codon, and
- a tRNA synthetase that recognises only that tRNA and only the non-standard amino acid.
Since 2001, 40 non-natural amino acids have been added into protein by creating a unique codon (recoding) and a corresponding transfer-RNA:aminoacyl – tRNA-synthetase pair to encode it with diverse physicochemical and biological properties in order to be used as a tool to exploring protein structure and function or to create novel or enhanced proteins. The incorporated amino acids contain spectroscopic probes, post-translational modifications, metal chelators, photoaffinity labels and unique functional groups. The ability to genetically encode additional amino acids, beyond the common 20, provides a powerful approach for probing protein structure and function both in vitro and in vivo, as well as generating proteins with new or enhanced properties. H. Murakami and M. Sisido extended some codons to have four and five bases. Steven A. Benner constructed a functional 65th (in vivo) codon. In 2017 a mouse engineered with an extended genetic code that can produce proteins with unnatural amino acids was reported.
_____
Note:
Avoid confusion between genetic alphabet and genetic code:
Genetic alphabet means four letters in in DNA (A, T, C and G) and RNA (A, U, C and G). These four letters mean adenine, guanine, cytosine and thymine bases in DNA and adenine, guanine, cytosine and uracil bases in RNA. The genetic code consists of three-letter ‘words’ called codons formed from a sequence of three nucleotides (having three bases from four letter genetic alphabet) which codes for one of 20 natural amino acid or stop signal.
_____
_____
Construction and deconstruction cultures:
Synthetic Biology stands at the meeting-point of two cultures. The first, represented by those interested in ‘deconstructing life’, dissects biological systems in the search for simplified and minimal forms that will help us understand the adaptation and evolution of natural processes. This approach includes experiments to obtain information on isolated parts of biological systems, the simulation of these systems and then the prediction of associated properties followed by further experimental verification. Well-known examples include work on metabolic pathways such as glycolysis (Hans Westerhoff, Free University of Amsterdam) and the simulation of cell systems using stochastic approaches (Luis Serrano, EMBL, Heidelberg). Simplified systems, based on phospholipids (Doron Lancet, Weizmann Institute, Rehovot) or polymers (Steen Rasmussen, Los Alamos National Laboratory), are used to explore possible prebiotic systems. Directly related to this activity is research into minimal forms of life and minimal genomes Tom Knight (MIT Artificial Intelligence Laboratory). An essential part of this approach is the definition of biological systems that make modelling and simulation feasible: biodegradation networks (Alfonso Valencia, National Center of Biotechnology, Madrid), minimal genomes (Andres Moya, Instituto Cavanilles, Valencia), etc. The development of computer viruses (Chris Adami, Santa Fe Institute) to study properties of biological evolution can also be included in this kind of research. In short, this approach focuses on the definition of material or virtual systems that help investigate the properties of complex biological problems.
_
The second, complementary and symmetrical culture is the ‘Construction of life’ approach. In this case, the goal is to build systems that inspired by general biological principles, use biological or chemical components to reproduce the behavior of live systems. Highlights of this kind of approach are the designs of Drew Endy (MIT Department of Biology) and Ron Weiss (Department Electrical Engineering Princeton University) who have started to address biological phenomena with the conceptual weaponry of electrical engineering. The general underlying notion is to combine autonomous, modular, robust and reusable components. Characteristic specimens of this sort are the input components that sense a given environment, such as interfacing with biological signals, internal components, processing of biological input information inside a synthetic system to minimize side-effects, and output components, which send the signal processed by the synthetic setup back to the endogenous biological system. A very attractive and on-going by-product of this research is the development of a registry of Standard Biological Parts, which includes lists of formated components, which, as they comply with international standards, can be easily distributed and shared. The second step will involve the combination of these components into working devices: associated research is seeking to define containers for these machines, which could range from simple lipid vesicles (Peter Walde, ETH; Albert Libchaber, the Rockefeller University) to minimal genomes (Hamilton Smith, Venter Institute).
_
There is a clear difference between the intellectual goals of these two fields. The ‘deconstruction’ community seeks to understand biological systems and their evolution, whereas the ‘construction’ community searches for general design principles regardless of their relationship to actual Biology. Both communities, however, hope that the exploration and/or construction of these (biological) systems will expand our understanding of the organizational principles of living molecular systems, and both are linked by their dependence on very similar theoretical, experimental and computational techniques. This new drive towards ‘construction’ and ‘deconstruction’ of biological phenomena gives a new dimension and adds a new value to traditional research into the origin of life on Earth. Such research, now under the umbrella of Synthetic Biology, was for decades restricted to the field of the Chemistry of prebiotic systems. The body of theories and simulations on primitive, pre-cellular metabolism (Eric Smith, Santa Fe Institute) and on the transitions between living and non-living systems (Steen Rasmussen, Los Alamos National Laboratory; Norman Packard, Protolife Srl) provides a wealth of conceptual and material assets that the new field will be able to build on.
_
Both the ‘deconstruction’ and the ‘construction’ approach generate extremely interesting scientific and technical challenges, among which there are at least two that are likely to influence the future of Computational Biology and Bioinformatics. The first issue is how to synthesize chromosomes containing well-defined functional regions (genes) under clear controllable replication, transcription and translation conditions. This fascinating prospect will require all our skills in analyzing, predicting and designing genome elements, with many implications for genome analysis, comparative genomics and transcription regulation. The second key issue is the modulation of functional specificity. Both newly designed components and those extracted from biological systems require a clear understanding of how they adapt to specific working conditions and how the interactions that determine the properties of stability and adaptation of molecular systems could be engineered. A clear example is the design of Transcription factors able to trigger the activation of specific genes, whether these are designed rationally (Homme Hellinga, Duke University) or obtained by directed evolution (Víctor de Lorenzo, National Center of Biotechnology). Computational analysis of protein families and of protein/DNA structures is, of course, essential for the development of these components. Apart of the instrumental role of Bioinformatics in Synthetic Biology in the design of synthetic chromosomes and components of a desired specificity, there are interesting additional opportunities as well for the development of computational models to analyze, simulate and predict the behavior of artificial and synthetic systems, in what is a new growing field.
_______
_______
Technology of DNA sequencing, cloning, editing and synthesis in synthetic biology:
Biology is following the general footsteps of the computer industry — except in this case, DNA is our programming language. With genome sequencing, we can read DNA, which provides us with lots of important information. Once we read this information, we have to understand what the code is saying. Machine learning and data analysis are helping us in this regard, but writing the code is where it gets most interesting. After all, writing is where we can be creative! In the early days, recombining DNA was slow and difficult. But technology is getting faster, better and cheaper every day. You don’t even need a lab — it’s all gone digital. Software tools combined with CRISPR/Cas9 genome editing technology allow us to do things that were simply impossible to imagine just 15 years ago.
_
Gene editing: CRISPR:
An innovative gene-editing technology known as CRISPR (Clustered Regularly Interspaced Palindromic Repeats) has emerged as a promising technique for gene editing. In 2014, MIT Technology Review touted this gene-editing technology as “the biggest biotech discovery of the century.” At the very least, CRISPR (more formally known as CRISP-Cas9) is the most important innovation in the synthetic biology space in nearly 30 years. Measured against any benchmark — such as the number of patents and scientific publications or the amount of government funding and private sector funding – interest in CRISPR has skyrocketed since 2013. CRISPR is a quick, easy and effective way to edit the genes of any species – including humans. Other methods take months or years, while CRISPR speeds that time up to mere weeks. The ability to cut and splice genes so quickly and so precisely has potential applications for the ability to create new biofuels, materials, drugs and foods within much shorter time frames at a relatively low cost. CRISPR essentially enables researchers to edit the DNA of any species at a precise location. Once you can locate the “interspacers” (the I in CRISPR) separating the “palindromic repeats” (the P and R in CRISPR), you can cut and change genes nearly anywhere in the genome. In the most exciting scenario, CRISPR would make it possible to treat genetic diseases such as sickle-cell anemia and muscular dystrophy. Despite its rather innocuous-sounding name (pronounced “crisper”) and its potential life-changing medical applications, CRISPR has become the center of an intense debate about the future of synthetic biology. Some have called for a global moratorium on the gene-editing technology, due to ethical and safety concerns. From editing microbial DNA in lab test tubes, it’s a slippery slope to editing human DNA in living cells. No one is prepared for an era when editing DNA is as easy as editing a Microsoft Word document.
____
Gene Cloning: DNA cloning:
Molecular cloning refers to the process by which recombinant DNA molecules are produced and transformed into a host organism, where they are replicated. A molecular cloning reaction is typically comprised of the following two components:
- The DNA fragment of interest to be replicated
- A vector/plasmid backbone that contains all of the components for replication in the host
DNA of interest, such as a gene, regulatory element(s), or operon, etc., is prepared for cloning by excising it out of the source DNA using restriction enzymes, copying it using the Polymerase Chain Reaction (PCR), or assembling it from individual oligonucleotides. At the same time, a plasmid vector is prepared in linear form using restriction enzymes or PCR. The plasmid is a small, circular piece of DNA that is replicated within the host, and exists separately from the host’s chromosomal or genomic DNA. By physically joining the DNA of interest to the plasmid vector through phosphodiester bonds, the DNA of interest becomes part of the new recombinant plasmid and is replicated by the host.
___
Why is beta-galactosidase important in synthetic biology?
One of the most important and basic techniques in synthetic biology is gene cloning. In this process, a gene of interest is inserted into a simple quick-growing organism like Escherichia coli so that it produces a desired protein (e.g.: human insulin). This is done by neatly “cutting” a plasmid DNA at certain points using restriction endonucleases and then ligating the also-well-cut gene of interest with the plasmid, so that the two fit in like lock-and-key. However, current methods of transfection, i.e. the process of introducing this recombinant plasmid with the help of a vector (a carrier for the plasmid, such as lentivruses or liposomes) are quite inefficient. This means that not all the E.coli cells will be successfully transformed, so we need a method to detect the ones that have been transformed. To selectively allow only transformed cells to grow, additional genes such as lacZ and ampR are also cloned into the recombinant plasmid. While ampR provides resistance to the antibiotic ampicillin, lacZ codes for a part of the enzyme b-galactosidase. If inserted into the right strain (variety) of E.coli, which already has the genes for the rest of the b-galactosidase protein chain, the entire enzyme can be produced only by all transformed bacteria. So now we know that all the E.coli that have been successfully transformed also carry the ampR and lacZ genes, we can grow them on a medium containing ampicillin and X-gal. The latter ingredient is a substrate for the b-galactosidase enzyme and one of the products of their reaction is a blue colored substance. Thus, successfully transformed bacteria will produce blue colored colonies, and we can then isolate these cultures and mass-produce them to derive our protein of interest (e.g. human insulin).
_____
DNA sequencing (DNA reading):
DNA sequencing is the process of determining the precise order of nucleotides within a DNA molecule. It includes any method or technology that is used to determine the order of the four bases—adenine, guanine, cytosine, and thymine—in a strand of DNA. The advent of rapid DNA sequencing methods has greatly accelerated biological and medical research and discovery. The rapid speed of sequencing attained with modern DNA sequencing technology has been instrumental in the sequencing of complete DNA sequences, or genomes of numerous types and species of life, including the human genome and other complete DNA sequences of many animal, plant, and microbial species. Synthetic biologists make use of DNA sequencing in their work in several ways. First, large-scale genome sequencing efforts continue to provide a wealth of information on naturally occurring organisms. This information provides a rich substrate from which synthetic biologists can construct parts and devices. Second, synthetic biologists use sequencing to verify that they fabricated their engineered system as intended. Third, fast, cheap, and reliable sequencing can also facilitate rapid detection and identification of synthetic systems and organisms.
_
DNA is the predominant information carrier for life. The development of synthetic techniques to construct DNA has led to marked improvements in our ability to understand and engineer biology. For example, despite extensive efforts to unravel the genetic code using molecular genetics, modest capabilities to synthesize nucleic acids ultimately led to the code’s unravelling. Today, reconstructions of complete viral and bacterial genomes are testaments of how far our synthetic capabilities have come. Despite the improvements, our ability to read DNA is better than our ability to write it. Over the last decade, high-throughput sequencing technologies, here referred to as next-generation sequencing (NGS), have revolutionized the discovery and understanding of natural DNA sequence, with current installed capacity estimated at ~15 petabases per year. Large-scale data-sharing initiatives, such as GenBank, and continued improvements in bioinformatics software have made computational analyses on these data easier than ever. Such analyses help generate powerful statistical hypotheses for how genome sequence controls cellular functions across organisms and populations. In addition, NGS-based measurement tools allow for the analysis of many genetic and biochemical processes at unprecedented scale and low cost3. However, even though our ability to both generate hypotheses and measure outcomes has increased in scale owing to NGS, our ability to test such hypotheses experimentally still lags and is among the most limiting steps in the study of natural and engineered biology.
_______
_______
De novo synthesis of DNA:
Oligonucleotides are short DNA or RNA molecules, oligomers, that have a wide range of applications in genetic testing, research, and forensics. Commonly made in the laboratory by solid-phase chemical synthesis, these small bits of nucleic acids can be manufactured as single-stranded molecules with any user-specified sequence, and so are vital for artificial gene synthesis, polymerase chain reaction (PCR), DNA sequencing, library construction and as molecular probes. In nature, oligonucleotides are usually found as small RNA molecules that function in the regulation of gene expression (e.g. microRNA), or are degradation intermediates derived from the breakdown of larger nucleic acid molecules. Oligonucleotides composed of 2′-deoxyribonucleotides (oligodeoxyribonucleotides) are fragments of DNA and are often used in the polymerase chain reaction, a procedure that can greatly amplify almost any small amount of DNA. There, the oligonucleotide is referred to as a primer, allowing DNA polymerase to extend the oligonucleotide and replicate the complementary strand.
_
Progress in large-scale, low-cost construction of desired DNA sequences could rapidly engender progress in both fundamental and applied biological research. Although rapid modification of natural DNA sequence both in vitro and in vivo is useful for a variety of purposes, methodologies for de novo synthesis of DNA from nucleosides confer a number of unique advantages. First, engineering new functions often requires vastly modified or wholly new genetic sequences that are most easily accessed by de novo synthesis methodologies. Second, synthesized constructs are often superior to natural sequence for the study of genetic mechanisms because they can be designed to specifically test hypotheses for how sequence affects function. Finally, sequences that are targeted to be amplified or modified from natural sequences can be difficult to access (for example, from metagenomic data sets); thus, synthesis is the only practical way to experimentally study them.
_
Major advances in DNA synthesis have been central to progress in biotechnology and basic biomedical research. Powerful examples of this progress include elucidation of the genetic code, production of the first synthetic gene, sequencing of the human genome and the widespread uses of PCR. Throughout these applications and many others, the ability to synthesize oligonucleotides typically single strands of DNA 10–80 bases in length, has been an essential enabling technology. This synthetic capacity in turn has bred strong interest in the fabrication of larger constructs, genes and gene circuits, from such synthetic oligonucleotide precursors.
_
Researchers have had the basic knowledge and tools to carry out the de novo synthesis of gene-length DNA from nucleotide precursors for over 35 years. At first, however, these “from scratch” synthesis techniques were extremely difficult, and constructing a gene of just over 100 nucleotides in length could take years. Today, using machines called DNA synthesizers, the individual subunit bases adenine (A), cytosine (C), guanine (G), and thymine (T) can be assembled to form the genetic material DNA in any specified sequence, in lengths of tens of thousands of nucleotide base-pairs using readily accessible reagents. Precisely how a scientist or engineer will obtain the pieces of DNA of interest will vary depending on the resources and preferences of that individual. The most straightforward way to obtain a gene- or genome-length stretch of DNA is to order it from a commercial gene synthesis company. There are at least 24 firms in the United States and at least an additional 21 firms worldwide that provide this service. Many of these firms use proprietary technologies to produce extremely long pieces of DNA; the longest strand reported to date is 52,000 base pairs, synthesized by Blue Heron Biotechnology of Bothell, Washington. Currently, many types of technologies used by firms are proprietary and are not available for purchase by individual users. Alternatively, a scientist may wish to assemble gene- or genome-length DNA on his or her own starting from smaller pieces of DNA called oligonucleotides or oligos. Oligos are sub-gene length stretches, typically from about 15 base-pairs to about 100 base-pairs long. The smaller oligos can be used in laboratories in diagnostic assays and other standard laboratory protocols. The longer oligos, though, from about 40 base-pairs on, can actually be used to construct gene- and genome length DNA.
_
Oligo synthesis:
Oligos can either be ordered from a commercial oligonucleotide manufacturer, or they can be made easily within a laboratory using a specialized machine for that purpose. This can be done on a commercially available oligo synthesizer, a relatively inexpensive, standard piece of equipment that fits easily on a laboratory benchtop. Regardless of the technique used to construct a gene or genome, DNA synthesis technologies offer a much more efficient way to do many of the same things that can be done with standard recombinant DNA or other biochemical or molecular biology techniques. However, the efficiency of modern synthetic DNA technologies together with improved design capabilities offers the potential for revolutionary advances. Synthetic genomics may lead to qualitatively new capabilities, broadening the number of users of biotechnology, and enabling complex applications to be developed by separating higher-level design concepts from the underlying molecular manipulations.
___
Commercial genes or oligos:
Firms throughout the world use synthesis technologies (in many cases proprietary) to make completed, characterized gene- or genome-length DNA for customers. In above example, customers simply enter the desired sequence through a screen interface; about 6-8 weeks later the DNA is delivered.
_
A laboratory-benchtop oligonucleotide synthesizer:

Individual laboratories can buy oligonucleotide synthesizers to generate oligos that can then be manipulated to make a full-length gene or genome. These synthesizers are available commercially from manufacturers such as Applied Biosystems, or may be purchased secondhand on auction sites such as LabX and eBay. These are similar in function to machines used by commercial oligonucleotide synthesis companies. Figure above shows an early DNA synthesis machine and the individual chemicals, including nucleic acids, used to construct sequences. Within the last few years, researchers have developed methods to accurately synthesize increasingly longer segments of DNA and to bring them together into even larger segments of DNA. Stemming from this research, a small industry of commercial DNA synthesis providers has emerged.
_
Gene- and genome-length DNA construction using oligonucleotides:
Oligonucleotides may be purchased or synthesized in a laboratory. They are then subjected to a series of biochemical manipulations that allows them to be assembled into the gene or genome of interest. This example illustrates the construction of the bacteriophage phiX174 (approximately 5500 nucleotides) in about 2 weeks.
__
Gene synthesis:
The fundamental tool of synthetic biology is undoubtedly gene synthesis. Gene syntheses by recombinant DNA cloning and polymerase chain reaction (PCR) are now being rivalled by tour-de-force raw synthesis from oligos. Established polymerase and ligation methods have enabled synthesis of a 7.5-kb virus (Cello et al. 2002), a 5.4-kb virus in 2 wk using biological selection (Smith et al. 2003), a 32-kb operon (Kodumal et al. 2004), and e-mail-order genes. New approaches overcome scalability and cost limitations by avoiding column-based synthesis and gel purification altogether. Thousands of oligos are synthesized on a photo-programmable chip, released, amplified by PCR, enriched for unmutated oligos by hybridization to complementary oligos, and assembled by PCR. Mutations can be further culled by binding to the DNA-mismatch binding protein, MutS, enabling gene syntheses with a 1/10,000 b error rate. Stitching together DNA constructs up to 100-Mb long is feasible via homologous recombination. Chemical synthesis of genome segments without templates (or their hosts) is far more flexible than old approaches. Codons can be globally altered to maximize translation, epigenetic base-modification patterns can be tailored, and totally new protein designs tested. Cell-free assembly and replication of large DNA structures is challenging, but rewarding. PCR is broadly used, but error-prone, confined to products <40 kb, and difficult to integrate with temperature-sensitive biological reactions. More physiological and accurate is strand-displacement amplification of circular DNA into concatameric DNAs using a restriction enzyme and DNA ligase to regenerate monomeric circles. Gibson and colleagues developed both in vivo and in vitro one-step protocols for assembling and cloning oligos directly into plasmid backbones. All of these protocols have been iteratively improved and underlie most academic and commercial gene synthesis efforts. Finally, because oligo synthesis and assembly techniques are prone to errors, gene-length fragments are often cloned and sequence verified, which can substantially add to the final cost. For complete integration with biological systems, an alternative processing scheme that does not require chemical synthesis of oligos is needed. For example, DNA synthesis could be primed by RNA and processing achieved by homologous recombination. The development of DNA synthesis technology has enabled scientists to make entire genes, and, eventually, the complete genome of a microorganism using synthetic methods alone. By synthesizing a complete genome for a bacterial cell and transferring it to a cell with its own genome that was later lost, researchers at the Venter Institute created a self-replicating bacterial cell with entirely chemically constructed DNA.
_
Artificial gene synthesis: DNA printing:
Artificial gene synthesis, sometimes known as DNA printing is a method in synthetic biology that is used to create artificial genes in the laboratory. Currently based on solid-phase DNA synthesis, it differs from molecular cloning and polymerase chain reaction (PCR) in that the user does not have to begin with preexisting DNA sequences. Therefore, it is possible to make a completely synthetic double-stranded DNA molecule with no apparent limits on either nucleotide sequence or size. The method has been used to generate functional bacterial or yeast chromosomes containing approximately one million base pairs. Recent research also suggests the possibility of creating novel nucleobase pairs in addition to the two base pairs in nature, which could greatly expand the genetic alphabet.
_
Cambrian Genomics says that what it calls a DNA printer is essentially a DNA sorter — it quickly spots and collects the desired, tailored stretch of DNA. This trend — which uses the term “print” in the sense of making a bunch of copies speedily — is making particular stretches of DNA much cheaper and easier to obtain than ever before. That excites many scientists who are keen to use these tailored strings of genetic instructions to do all sorts of things, ranging from finding new medical treatments to genetically engineering better crops. The company does that by putting chunks of their DNA on tiny metal beads that emit different colors. That lets a computer scan millions of pieces of DNA to find the right ones. So they just take a picture, change a filter, take a picture, change a filter, take a picture, change a filter. And they read the sequences. It’s basically a high-tech version of a spell-checker. Then Cambrian chooses and “prints” the correct stretch of DNA by firing a computer-controlled laser beam at a glass tray holding millions of these tiny metal beads, each one coated with DNA. The impact of the laser propels the bead carrying the correct DNA into a tray. The DNA laser ‘printer’ is essentially a sorter. It can produce any strand of DNA, made to order.
_
Techniques to assemble synthetic genomes:
DNA synthesis technologies allow creating entire genomes. In synthetic biology, custom-made DNA is used to build larger DNA segments, and groups of these fragments are pieced together into larger fragments that are assembled until the desired DNA product is obtained. There are ligation dependent methods, like BioBrick™ and Golden Gate, and overlap dependent methods to assemble overlapping fragments. Two of the most commonly used methods are BioBricks™ (or standard assembly) and Gibson Assembly®, complemented by other systems like GoldenBraid, which makes use of GBparts (fragments of DNA with four-nucleotide overhangs) as minimal standard building blocks. GoldenBraid has been shown to serve as a modular assembly system in plant synthetic biology. Depending on the size, a range of methods is available, including inter alia BglBricks, CPEC (Circular Polymerase Extension Cloning), Golden Gate, and for larger assemblies sequence-independent overlap methods such as SLIC (Sequence- and Ligation-Independent Cloning), InFusion™, Clontech™, Gibson Assembly®, SLiCE (Seamless Ligation Cloning Extract), and CPEC USER (Uracil-specific excision reagent cloning). So far, in particular TAR (Transformation-Associated Recombination in Saccharomyces cerevisiae) and Gibson Assembly® have proved successful. In contrast to the building of new genomes by DNA synthesis and assembly, alternatively distributed recombineering methods such as MAGE/CAGE and TRMR in Escherichia coli or Green Monster in Saccharomyces cerevisiae are used. To date, these methods are limited to a narrow set of organisms so that a number of metabolic and biological tools may therefore not be worked on.
__
The significant drop in cost of gene synthesis in recent years due to increasing competition of companies providing this service has led to the ability to produce entire bacterial plasmids that have never existed in nature. The field of synthetic biology utilizes the technology to produce synthetic biological circuits, which are stretches of DNA manipulated to change gene expression within cells and cause the cell to produce a desired product. Major applications of synthetic genes include synthesis of DNA sequences identified by high throughput sequencing but never cloned into plasmids and the ability to safely obtain genes for vaccine research without the need to grow the full pathogens. Digital manipulation of digital genetic code before synthesis into DNA can be used to optimize protein expression in a particular host, or remove non-functional segments in order to facilitate further replication of the DNA. Synthesis of DNA also allows DNA digital data storage.
_
Error correction for de novo DNA synthesis:
The availability of inexpensive, on demand synthetic DNA has enabled numerous powerful applications in biotechnology, in turn driving considerable present interest in the de novo synthesis of increasingly longer DNA constructs. The synthesis of DNA from oligonucleotides into products even as large as small viral genomes has been accomplished. Despite such achievements, the costs and time required to generate such long constructs has, to date, precluded gene-length (and longer) DNA synthesis from being an everyday research tool in the same manner as PCR and DNA sequencing. A critical barrier to low-cost, high-throughput de novo DNA synthesis is the frequency at which errors pervade the final product. Error rates have been a significant barrier to the construction of large DNA targets. For example, the 7501 bp poliovirus synthesis was achieved at great cost and required many months, largely due to the multiple iterations of assembly and sequencing needed to yield the correct product. By contrast, a 2703 bp plasmid synthesis and a 5386 bp bacteriophage ϕX174 synthesis were relatively rapid and inexpensive, but required targets which were easily selected for function (such as antibiotic resistance, or a viable genome) and thus are not general to most DNA synthesis goals. Errors in synthetic DNA can come from many sources. The dominant source is the oligonucleotides themselves, i.e. errors arise during oligonucleotide synthesis. These can be of different types. Oligonucleotide synthesis can have average step-wise yields (ASWY) of 99%, i.e. roughly one error introduced per 100 bases. Paradoxically, most PCR-based DNA assembly approaches use these oligonucleotides to build larger products with much better error rates, typically one in 600 bases. This is possible because the principal error in olionucleotide synthesis occurs when a single base monomer is not added successfully to the growing polymer chain. This flawed product is acetylated to terminate further chain growth, and interferes little with gene assembly. Instead, the dominant error observed after gene assembly is a short deletion, most often a single base. This can be traced back to a failure to both couple and then acetylate during oligonucleotide synthesis, or to a failure to deprotect during a given addition cycle. The assembly process also has the potential to introduce errors, such as mistakes made by the polymerases used to amplify the products. Errors can occur once the desired product is replicating within a biological host, such as a plasmid within a bacterium, though these errors are expected at much lower frequency.
_
SynBio Plasmids by Category:
- Cloning and Genomic Tools: plasmids related to cloning and genomic modification, including shuttle, integration, reporter, and tagging vectors.
- Metabolism: plasmids related to metabolic pathways and auxiliary components.
- Networks and Gene Regulation: plasmids containing both naturally occurring and synthetic regulatory elements, including promoters, terminators, repressors, activators, and more. Also contains pre-assembled genetic circuits such as logic gates and higher level gene networks.
- Sensing and signalling: plasmids related to intercellular signalling and environmental sensing.
___
Gene Designer: a synthetic biology tool for constructing artificial DNA segments:
Gene Designer is a stand-alone software for fast and easy design of synthetic DNA segments. Users can easily add, edit and combine genetic elements such as promoters, open reading frames and tags through an intuitive drag-and-drop graphic interface and a hierarchical DNA/Protein object map. Using advanced optimization algorithms, open reading frames within the DNA construct can readily be codon optimized for protein expression in any host organism. Gene Designer also includes features such as a real-time sliding calculator of oligonucleotide annealing temperatures, sequencing primer generator, tools for avoidance or inclusion of restriction sites, and options to maximize or minimize sequence identity to a reference. Gene Designer is an expandable Synthetic Biology workbench suitable for molecular biologists interested in the de novo creation of genetic constructs.
____
____
Carlson curve:
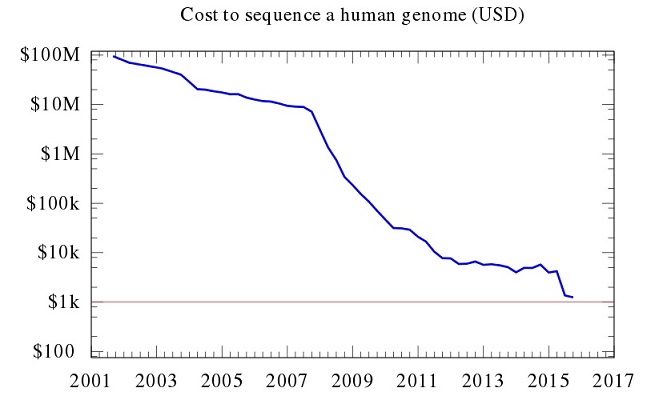
Figure above shows total cost of sequencing a human genome over time.
_
The Carlson curve is a term to describe the rate of DNA sequencing or cost per sequenced base as a function of time. It is the biotechnological equivalent of Moore’s law. Carlson predicted that the doubling time of DNA sequencing technologies (measured by cost and performance) would be at least as fast as Moore’s law. Carlson curves illustrate the rapid (in some cases above exponential growth) decreases in cost, and increases in performance, of a variety of technologies, including DNA sequencing, DNA synthesis and a range of physical and computational tools used in protein production and in determining protein structures.
_
Figure below shows lengths and costs of different oligo and gene synthesis technologies:
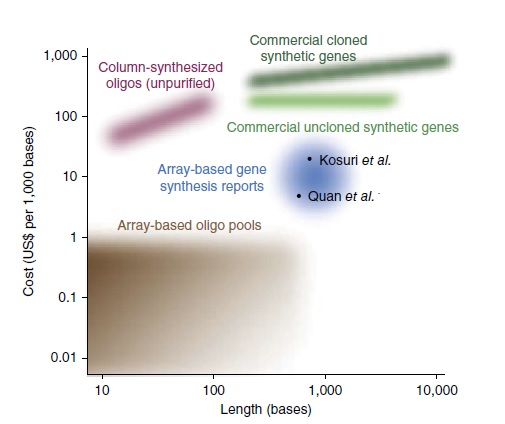
Commercial oligo synthesis from traditional vendors (pink) and array-based technologies (brown) are plotted according to commonly available length scales and price points. Costs of gene synthesis from commercial providers for cloned, sequence-verified genes (dark green) and unpurified DNA assemblies (light green) are shown, as are costs of gene synthesis from oligo pools (blue) derived from academic reports. Driven by dramatic decreases in costs of making oligonucleotides (“oligos”), the sizes of DNA constructions from oligos have increased to the genomic level. For example, in 2000, researchers at Washington University reported synthesis of the 9.6 kbp (kilo base pair) Hepatitis C virus genome from chemically synthesized 60 to 80-mers. In 2002 researchers at SUNY Stony Brook succeeded in synthesizing the 7741 base poliovirus genome from its published sequence, producing the second synthetic genome. This took about two years of work. In 2003 the 5386 bp genome of the bacteriophage Phi X 174 was assembled in about two weeks.
______
______
Synthetic biology, engineering and computer science:
_
According to a mini-history of synbio, by 2008, interdisciplinary teams of biologists, chemists, computer programmers and engineers were asking, “Could synthetic biology evolve into a sophisticated engineering discipline on par with electrical or mechanical engineering? Could practices like parts standardization and abstraction hierarchies be mapped into biological systems?” Their answer is a resounding “yes!” bolstered by numerous examples of bio- “toggle switches,” “autoregulatory circuits,” logic gates and other gene circuitry devices programmed in novel DNA arrangements that one day could be applied to produce novel products.
_
The application of engineering tools such as abstraction, decoupling, and standardization was proposed early in the emergence of synthetic biology to support the efficiency and scaling of the biological system design process. Abstraction (or abstraction hierarchy) is a system for managing biological complexity by eliminating unnecessary details; abstraction allows researchers at various levels (and in various fields) to work with and share details about biological data without specialized knowledge. An abstraction hierarchy that dissects the engineering process into several design levels – DNA, parts, devices, and systems – provides synthetic biologists with a means to manage complexity and distribute tasks. The design process at each abstraction level can be performed relatively independently of the other levels, and detailed information critical to one abstraction level need only be considered by designers operating at that level. This division of labor reduces the amount of information that each designer must be expert in to successfully design a part, device, or system. Decoupling refers to the strategy of partitioning a complicated problem into simpler tasks that can be tackled separately and assembled into a complete solution. The separation of design and fabrication processes is an important example of decoupling supported by advances in design tools and fabrication platforms. The increasing efficiency and decreasing cost of DNA synthesis allow synthetic biologists to design novel systems with the confidence that DNA components can be readily synthesized by commercial sources. Furthermore, advances in DNA sequencing and synthesis provide researchers with access to biological components encoding functions of interest using sequence information deposited in databases, eliminating the need for physical exchange of genetic materials. Standardization takes several forms, including standardization of physical assembly, functional assembly, and characterization/measurements. Re-writers are synthetic biologists interested in testing the irreducibility of biological systems. Due to the complexity of natural biological systems, it would be simpler to re-build the natural systems of interest from the ground up; in order to provide engineered surrogates that are easier to comprehend, control and manipulate. Re-writers draw inspiration from refactoring, a process sometimes used to improve computer software.
_
Figure below shows design principles of Synthetic Biology.
A) Abstraction hierarchy from DNA information to engineered multicellular systems.
B) Modular design allows re-use of components and devices in multiple systems.
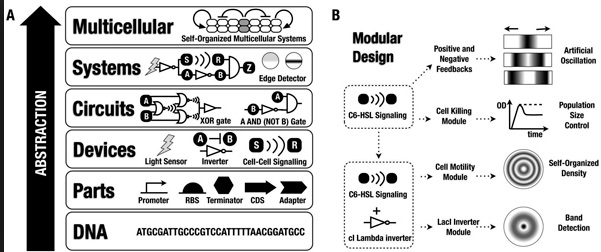
_
When engineering science meets biological science, synthetic biology is created. Over the past half century, systems engineering has seen numerous successful applications in the engineering field such as manufacturing, electronics, telecommunications, computer, and networks, etc. At the same time, biological systems have been dealt in a reductionist way which resulted in accumulation of numerous but relatively fragmented biological information on genes and proteins, and their interactions. With the advent of genomics and other high-throughput technologies, biological paradigm has been shifted to a holistic view on a living system as a whole for understanding of complex life phenomena and living systems and for modification of genes, proteins, metabolites, and other cellular components in order to obtain novel functions/products. As an emerging biological research field, synthetic biology has shown its potential in application of engineering formalisms to design and build functional modules from nucleic acid and protein “parts” and then to integrate such modules into an existing biological systems for novel functions, or to create novel life forms by reconstructing the cellular signalling, regulatory, and metabolic building blocks. The artificially re-designed biological systems may allow for experiments that would be too difficult, if not impossible, to be conducted in their full natural context. Although the ultimate goals are such as the creation of artificial life, so far applications of synthetic biology are typically demonstration of engineering concepts, systematic design, and module assembling in cellular systems (Purnick and Weiss, 2009). The resultant biological parts and modules been designed include switches (Gardner et al., 2000; Kramer et al., 2004), logic gates (Hooshangi et al., 2005), pulse generators (Basu et al., 2004), time-delayed circuits (Weber et al., 2007), oscillators (Stricker et al., 2008), sensors (Basu et al., 2005), and regulators (Zhang et al., 2012). These modules can be used to regulate gene expression, manipulate protein function, modify metabolism, and signal cell–cell communication. On the other hand, care must be taken that different from engineering systems, biological systems are capable of replication, extremely complex in their non-linear network and component interactions, and with less known mechanism for both their basic elements and the whole system.
___
Levels of Engineering:
Here are the Levels of Resolutions that a Synthetic Biologist could focus on.
- Molecular SB-1
- Pathway SB-2
- (intra)cellular SB-3
- (inter)cellular SB-4
- Tissue/organ SB-5
- Multicellular organisms SB-6
- Multiple organism systems SB-7
___
According to the tenets of synthetic biology, living organisms are made up of discrete components that perform in distinctive ways, much in the same way as the functions of transistors and other electronic components can be assembled first into circuits, and then into systems designed to accomplish specific tasks. In synthetic biology, “bioengineers” are developing an inventory of biological parts, which they sometimes refer to as “biobricks,” using chemical ingredients and equipment that are common to any modern biology lab. Like electronic components, the researchers claim, these biobricks—which include genes and chromosomes, as well as proteins that can sense and report activities within a cell—can be assembled and programmed to compel organisms to operate in specific ways, or to produce custom chemicals that can later be “harvested” from cells and sold. Both the discipline and the budding industry of synthetic biology are made possible by two concurrent technological trends. One trend is the increased power, sophistication and availability of technologies for sequencing genomes and for synthesizing and assembling DNA molecules into long strings of functional genes and genomes. The second trend is the rapidly decreasing cost of these powerful technologies. The productivity of sequencing technologies has increased 500-fold over the past 10 years, and is doubling every 24 months. At the same time, costs have declined from $1 to less than $.001 for each base pair sequenced. Similarly, the productivity of DNA synthesis technologies has increased by a factor of 700 over 20 years, doubling every 12 months. The accuracy of the synthesis process has increased as well, while costs have dropped from $30 per base pair to less than $1 over the same period. These advances in automated processes and improved chemistry have made it possible to make large quantities of a wide range of moderate-length DNA sequences. The process is now so easy to do that many suppliers accept orders for custom DNA sequences over the Internet and deliver them by mail. These advances have catalyzed an industry of low-cost DNA suppliers around the globe.
_
It is useful to apply many existing standards for engineering from well-established fields, including software and electrical engineering, mechanical engineering, and civil engineering, to synthetic biology. Methods and criteria such as standardization, abstraction, modularity, predictability, reliability, and uniformity greatly increase the speed and tractability of design. However, care must be taken in directly adopting accepted methods and criteria to the engineering of biology. We must keep in mind what makes synthetic biology different from all previous engineering disciplines. The insight gained from fully appreciating these differences is critical for developing appropriate standards and methods. Building biological systems entails a unique set of design problems and solutions. Biological devices and modules are not independent objects, and are not built in the absence of a biological milieu. Biological devices and modules typically function within a cellular environment. When synthetic biologists engineer devices or modules, they do so using the resources and machinery of host cells, but in the process also modify the cells themselves. A major concern in this process is our present inability to fully predict the functions of even simple devices in engineered cells and construct systems that perform complex tasks with precision and reliability. The lack of predictive power stems from several sources of uncertainty, some of which signify the incompleteness of available information about inherent cellular characteristics. The effects of gene expression noise, mutation, cell death, undefined and changing extracellular environments, and interactions with cellular context currently hinder us from engineering single cells with the confidence that we can engineer computers to do specific tasks. However, most applications or tasks we set to our synthetic biological systems are generally completed by a population of cells, not any single cell. In a synthetic system, predictability and reliability may be achieved in two ways: statistically by utilizing large numbers of independent cells or by synchronizing individual cells through intercellular communication to make each cell more predictable and reliable. More importantly, intercellular communication can coordinate tasks across heterogeneous cell populations to elicit highly sophisticated behavior. Thus, it may be best to focus on multicellular systems to achieve overall reliability in performing complex tasks.
_
There are two basic concepts that you need to understand if you wish to be able to engineer biological systems: how information flows in biological systems and how this information flow is controlled. With an understanding of these concepts one can, in principle, apply engineering principles to the design and building of new biological systems: what we call synthetic biology. Biology is, of course, highly complex and there are important differences that distinguish it from other engineering disciplines. Firstly, biology is not programmed on a printed circuit board, so interactions cannot be programmed by their physical position; rather interactions are based on interactions between molecules that occur in the complex milieu of the cell. Secondly, biology is subject to natural selection, so that modifications which are deleterious to the cell will be selected against and competed out of the population. These evolutionary pressures are not applicable when building an aircraft, and so new definitions of robustness are relevant to biology. Other concepts such as complexity and emergent behaviour may be familiar to engineers, but one must be aware of how they can arise in biology and what their effects may be. Additionally biological systems have the capacity to replicate and to evolve. This fundamental characteristic will interfere at least with the long-term stability of a number of designed systems and will require constant monitoring of the integrity (of crucial parts) of the systems. As the ultimate goal will be to build complex systems into specific hosts, it is likely that interference from mutations becomes a serious issue. However, it is important to point out that the problem as such is not new to biotechnology – rather, it has accompanied every major strain development effort in industrial fermentation and has contributed to the development of appropriate selection programs for sufficiently stable strains and suitable strain storage routines. Engineers’ efforts in the field of engineering biology are furnished with only a few success stories. This reflects the fact that the ability to engineer biology in a directed and successful manner is still rather limited today and as a consequence, the complexity of things we can efficiently make is still quite small. Synthetic biology with its engineering vision aims to overcome the existing fundamental inabilities in system design and system fabrication, by developing foundational principles and technologies to ultimately enable a systematic forward-engineering of (parts of) biological systems for improved and novel applications as seen in the figure below:
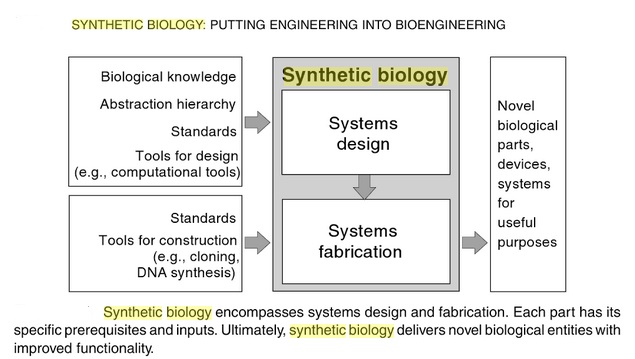
_
Technological systems of staggering complexity, such as digital computers, power grids and the Internet, have become such an integral part of our lives that we take them for granted. Their success owes, in large measure, to the modular design strategy that engineers use to deal with escalating levels of complexity and conflicting requirements. A large system is typically designed by using a ‘top-down’ approach: the problem is divided into a hierarchical set of smaller sub-problems for which it is easier to design and implement smaller subsystems using existing and well-characterized modules that solve these sub-problems. The task is complete when the overall design has been successfully tested and verified, to guarantee that the system performs according to the specifications to which it was designed. If the design is not modular and hierarchical, verification rapidly becomes intractable. Unfortunately, it is not always clear what constitutes a module in biological systems, nor how modules can be interconnected. One way to define a modular structure in natural genetic circuits is through ‘network motifs’, interaction patterns that occur frequently in complex networks and that could be associated with particular functionalities. Such motifs can range in scale from localized bimolecular interactions to complete pathways, such as linear cascades or coherent and incoherent feed-forward loops. Although various algorithms have been developed to identify such motifs in protein–protein and genetic networks in Escherichia coli and Saccharomyces cerevisiae, the relationship between network motifs and the dynamic functionality of the whole network is still unclear. This conceptual gap needs to be resolved if we are to use natural modules systematically to redesign predictable and robust synthetic organisms. It is therefore not surprising that the first synthetic systems used simpler configurations, rather than adaptations of more complex biological networks, to achieve a particular functionality. Instead, those constructions were based on classical engineering design principles (Table below).
_
Engineering, natural and synthetic solutions for designing complex systems:
| Design challenge | Engineering solution | Natural organism | Synthetic biology solution |
| Scalability | Modularity | Motifs Modularity? | Modularity
Well-characterized modules |
| Retroactivity/cross-talk | Insulation and feedback | Feedback | Orthogonal design |
| Robustness | Feedback | Feedback | Feedback |
| Complexity | Hierarchical design | ? | Hierarchical design |
| Evolution/mutation | ? | Efficiency/robustness trade-off | ? |
_
Part of the success of synthetic biology to date has depended on a measure of modularity, through the creation of a standard library of parts, that enables a ‘plug-and-play’ framework for biological circuits. The idea is to develop a library of standardized genetic modules with specific functionality that can be combined to achieve a certain function, analogous to binary transistor logic libraries used by electrical engineers. The Massachusetts Institute of Technology (MIT) Registry of Standard Biological Parts is one the most popular example (http://partsregistry.org/).
___
Hierarchy for synthetic biology is inspired by computer engineering:
The goal of synthetic biology is to extend or modify the behavior of organisms and engineer them to perform new tasks. One useful analogy to conceptualize both the goal and methods of synthetic biology is the computer engineering hierarchy as seen in the figure below. Within the hierarchy, every constituent part is embedded in a more complex system that provides its context. Design of new behavior occurs with the top of the hierarchy in mind but is implemented bottom-up. At the bottom of the hierarchy are DNA, RNA, proteins, and metabolites (including lipids and carbohydrates, amino acids, and nucleotides), analogous to the physical layer of transistors, capacitors, and resistors in computer engineering. The next layer, the device layer, comprises biochemical reactions that regulate the flow of information and manipulate physical processes, equivalent to engineered logic gates that perform computations in a computer. At the module layer, the synthetic biologist uses a diverse library of biological devices to assemble complex pathways that function like integrated circuits. The connection of these modules to each other and their integration into host cells allows the synthetic biologist to extend or modify the behavior of cells in a programmatic fashion. Although independently operating engineered cells can perform tasks of varying complexity, more sophisticated coordinated tasks are possible with populations of communicating cells, much like the case with computer networks.
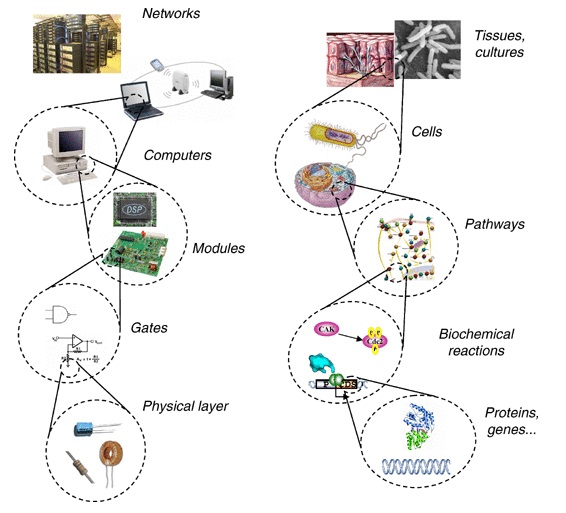
_
_
Synthetic hierarchy of synthetic biology:

_
Synthetic biology applies engineering principles, in particular electrical engineering principles, to the understanding of biological processes and the construction of cells and organisms with new function. As the electronic circuitry of computers is built from transistors, processors, and mainboards, the circuitry of cells can be deconstructed into protein and gene networks. Researchers are reprogramming cellular networks by engineering them with artificial components that allow us, for example, to conduct Boolean logic operations with DNA molecules and to expand the genetic code with non-natural amino acids. These tools enable us not only to investigate biological systems, but also to construct cells and organisms with fundamentally new functions in order to address important societal problems, especially related to human health. Any hardware and software circuitry is constructed based on fundamental Boolean logic gates that are connected in ways that allow for complex computational operations. Researchers are trying to build those circuits not from traditional components, but from biological materials, most importantly DNA, in order to interface them with cells and organisms. Computation events based on DNA logic gates have been developed in recent years and researchers have demonstrated their applicability in human cells.
______
Parts, Devices and Systems:
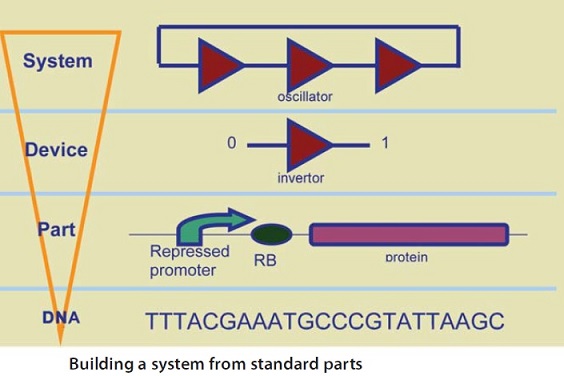
_
Part:
A biological part (or simply, part) is a sequence of DNA that encodes for a biological function, for example a promoters or protein coding sequences. At its simplest, a basic part is a single functional unit that cannot be divided further into smaller functional units. A basic part is a functional unit of DNA that cannot be subdivided into smaller component parts. BBa_R0051 is an example of a basic part, a promoter regulated by lambda cl. Basic parts can be assembled together to make longer, more complex composite parts, which in turn can be assembled together to make devices that will operate in living cells. A composite part is a functional unit of DNA consisting of two or more basic parts assembled together. BBa_I13507 is an example of a composite part, consisting of a rbs, protein coding region for a red fluorescent protein, and terminator. A device is a type of composite part that conducts an operation in the cell. BBa_I763007 is an example of a device, which uses BBa_R0051 and BBa_I13507, to regulate production of red fluorescent protein in cells with lambda cl.
Figure below shows prokaryotic and eukaryotic parts:
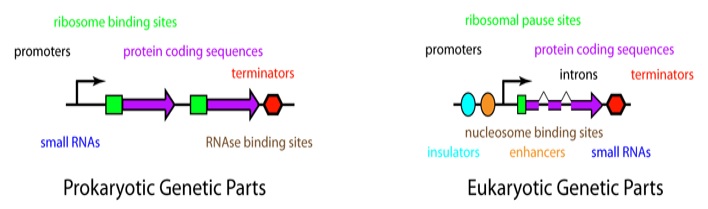
_
Genetic devices:
Genetic devices are combinations of parts that implement a defined function. Hallmarks in this field are several designs inspired by electronic circuitry, such as genetic toggle-switches, timers, oscillators and logic evaluators. Their functioning is based on the control of transcription, translation or post-translational processing. Complex “devices” are assembled from well-defined modular parts but it is challenging to fully predict their function. They may also be less robust than natural systems, and endogenous regulatory systems may interfere with the function of synthetic biology devices. It is difficult to predict what the assembled parts will do, even when much is known about them individually. Engineering new proteins or gene circuits may lead to direct interaction among new components or to indirect interactions via their effects on the organism (“chassis”) into which they are introduced. Due to lacking co-evolution unforeseen cross-reactions may occur. It may be expected that engineered organisms survive poorly in real-world environments.
_
Synthetic biology follows a hierarchical structure, building up systems from smaller components. At the lowest level are the parts, which are pieces of DNA that encode for a single biological function such as an enzyme or promoter. These parts are then combined into the next layer, a device, which is a collection of parts that performs a desired higher order function, for example production of a protein. Devices are further combined into a system, which can be defined as the minimum number of devices necessary to perform the behaviour specified in the design phase. Systems can have fairly simple behaviour (e.g. an oscillator) or more complicated behaviour (e.g. a set of metabolic pathways to synthesise a product). Parts and devices are usually treated as modular entities in design and modelling. This means that it is assumed that they can be exchanged without affecting the behaviour of other system components that are left untouched, which is problematic in biological systems. Systems must be implemented in a chassis, which provides the underlying biology necessary to transcribe and translate the system as well as any enzymatic substrates that would be necessary. The chassis can be a living organism (also called in vivo implementation), or it can be abiotic, providing only the necessary biochemical components for in vitro transcription and translation.
_____
Standardisation: Synthetic Biology based on standard parts:
To design these new systems, synthetic biologists will look to natural biological systems to find functional units of DNA or synthesize new ones that do not naturally exist. These functional units are tested and characterized and may become components in a biological device or system. We refer to them as parts: a sequence of DNA that encodes for a specific biological function. The standard in “standard parts” means that these parts meet established criteria. The creation of a standard library of parts, that enables a ‘plug-and-play’ framework for biological circuits to achieve a certain function is analogous to binary transistor logic libraries used by electrical engineers. If the complexity of biology is to be tamed, then standardization becomes of paramount importance. The synbio community understood this, and it is working towards building standard biological parts and methods that can be exchanged from one laboratory to another without the need to re-invent them all the time. The iGEM public registry of standard biological parts, for instance, is a repertoire of Lego-like DNA building blocks (BioBricks) that can be used to design and assemble biological circuits. A similar spirit drives industry. The UK company Synthace is developing Antha: a high-level programming language for biology designed to make simple, reproducible and scalable workflows by stacking smart and reusable elements. The aim is to standardise biology and to make it more reproducible. Standardisation is necessary to accurately reproduce synthetic biology devices and systems. However, concomitantly the full characterisation of parts is necessary, which has currently not yet been reached to a sufficient extent. Parts usually need to be characterised in a specific genetic or environmental context and do not function in a predictable manner when taken out of this context. Thus, it will be necessary to solve the issues of parts characterisation and interoperability by increasing the scope and diversity of tested designs.
_
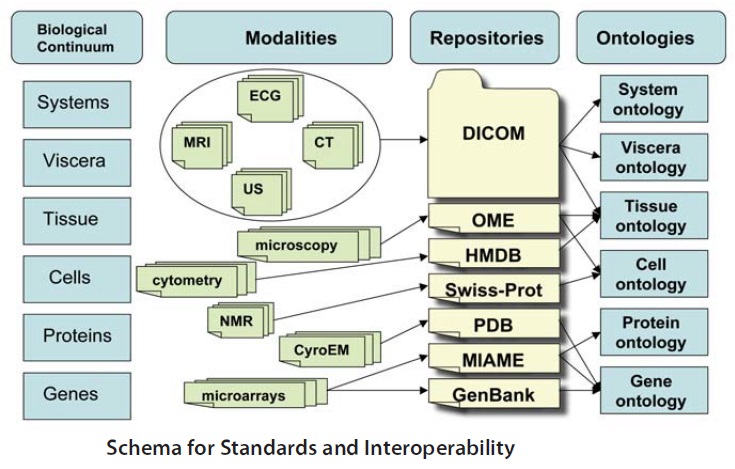
_
Assembly Standards, like the BioBrick Standard, ensure compatibility between parts and define how part samples will be assembled together by the engineer. Part samples that belong to the same Assembly Standard can be assembled together creating new, longer, and more complex parts, while still maintaining the format of the Assembly Standard. The goal of most engineers is to simplify and standardize the process of creation. By simplifying and standardizing biology, the engineer can go on to use parts to create their biological systems without spending time researching each individual component or worrying about how to assemble them together. The goal of the Registry is to aid in this process by creating a library of standard parts that have been tested, characterized, and organized so that users can find what they need when developing new biological systems.
_
The BioBricks™ standard:
The most commonly used standardized DNA parts are BioBrick plasmids invented by Tom Knight in 2003. Biobricks are stored at the Registry of Standard Biological Parts in Cambridge, Massachusetts and the BioBrick standard has been used by thousands of students worldwide in the international Genetically Engineered Machine (iGEM) competition. BioBricks are biological parts for engineering purposes. “BioBricks™” are standardised biological parts (basic and composite), which conform to the BioBrick™ assembly standard. Adhering to this standard guarantees compatibility between parts and/or to BioBrick™ plasmid carriers and allows that any newly composed part will be ready for recombination with other parts adhering to the BioBrick™ assembly standard without the need for further genetic manipulation. The BioBrick™ assembly standard in general takes care for appropriate restriction enzyme target sequences, compatible multiple cloning sites in carrier vectors and appropriate backbone sequences. This approach allows the scientist to focus on design of new functions instead of dealing with technical problems concerning cloning and genetic manipulations. BioBricks™ are available to the scientific community and may be freely recombined to produce new genetic entities as seen in the table below. Information on BioBricks™ is collected and shared via the internet platform Registry of Standard biological Parts. Physical samples of basic and composite parts may be retrieved from the Registry of Standard Biological Parts (Registry Repository).
_
iGEM adding new biobricks:
For two years before the Venter Institute’s January 2008 announcement, hundreds of undergraduates from around the world had spent their summer holidays making biological parts and building systems with them. In 2006 alone, 32 teams that participated in the International Genetically Engineered Machines, or iGEM, competition, hosted by the Massachusetts Institute of Technology, added 724 new biobricks to MIT’s Registry of Standard Biological Parts. In 2008, 84 teams and more than 1,000 undergraduate participants from 21 countries across Asia, Europe, Latin America, and the U.S. participated. Biotech companies and venture funds from around the world sponsor teams in the competition.
_
Types of parts available from the BioBrick™ Registry Repository (modified from iGEM [2014]).
| BioBrick™ parts | Description |
| Promoters | Recruitment sites for transcription machinery RNA Polymerase binding sites |
| Ribosome binding sites | Region on mRNA for ribosomal binding translation initiation |
| Protein domains | Encodes functional compartments of protein sequence |
| Protein coding sequences | Encodes the amino acid sequence of a protein |
| Translational units | Translational units are composed of a ribosome binding site and a protein coding sequence. They begin at the site of translational initiation, the RBS, and end at the site of translational termination, the stop codon. |
| Terminators | Transcription stop signal at the end of a gene or operon |
| DNA | DNA parts provide functionality to the DNA itself. DNA parts include cloning sites, scars, primer binding sites, spacers, recombination sites, conjugative transfer elements, transposons, origami, and aptamers. |
| Plasmid backbones | A plasmid is a circular, double-stranded DNA molecule typically containing a few thousand base pairs that replicate within the cell independently of the chromosomal DNA. A plasmid backbone is defined as the plasmid sequence beginning with the BioBrick™ suffix, including the replication origin and antibiotic resistance marker, and ending with the BioBrick™ prefix. |
| Plasmids | A plasmid is a circular, double-stranded DNA molecule typically containing a few thousand base pairs that replicate within the cell independently of the chromosomal DNA. If you’re looking for a plasmid or vector to propagate or assemble plasmid backbones, please see the set of plasmid backbones. There are a few parts in the Registry that are only available as circular plasmids, not as parts in a plasmid backbone. Note that these plasmids largely do not conform to the BioBrick™ standard. |
| Primers | A primer is a short single-stranded DNA sequence used as a starting point for PCR amplification or sequencing. Although primers are not actually available via the Registry distribution, commonly used primer sequences are included. |
| Composite parts | Composite parts are combinations of two or more BioBrick™ parts. |
_
Why are Standards so important?
Standard parts make it easy to move a part from one plasmid backbone to another. By adopting one plasmid backbone pSB1C3 as a “shipping” plasmid, it is easier for us to manufacture the annual DNA distribution (the ‘Kit of Parts’) and perform quality control without needing a huge staff of scientists. Similarly, the ease of moving a part from one plasmid backbone to another allows a user to move a part or system into the backbone that makes the most sense for a variety of different needs in addition to shipping, including assembly, manufacturing, operation, measurement, and more. Also, as DNA synthesis of longer segments has become less expensive, it is easier to design to the required standards.
The technical requirements for the BioBrick standard are:
- Standard prefix: GAATTCGCGGCCGCTTCTAGAG
- Standard prefix if preceding a coding region: GAATTCGCGGCCGCTTCTAG (contains a start codon)
- Standard suffix: TACTAGTAGCGGCCGCTGCAG
- The part must not contain any of the forbidden restriction sites: EcoRI, XbaI, SpeI or PstI.
- All plasmids must be shipped in the standard shipping backbone, pSB1C3 (parts.igem.org/Part:pSB1C3).
Synthetic biologists also utilize a variety of other physical assembly standards, such as BioBrick BB-2, Silver Standard, Freiberg Standard, MoClo and Mammoblocks.
_
In theory, there are all sorts of things you could build from BioBrick components, but in practice it’s hard to get results easily. As Roberta Kwok explains in Nature, many of the components in the BioBrick registry are unreliable: Even if they worked in one context under specific conditions, there’s no real guarantee that they’ll work consistently in others. Ultimately, Kwok suggests, the Lego comparison may be inapt, partly because parts don’t always fit together well in cells and may integrate into them in unpredictable ways. Researchers are also embracing CRISPR gene editing technology to build larger and more complex genetic circuits. But complexity brings its own challenges, potentially adding new layers of uncertainty. That’s one of the reasons that some synthetic biologists are working to create new life forms from scratch. If you can simplify the organism to the point where you can predict its behavior more consistently, you can potentially do a lot more with it.
__
Registry of parts:
To make use of parts efficiently, the need for a professional registry of parts was identified (Kitney and Freemont 2012). The registry comprises a database and should include the full characterisation of parts in the context of suitable hosts. To tackle the storage and assembly of genetic parts, the Registry of Standard Biological Parts (RSBP) was established, which facilitates the methodological assembly of parts into larger circuits by storing them in the standardised “BioBrick™” format. A standard computational language (Synthetic Biology Open Language, SBOL) was subsequently developed to describe parts and designs, and to facilitate their exchange. The Synthetic Gene Database (SGDB) is a relational database that houses sequences and associated experimental information on synthetic (artificially engineered) genes from all peer-reviewed studies published to date.
______
The full circle of DNA synthesis:
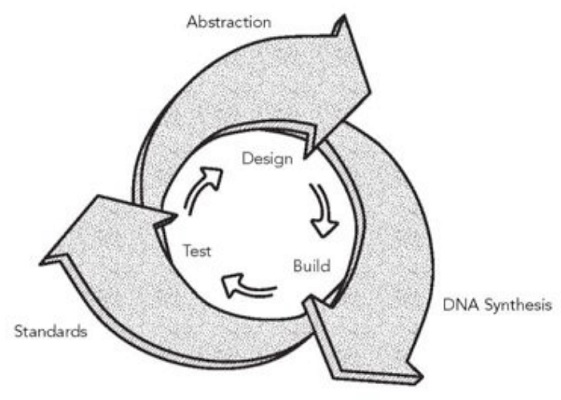
_______
Building biological systems from parts:
In line with the principles of classical engineering, synthetic biology aims at building biological systems from basic components. On DNA level, basic components are promoters, operators, upstream activation sequences (UAS), ribosome binding sites (RBS), open reading frames (ORF), terminators etc. These “parts” are combined to create genetic circuits of increasing complexity following a systematic design framework. Current synthetic biology mainly focuses on the construction and optimisation of regulatory devices and metabolic pathways. The creation of novel genomes from parts is an ultimate goal for the future.
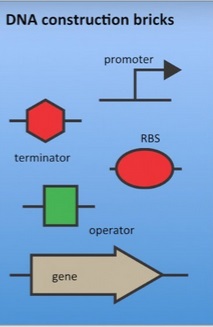
_
Regulation of gene expression:
A part is a distinct DNA sequence which performs a defined function in a genetic circuit and is compatible with an assembly technique. A gene is an open reading frame (ORF) along with all regulatory elements required for successful expression. A functional gene or “composite part” usually consists of a promoter, a translation start site (the RBS in prokaryotes), the protein coding ORF and a terminator. Assembly of a gene from its individual parts functionally requires ordered assembly. One of the foundational advances of synthetic biology was the BioBrick™, a DNA unit with standardised flanking sequences that enables assembly to be achieved by a cheap, simple and standardised restriction/ligation method. With BioBricks™ it became possible to store pots of modular biological parts that could be shared and easily assembled in different combinations by a vibrant community. A pathway is a group of genes or operons (multi-ORF genes) which may perform related functions. Such pathways, devices and regulatory networks could be used for integrated assembling to build synthetic designer genomes or chromosomes for custom organisms. Regulatory elements are of pivotal importance for designing predictable system. Regulation is achieved at several levels in biological systems: transcription, RNA processing, translation, protein-protein interactions, and protein-substrate interactions. Spatial and temporal organisation of these control systems ensures their proper function. In particular proteins may interact with any suitable binding partners, regardless of the cellular compartment. Synthetic proteins may be rearranged and thereby yield new behaviour. In synthetic systems, the metabolism may be optimised at many scales — compartmentalisation, proteins – substrate channelling, scaffolding of complexes, enzymes – electron transfer in mitochondria and chloroplasts. Many new biological parts, like organelle-targeting sequences, transmembrane transporters and bacterial microcompartment (BMC) pores, need to be characterised for efficient intracellular engineering. Metabolic networks function through different strategies that bring together appropriate cells, enzymes and substrates in time and space. Control of gene expression is achieved on the levels of transcription (regulated promoters, transcriptional riboswitches) or translation/post-translation, which fosters faster dynamics. Components (i.e. genetic parts, devices and systems) and tools to regulate these components in a predictable and quantitatively controllable manner have to be designed.
_
Synthetic biology will seek to use and expand the mechanisms that control biological organisms using engineering approaches. These approaches will be applied on all scales of biological complexity: from the basic units (design and synthesis of novel genes and proteins, expansion and modification of the genetic code) to novel interactions between these units (regulation mechanisms, signal sensing, enzymatic reactions) to novel multi-component modules that generate complex logical behaviour, and even to completely or partially engineered cells. Bringing the engineering paradigm to biology will allow us to apply existing biological knowledge to biotechnological problems in a much more rational and systematic way than has previously been possible, and at the same time to expand the scope of what can be achieved this way. The introduction of design principles such as modularity of parts, standardization of parts and devices according to internationally recognized criteria, and the (reciprocal) adaptation of available abstract design procedures to biological systems, coupled to novel technological breakthroughs (such as cheap mass synthesis of large DNA segments) that allow the decoupling of design and fabrication, will fundamentally change our current concepts of how to manipulate biological systems. In this sense, synthetic biology is not primarily a “discovery science” (that is, concerned with investigating how nature works), but is ultimately about a new way of making things. By adapting natural biological mechanisms to the requirements of an engineering approach, the possibilities for re-assembling biological systems in a designed way will increase tremendously.
_
It is important to note that, as in other areas of engineering, modules-of-modules are likely to become important building blocks in construction: for example, transistors are ‘components’ at a low level, while fixed arrangements of transistors (in an integrated circuit) can be considered ‘basic components’ at higher level, and fixed arrangements of integrated circuits (e.g. data servers) can be considered ‘basic components’ at another level still. The ‘BioBricks’ available so far are basic DNA parts (promoters, protein-coding domains, etc.) or combinations of parts (logic gates, signal senders, etc.). Weber et al. have considered making larger-scale parts available on the BioBrick registry: the so-called ‘CytoBricks’ are well-characterized mammalian cell lines with stably integrated synthetic networks. Applying this building blocks concept to yet other scales, we may envisage engineering whole tissue parts or even organ parts.
_____
Synthetic gene circuits:
Synthetic biology is bringing together engineers and biologists to design and build novel biomolecular components, networks and pathways, and to use these constructs to rewire and reprogram organisms. These re-engineered organisms will change our lives over the coming years, leading to cheaper drugs, ‘green’ means to fuel our cars and targeted therapies for attacking ‘superbugs’ and diseases, such as cancer. The de novo engineering of genetic circuits, biological modules and synthetic pathways is beginning to address these crucial problems and is being used in related practical applications. The circuit-like connectivity of biological parts and their ability to collectively process logical operations was first appreciated nearly 50 years ago (Monod and Jacob, 1961). This inspired attempts to describe biological regulation schemes with mathematical models (Glass and Kauffman, 1973; Savageau, 1974; Kauffman, 1974; Glass, 1975) and to apply electrical circuit analogies to biological pathways (McAdams and Arkin, 2000; McAdams and Shapiro, 1995). Meanwhile, breakthroughs in genomic research and genetic engineering (for example, recombinant DNA technology) were supplying the inventory and methods necessary to physically construct and assemble biomolecular parts. As a result, synthetic biology was born with the broad goal of engineering or ‘wiring’ biological circuitry — be it genetic, protein, viral, pathway or genomic — for manifesting logical forms of cellular control. Synthetic biology, equipped with the engineering-driven approaches of modularization, rationalization and modelling, has progressed rapidly and generated an ever-increasing suite of genetic devices and biological modules. The natural activity of cells is controlled by circuits of genes analogous to electronic circuits. So another approach to making cells do new things relies on creating novel internal circuitry to alter their pattern of activity. Using well-understood genetic components that act as molecular switches it should be possible to devise artificial gene networks. Linked together and implanted into natural systems such networks could be used to control what those systems do, when, and how frequently.
_
In the late 1990s, people on a tour of MIT’s artificial intelligence lab would have found Weiss and Knight running wet lab experiments. “With our pipettes, gloves, and lab coats, we were an unusual sight in that engineering division,” Weiss says. Weiss’s goal was to build a plasmid, a custom-made DNA sequence that can be replicated easily. Knight, an electrical engineer, aimed to pare down the genome and repurpose the cell to produce things it was not originally designed to make — plastics, say, or fuels. It took Weiss 6 months to build his first plasmid. Once it was done, he was in business. Now he could design, build, and test DNA constructs to control the cell’s machinery through standard biochemical operations like transcription, translation, or post-translation processes. Weiss combined elements like promoters, binding sites, and repressors to form modules with a characteristic behavior. Along with Knight, Weiss documented these devices — roughly analogous to electronic components — in the Registry of Standard Biological Parts, an open-source toolkit for biological engineers. Weiss calls these systems — connected networks of components designed using DNA — “genetic circuits.” Just as engineers use Boolean logic gates to build digital devices, synthetic biologists can encode logic operations in networks of these DNA modules. In 2009, Weiss returned to MIT as an associate professor with dual appointments: one in electrical engineering and computer science, the other in biological engineering. Members of the Weiss group devise techniques to engineer stem cells, turning them into tissue that can replace cells lost to injury or disease. Just as the human body differentiates cells into types based on a complex set of rules during embryogenesis, DNA circuits march stem cells through a series of steps to yield a desired tissue. Already, the team has achieved a measure of success in converting mouse stem cells into insulin-producing pancreatic cells. Patrick Guye, a postdoctoral associate in the Weiss group, is investigating whether the system can work in human cells. In a recent Science paper, Zhen Xie, another postdoctoral associate from Weiss’s group, published results on using a genetic circuit to identify HeLa, a cancer cell. When inserted into cells, this setup determines the levels of a half dozen biomarkers to determine whether the cell is cancerous. If the result is positive, it triggers cell death. “Whether it is a specific cancer cell, stem cell, or neuron, each cell state is characterized by a set of biomarkers and it is possible to develop reliable diagnostics for diseases based on that,” Weiss says. “There is a gold mine of information inside the cell.”
_
Biology and complexity:
One of the most basic premises of biological engineering is to take something complex — such as a living cell — and simplify it by treating it as a series of interchangeable parts. But to make the work pay off, the real challenge is the reverse: to get systems that work well in a lab’s relatively simple setting to work in the more complex natural environment. Engineers need to design systems that can evolve and adapt to such contextual differences.
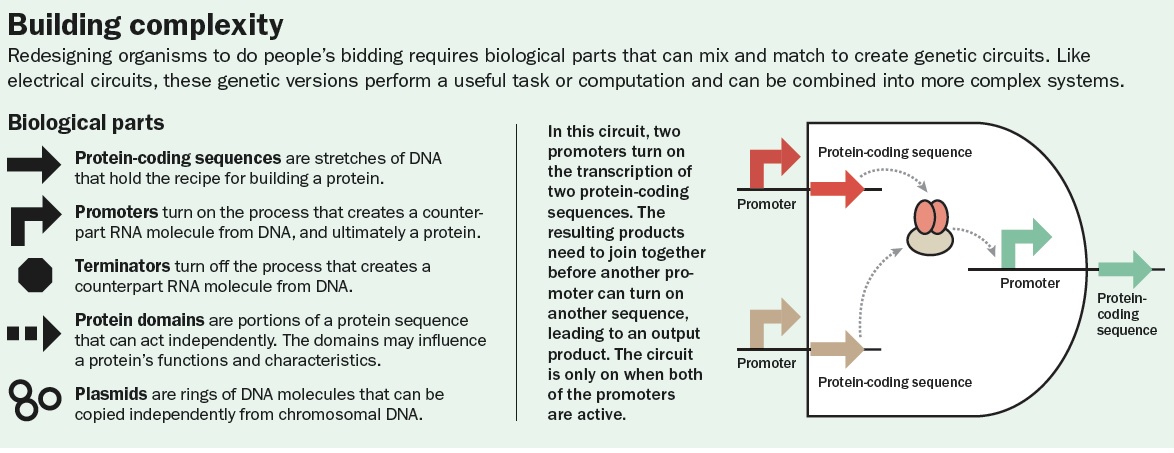
_
Genetic circuits encoding dynamic behaviors:
The construction of two genetic circuits encoding dynamic behavior, the repressilator and the toggle switch, marked two early efforts in genetic circuit design in synthetic biology. The repressilator, a three-ring oscillator built from a loop of three repressor-promoter pairs, demonstrated that an oscillatory response could be generated from biological parts not found in natural biological oscillators. Well-defined, synthetic gene circuits that control the temporal profile of gene expression can elucidate the contributions of expression dynamics to natural time-dependent processes, such as cell signalling, cell-fate determination, and development. Synthetic gene circuits also offer the potential to develop genetically encoded strategies for intervening and controlling these natural processes.
_
Examples of gene circuits reported during the foundational years of synthetic biology (2000–2003).
- The toggle switch.
A pair of repressor genes (lacI and cI) are arranged to antagonistically repress transcription of each other, resulting in a bistable genetic circuit in which only one of the two genes is active at a given time. The toggle can be ‘flipped’ to the desired transcriptional state using environmental inputs to disengage one of the repressors from its operator (for example, IPTG (isopropyl-β-D-thiogalactoside) is used to disengage LacI and heat is used to disengage cI). Once the input is removed, the desired transcriptional state persists for multiple generations.
- The repressilator.
The circuit is constructed from three repressor–promoter interactions (between cI, LacI and TetR repressors and their associated promoters), which are linked together to form a ring-shaped network, in which TetR regulates a GFP-reporter node. When analysed at the single-cell level using time-lapse fluorescence microscopy, the circuit exhibits periodic oscillations in GFP expression, which persist for a number of generations; however, oscillations become dampened after a few periods and are generally noisy, with individual cells showing high variability in both the amplitude and period of their oscillations.
- Autoregulatory circuit.
In this circuit, TetR-mediated negative-feedback regulation of its own transcription results in a narrow population-wide expression distribution, as measured by the co-transcribed GFP reporter. The circuit demonstrates a principle that was long-appreciated in control-systems engineering and nonlinear dynamics — that noise in a system can be reduced by introducing negative feedback.
_
Switches and oscillators:
Switches and oscillators that occur in electronic systems are also seen in biology and have been engineered into synthetic biological systems.
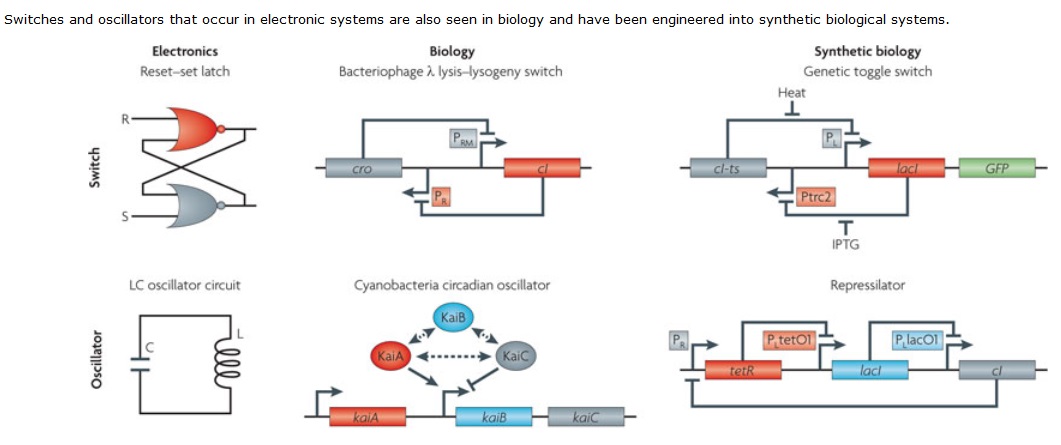
The successful design and construction of the first synthetic gene networks — the genetic toggle switch (Gardner et al., 2000) and the repressilator (Elowitz and Leibler, 2000) showed that engineering-based methodology could indeed be used to build sophisticated, computing-like behaviour into biological systems. In these two cases, basic transcriptional regulatory elements were designed and assembled to realize the biological equivalents of electronic memory storage and timekeeping. Researchers have made DNA elements that are toggle switches that can be turned on or off, ones that reduce noise in response to negative feedback, and ones that create an oscillating signal, among others. Within the framework provided by these two synthetic systems, biological circuits can be built from smaller, well-defined parts according to model blueprints. They can then be studied and tested in isolation, and their behaviour can be evaluated against model predictions of the system dynamics. This methodology has been applied to the synthetic construction of additional genetic switches.
_
Examples of gene circuits reported during the intermediate years of synthetic biology (2004-2007).
- Modular riboregulator.
A cis-repression sequence is appended to the 5′ UTR of a gene transcript to inhibit translation by blocking the ribosome binding site (RBS). Translation inhibition is reversed by the expression of an inducible transactivating sequence that tightly binds to the cis-repression sequence, thereby exposing the RBS to enable translation of GFP.
- Two-input AND gate.
One of the first examples of the successful programming of logical operations in a cell was an AND-gate circuit in which simultaneous exposure of cells to two external inputs was converted into a transcriptional output. In response to arabinose, AraC-mediated induction of one promoter results in the transcription of a T7 polymerase that is engineered to contain two TAG (amber) stop codons in its coding sequence. The second promoter, which is activated by NahR in the presence of salicylate, controls the transcription of SupD, which is an amber suppressor tRNA that recognizes the TAG stop codon and adds a serine residue to the nascent polypeptide, enabling read-through translation of the T7 polymerase. Transcription and translation of T7 can occur only in the presence of both environmental inputs, which leads to GFP expression from the T7-dependent promoter.
- Multicellular pattern formation.
The circuit, which was engineered to produce an ordered pattern on a two-dimensional field of bacterial cells, consists of genetic parts derived from Vibrio fischeri: LuxI, which is an enzyme that produces the quorum-sensing molecule acyl homoserine lactone (AHL), is expressed in ‘sender’ cells, whereas ‘receiver’ cells express LuxR, which is an AHL-sensitive transcriptional activator. By coupling LuxR function to a feedforward circuit architecture, receiver cells are programmed for bandpass detection of AHL, and fluorescent reporter gene expression is activated only at discreet concentrations of AHL. Adjusting the sensitivity of LuxR activation results in strains that have high-sensitivity (HS) or low-sensitivity (LS) AHL detection capabilities. HS and LS receiver strains are programmed with red fluorescent protein (RFP) and GFP output, respectively, and mixed together in a bacterial lawn in which sender cells are placed in the middle. This results in the emergence of a banded, bullseye pattern of fluorescent-reporter expression.
_
Examples of gene circuits reported during the most recent era of synthetic biology (2008-2013).
- Relaxation oscillator.
The circuit uses well-characterized parts (specifically, AraC and LacI) that have been used in previous circuits, but its design is fundamentally different from the ring design of the repressilator and is based instead on overlapping positive- and negative-feedback loops, in which AraC and LacI mediate positive and negative regulation, respectively. Circuit components were assembled on the basis of carefully parameterized modelling, and the circuit was analysed in a microfluidic device to ensure a precisely controlled microenvironment. These key advances resulted in a robust, stable, nearly population-wide oscillatory behaviour over multiple generations.
- Recombinase-based logic.
These circuits take advantage of recombinase-based DNA inversion and the fundamental directionality of many biological parts to generate logic gate behaviour in genetic circuits. Using a small library of well-characterized parts, all 16 possible logic gates could be constructed. The input modules for the system remain constant, with small molecules used for the induction of the orthogonal recombinases (Rec1 and Rec2), which cause unidirectional inversion of their target sequences. Depending on the order and orientation of genetic parts in the uninduced circuit, the small molecule inputs produce a GFP output signal, as specified by the corresponding logic gate. For example, the AND-gate circuit only produces a GFP output signal when both inputs are present, causing the constitutive promoter and the GFP gene to be independently inverted such that they are in the appropriate orientation to enable constitutive GFP expression.
- Edge-detection circuit.
A quorum-sensing system was combined with a hybrid two-component light sensor to compute the edge of an illuminated area. In the circuit, unilluminated bacteria function as sender cells that produce and secrete the quorum-sensing molecule AHL, whereas illuminated bacteria function as receiver cells that cannot produce AHL but can respond to it by expressing the LacZ enzyme to produce a visible black pigment. The illuminated receiver cells can only sense the AHL that is produced by the dark sender cells in regions in which the two cell types are in close proximity — at the edge of an illuminated area — thereby generating a visible outline of the image.
_
Simple light bulb genetic circuit:
The simplest way to build a circuit is to have a light bulb as output. Synthetic biology, for all its complexity, is the same. The “light bulb” that the researchers used is actually a gene snippet that encodes a protein that glows green under UV light, called green fluorescent protein, or GFP. Normally a cell would happily make the protein and itself glow. To build their NOT gate, the team added another gene instruction before the GFP gene—a termination sequence, which is the genetic version of “stop right there!” To make their circuit more complex, the team added an if-then command. Here’s how it worked: they made a DNA recombinase that can snip away the termination sequence, but only when it’s in the presence of a drug. When the cell doesn’t sense the drug, the DNA recombinase is inactive, the termination sequence stays in place and the cell remains translucent and colorless. If a drug is added, then the recombinase jumps into action and cuts away the NOT gate. Output? The cellular “light bulb” comes on. While a glowing cell may seem trivial, scientists can engineer cells to light up when it detects biomarkers for cancer, HIV or other diseases. You can mix a patient’s blood sample with engineered cells and instantly get your readout—a much cheaper and faster alternative to current diagnostics that require expensive machines.
_
Encoding cellular logic and computing functions:
Genetic circuits that perform computations and logical evaluations of cellular information provide the ability to assess intracellular states and environmental signals. They transmit this information into changes in cellular function, such as production of easily assayed readouts, activation of metabolic pathways, or initiation of cell-fate decisions. Towards this goal, genetic circuits and devices capable of performing logical evaluations have been built to detect small molecules (using tandem promoter systems and RNA devices), and small RNAs such as small interfering (si)RNAs (using tandem RNA interference (RNAi) target sites) . These various schemes have demonstrated the classic NOT, OR, NOR, and AND gates that are used to build larger logic evaluators and computations. Methods for counting and maintaining memory of system states will enable a broader spectrum of intracellular computing. A genetic circuit that can count up to three exposure events to a small-molecule inducer was built in bacteria by nesting polymerase-promoter pairs controlled by riboregulators responsive to an inducible transactivator. Although this system captured brief induction pulses, system performance was highly dependent on pulse duration and frequency. The incorporation of genetic memory offers an alternative strategy to increase the robustness of counting events over longer time frames. A three-event counter circuit was demonstrated by using DNA recombinase-based cascades that record each event as a permanent change to the DNA, where the output of each recombinase event would ‘prime’ the next promoter-recombinase pair in the circuit. Synthetic networks of feedback loops have been built as memory circuits that lock a system in one state through sustained production of proteins following a transient signal that initiates the state. For example, toggle switches engineered to show bistability in bacteria and mammalian cells use architectures of mutually inhibitory feedback loops to achieve reversible memory of small-molecule pulses. As another example, a positive feedback loop built from a synthetic transcriptional activator cascade demonstrated heritable memory over many generations in yeast.
_
Life isn’t digital.
Why are engineers trying to implement digital logic in cells?
Engineers are much better at thinking and designing digital systems. One reason they are better at digital system design is that such systems create an ‘abstraction barrier’ between the detailed device physics level and the system design and operation levels.
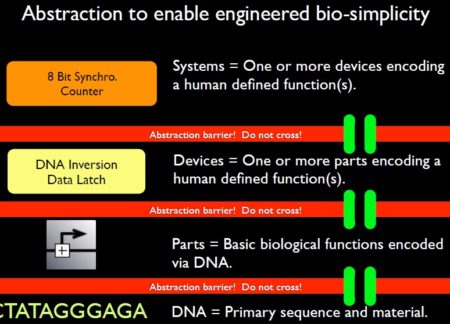
_
One recurrent limitation in adapting biological systems to perform computation through the rules of binary logic is the analog nature of the responses. In particular, gene expression leakage in the OFF state can contribute to improper input processing and high basal output, diminishing an evaluator’s signal-to-noise ratio. In addition, control of highly lethal proteins and proteins that mediate irreversible genetic changes requires stringent OFF states. To address this issue, researchers have layered transcriptional and posttranscriptional control elements within genetic circuits to provide strategies for achieving stringent regulation of transgenes in mammalian and bacterial cells. In one example, an inducible promoter was layered with repressible expression of a small hairpin (sh)RNA to achieve undetectable expression levels of the highly lethal diphtheria toxin in the OFF state, thus enabling induced cell death only in the ON state. Although tight OFF states are desirable for binary computing, biological computing necessarily exploits the analog and tunable nature of gene expression. Connecting logical circuit outputs to changes in cellular state requires the ability to both identify thresholds of expression at which cellular behavior diverges and tune the output to cross that threshold when triggered. Combining the computational ability of logical evaluators with improved strategies for leakage minimization and output tuning should enable more robust computing. These tools can expand our ability to detect and treat diseases by increasing diagnostic certainty and improving precision in gene expression, and can also be used to probe previously inaccessible information sets, such as the temporal and spatial profiles of particular developmental genes, which will inform our fundamental understanding of biology.
_
Form circuit to system:
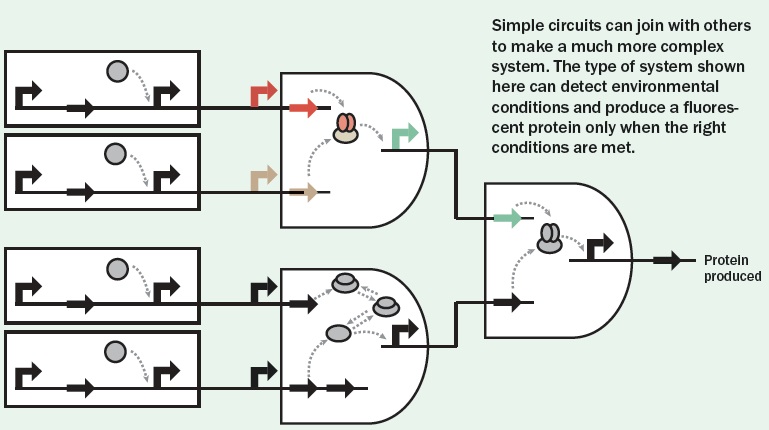
_
_
From parts to genetic circuits to applications:
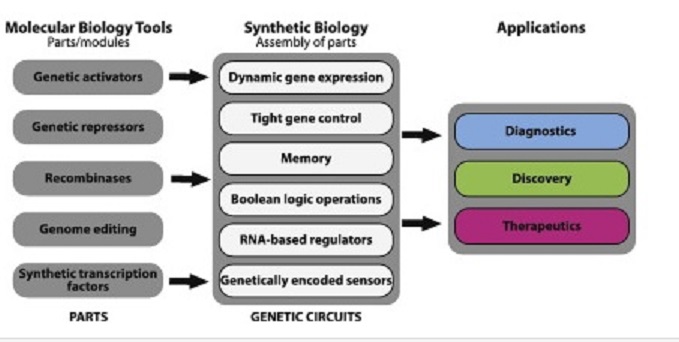
_
Genetic switchboard for synthetic biology applications:
As synthetic biology matures, the drive for higher-order systems and larger DNA assemblies is intensifying. Recent successes include a sensing array for the detection of heavy metals and pathogens and a wide range of logic computations using simple circuits and chemical wires. However, this push for complexity underscores the need for interoperable parts and expandable systems. Additional components that can be scaled up and operate orthogonally are needed for synthetic biology to continue to produce innovative systems and capitalize on its full potential in biotechnology. Genetic switchboard is a higher-order device that independently and tightly regulates multiple genes in parallel. A switchboard is as an assembly of switches that is useful for controlling and linking electrical circuits. Genetic switchboard is an assembly of orthogonal, genetic switches that is useful for controlling and linking biological circuits and pathways. There are a number of practical future uses for the genetic switchboard in synthetic biology, biotechnology and metabolic engineering.
_
Modular protein assembly:
While DNA is most important for information storage, a large fraction of the cell’s activities are carried out by proteins. Therefore, it is important to have tools to send proteins to specific regions of the cell and to link different proteins together, as desired. Ideally the interaction strength between protein partners should be tunable between a lifetime of seconds (desirable for dynamic signalling events) up to an irreversible interaction (desirable when building devices stable over days or resilient to harsh conditions). Interactions such as coiled coils, SH3 domain-peptide binding or SpyTag/SpyCatcher have helped to give such control. In addition it is important to be able to regulate protein-protein interactions in cells, such as with light (using Light-oxygen-voltage-sensing domains) or cell-permeable small molecules by chemically induced dimerization.
_
Genetic refactoring:
Refactoring is the process of changing a software system in such a way that it does not alter the external behavior of the code yet improves its internal structure. Synthetic biology researchers drew inspiration from refactoring, a process used to streamline computer software without affecting functionality. To better understand and engineer particular genetic systems, researchers have begun to redesign and de novo synthesize these systems with orthogonal, well-defined gene sequences and control elements. Through refactoring, researchers hope to define and include known elements in a pathway while simultaneously disrupting any unknown control elements; this may serve as a better starting point for improvement or transplantation of these genetic systems. Early work resynthesized the first ~11 kb of bacteriophage T7 with a refactored surrogate that separated and defined individual genes and control elements and showed that the resultant phage was viable. More recent bacteriophage genome refactoring have helped improve biological understanding and usefulness. Temme et al. extended these approaches to refactor the Klebsiella oxytoca nitrogen-fixation 20-gene cluster in E. coli. They removed noncoding sequences, eliminated non-essential genes, removed transcription factors, randomized codons and placed all the genes into seven operons with synthetic regulatory elements governing transcription and translation. The refactored system reconstituted functionality, albeit at reduced production levels. Improvements in the design and automated assembly of these refactored segments allowed reconstitution to wild-type production levels. Finally, Lajoie et al. synthesized sequence-orthogonal variants of 42 E. coli essential genes using DNA microarrays and selected for function in order to explore the limits of genetic recoding. Again, such studies can powerfully explore regulatory requirements of genetic sequences but require currently expensive de novo synthesis methodologies and would greatly benefit from lower-cost gene synthesis.
_
Synthetic transcription factors:
Studies have also been performed on the components of the DNA translation mechanism. One desire of scientists creating synthetic biological circuits is to be able to control the translation of synthetic DNA in prokaryotes and eukaryotes. One study tested the adjustability of synthetic transcription factors (sTFs) in areas of transcription output and cooperative ability among multiple transcription factor complexes. Researchers were able to mutate zinc fingers, the DNA specific component of sTFs, to decrease their affinity for DNA, and thus decreasing the amount of translation. They were also able to use the zinc fingers as components of complex forming sTFs, which are the eukaryotic translation mechanisms.
_
Small molecule synthesis:
The directed evolution of small molecule ligands would be a bonanza for target validation and drug discovery, but is a substantially more complicated goal than directed evolution of nucleic acids and polypeptides. Though cellular and multicellular organisms have been evolving small molecule drugs for eons, this process is prohibitively slow. Now, a radically different in vitro approach called “DNA display” (Halpin and Harbury 2004) promises a solution. Enormous libraries of small molecule ligands potentially could be evolved using a combination of features of cell-free DNA-templated organic synthesis (Gartner et al. 2004) and split-and-pool combinatorial synthesis. The proof-of-principle DNA display “translations” required hundreds of manual steps to enable screening a library of 1,000,000 protease-sensitive peptide products (Halpin and Harbury 2004). However, adaptation to much larger libraries of more drug-like compounds is feasible using microarrays, automation, and other chemistries that do not modify DNA.
_
Modelling:
Cells can be viewed as interwoven networks of interactions among proteins, DNA, and metabolites involved in signalling, material, and energy transfer. Understanding of cellular systems and then modification of them require quantitative models which are capable of predicting complex intracellular interactions of biological elements, their modules and networks. A whole cell computational model has been built up for this purpose that has used data from more than 900 scientific papers to account for every molecular interaction that takes place in the life cycle of Mycoplasma genitalium. This type of detailed models need to be expanded to allow simulation for synthetic biology applications, such as prediction of complex phenotypes for biological chassis bearing heterologous genetic parts, or compatibility of cellular networks and the incoming artificial modules. Models inform the design of engineered biological systems by allowing synthetic biologists to better predict system behavior prior to fabrication. Synthetic biology will benefit from better models of how biological molecules bind substrates and catalyze reactions, how DNA encodes the information needed to specify the cell and how multi-component integrated systems behave. Recently, multiscale models of gene regulatory networks have been developed that focus on synthetic biology applications. Simulations have been used that model all biomolecular interactions in transcription, translation, regulation, and induction of gene regulatory networks, guiding the design of synthetic systems.
_
Biosensing:
Cells have evolved a myriad of regulatory circuits — from transcriptional to post-translational — for sensing and responding to diverse and transient environmental signals. These circuits consist of exquisitely tailored sensitive elements that bind analytes and set signal-detection thresholds, and transducer modules that filter the signals and mobilize a cellular response. The two basic sensing modules must be delicately balanced: this is achieved by programming modularity and specificity into biosensing circuits at the transcriptional, translational and post-translational levels.
_
Biosensors:
A biosensor refers to an engineered organism, usually a bacterium, which is capable of reporting some ambient phenomenon such as the presence of heavy metals or toxins. In this capability, a very widely used system is the Lux operon of Aliivibrio fischeri. The Lux operon codes for an enzyme which is the source bacterial bioluminescence, and can be placed after a respondent promoter to express the luminescence genes in response to a specific environmental stimulus. One such sensor created in Oak Ridge National Laboratory, and named “critter on a chip”, consisted of a bioluminescent bacterial coating on a photosensitive computer chip to detect certain petroleum pollutants. When the bacteria sense the pollutant, they begin to luminesce.
_______
Microfluidics:
On a micron-scale, common liquids like water have very different behaviour to our understanding of them in everyday experience. This length-scaling effect is illustrated by the Reynolds number (Re) of the system, which represents the ratio between inertial and viscous forces that act when fluid moves past an object. At high Re (>1000, e.g. when mixing milk in a cup of tea) inertia dominates, whilst at low Re (<0.01, associated with many microfluidic systems with applications in synthetic biology) viscous forces dominate. Under these latter conditions, fluid movement shows no inertia (and hence comes to an abrupt stop when driving forces are removed). This raises the possibility of accurately controlling the dispensation and movement of fluid at the micro scale – thus controlling fluid dispensation precisely, spatially and hence temporally, confining reagents to the parts of a chip being used for synthesis or assembly. The requirements imposed by synthetic biology on the synthesis of DNA sequences is the ability to quickly produce large quantities of long double stranded DNA fragments, typically at the nano- or picomol level, preferably at a reasonable cost. The recent progress in combinatorial chemistry, automation, robotics and microfluidics allows for highly parallel microscale synthesis of a very large number of oligonucleotides. The processing of sections of DNA (oligonucleotides) may from now on be more effectively carried out using microfluidic systems.
______
Engineered genetic networks and metabolic pathways:
Many researchers in synthetic biology are focused on building and optimizing genetic networks to control cellular behavior and metabolic pathways for chemical production. Although many of these efforts are focused on assembling already existing DNA in myriad combinations, de novo synthesis is still an important mainstay and will become increasingly so as we improve our ability to design and measure the effects of such assembled pathways. For instance, when building large, multicomponent systems, the number of orthogonal components becomes limiting. Large-scale studies of hundreds to tens of thousands of regulatory elements such as promoters, ribosome-binding sites and transcriptional terminators in E. coli usually use de novo synthesis of designs culled from both natural and designed sequences. As the genetic networks and pathways of engineered systems in synthetic biology get larger and studies move to new organisms, there will be increasing reliance on de novo DNA synthesis to generate requisite system components.
_
Early synthetic biology studies focused on engineering circuits in bacterial hosts. The first systems built were inspired by electronics and included the construction of genetic switches, oscillators, and digital logic gates. These synthetic networks showed that engineering-based methods could be used to programme computational behaviour into cells. They also helped to elucidate how naturally occurring gene networks can generate dynamic output behaviours such as oscillations or memory of transient stimuli. Engineering of unicellular organisms has led to interesting practical applications in biosensing, therapeutics and the production of biofuels and pharmaceuticals. Although in the beginning the field of mammalian synthetic biology merely mimicked and lagged behind this early bacterial work, it is now rapidly advancing owing to major developments in manipulating mammalian genomes and in methods for cloning large DNA circuits.
_
The combination of genetically engineered cells with recent developments in mimicking complex tissue structures and living organs has great potential to advance tissue engineering. Driven by progress in microfluidics, novel microdevices are able to emulate tissue structures, their dynamic mechanical properties and their biochemical functions. These devices are currently built using primary or immortalized cells, and the development of genetically engineered cells offers the opportunity to create even more sophisticated organ models. Cells that contain genetic circuits for synthetic pattern formation or induction of distinct cellular states could be used to create complex patterns of cells with different functionality. Besides offering insights into normal and diseased organ function, organ-mimicking devices are useful for preclinical drug development and toxicity screening. For example, engineered cells could be used to monitor cellular responses, specifically by genetic circuits that sense cellular states and confer memory to transient stimuli.
_
Engineered cells have also helped to advance therapeutic applications such as CAR therapies (Chimeric Antigen Receptor T-Cell Therapy) and cancer vaccines. However, mammalian system engineering still needs to overcome a number of technical hurdles, such as the scalability, orthogonality and predictability of synthetic circuit behaviours. Although programmable transcription factors and engineered protein–protein interaction domains are leading the way in addressing the problem of orthogonality, the predictability of genomically integrated DNA-based circuits still remains a cause of concern due to site-and cell type-specific effects. As one possible solution, the mammalian synthetic biology community could agree on characterizing circuits in a set of genomic loci such as safe harbour sites known to tolerate the integration of transgenes. Alternatively, one could consider expressing circuits from a human artificial chromosome, which can hold large amounts of DNA and does not integrate into the host genome. For the challenge of scalability, the key might be to use different types of regulators that act on different classes of molecules, for instance an assortment of transcriptional and post-translational regulators of RNA and proteins, as recently demonstrated for circuits that performed multi-bit (that is, the integration of multiple digital inputs) processing in mammalian cells. For therapeutic applications that are based on genetically engineered cells, the field also needs to address the issue of immunogenicity of the circuit components and cells. In this case, insights can be gained from CAR therapy technologies. For example, it has recently been shown that T cells made from induced pluripotent stem (iPS) cells can be used for CAR therapy, which offers an off-the-shelf alternative to autologous T cell isolation. The authors of this study proposed that the alloreactivity of iPS cell-derived T cells could be eliminated by disrupting the endogenous TCR, whereas allorejection could be minimized by generating iPS cells from common human leukocyte antigen (HLA) haplotypes.
______
Researchers solved one of the biggest problems in Synthetic Biology: a 2017 study:
By applying engineering principles to biology, researchers can create biological systems that don’t exist naturally. A problem of synthetic biology, however, is that these engineered genetic circuits can interfere with each other. While beneficial on their own, some of these man-made circuits become useless when they come in contact with each other, and this bars them from being used to solve complex biological problems. Researchers have discovered that placing synthetic genetic circuits in liposomes prevents them from interfering with one another, while still allowing them to communicate. Not only could this new form of “modular” genetic circuits lead to more complex engineered circuits, it could also provide insight as to how the earliest life on Earth formed.
______
______
Synthetic biology and information technology:
DNA can, of course, be viewed simply as information. And, according to synthetic biologists, cells can usefully be viewed as networks much like the information networks in information technology. To take the metaphor one step further, Endy and others envision a field where the information to be found on these networks should be available for free to all responsible researchers, much the way that some computer software is available for free (as “open source”). In theory, anyone who wants to use the parts or tools derived by synthetic biologists should be able to go to the shelf and use them for free. Not incidentally, the convergence with information technology has large implications for where and how production of synthetic parts and wholes can take place. Synthetic biology builds on a decades-long trend in flexible manufacturing. As one recent report explained, “DNA synthesis allows ‘decoupling’ the design of engineered genetic material from the actual construction of the material.” Once we place a genetic sequence in the global information network and combine it with remote and sophisticated production technologies, regulation of synthetic biology becomes very challenging.
_
Computational biology:
Computational biology is the study of biology using computational techniques. The goal is to learn new biology, knowledge about living systems. It is about science. Computational biology involves the development and application of data-analytical and theoretical methods, mathematical modelling and computational simulation techniques to the study of biological, behavioral, and social systems. The field is broadly defined and includes foundations in computer science, applied mathematics, animation, statistics, biochemistry, chemistry, biophysics, molecular biology, genetics, genomics, ecology, evolution, anatomy, neuroscience, and visualization. Computational Biology is the science of using biological data to develop algorithms and relations among various biological systems. Prior to the advent of computational biology, biologists did not have access to large amounts of data. Researchers were able to develop analytical methods for interpreting biological information, but were unable to share them quickly among colleagues. The terms computational biology and evolutionary computation have a similar name, but are not to be confused. Unlike computational biology, evolutionary computation is not concerned with modelling and analyzing biological data. It instead creates algorithms based on the ideas of evolution across species. Sometimes referred to as genetic algorithms, the research of this field can be applied to computational biology. While evolutionary computation is not inherently a part of computational biology, Computational evolutionary biology is a subfield of it. Computational biology has been used to help sequence the human genome, create accurate models of the human brain, and assist in modelling biological systems.
_
Bioinformatics:
Bioinformatics is the creation of tools (algorithms, databases) that solve problems. The goal is to build useful tools that work on biological data. It is about engineering. Bioinformatics involves the development of techniques to store, data mine, search and manipulate biological data, including DNA nucleic acid sequence data. These have led to widely applied advances in computer science, especially string searching algorithms, machine learning, and database theory. String searching or matching algorithms, which find an occurrence of a sequence of letters inside a larger sequence of letters, were developed to search for specific sequences of nucleotides. The DNA sequence may be aligned with other DNA sequences to identify homologous sequences and locate the specific mutations that make them distinct. These techniques, especially multiple sequence alignment, are used in studying phylogenetic relationships and protein function. Data sets representing entire genomes’ worth of DNA sequences, such as those produced by the Human Genome Project, are difficult to use without the annotations that identify the locations of genes and regulatory elements on each chromosome. Regions of DNA sequence that have the characteristic patterns associated with protein- or RNA-coding genes can be identified by gene finding algorithms, which allow researchers to predict the presence of particular gene products and their possible functions in an organism even before they have been isolated experimentally. Entire genomes may also be compared, which can shed light on the evolutionary history of particular organism and permit the examination of complex evolutionary events.
_
Computational bio-modelling:
Modelling biological systems is a significant task of systems biology and mathematical biology. Computational systems biology aims to develop and use efficient algorithms, data structures, visualization and communication tools with the goal of computer modelling of biological systems. It involves the use of computer simulations of biological systems, including cellular subsystems (such as the networks of metabolites and enzymes which comprise metabolism, signal transduction pathways and gene regulatory networks), to both analyze and visualize the complex connections of these cellular processes. Artificial life or virtual evolution attempts to understand evolutionary processes via the computer simulation of simple (artificial) life forms.
_____
The Synthetic Biology Open Language (SBOL) provides a community standard for communicating designs in synthetic biology:
The re-use of previously validated designs is critical to the evolution of synthetic biology from a research discipline to an engineering practice. Here authors describe the Synthetic Biology Open Language (SBOL), a proposed data standard for exchanging designs within the synthetic biology community. SBOL represents synthetic biology designs in a community-driven, formalized format for exchange between software tools, research groups and commercial service providers. The SBOL Developers Group has implemented SBOL as an XML/RDF serialization and provides software libraries and specification documentation to help developers implement SBOL in their own software. Authors describe early successes, including a demonstration of the utility of SBOL for information exchange between several different software tools and repositories from both academic and industrial partners. As a community-driven standard, SBOL will be updated as synthetic biology evolves to provide specific capabilities for different aspects of the synthetic biology workflow. Since its inception in 2008, the SBOL community has grown to include academic, government and commercial organizations, and it is on a path to become a widely adopted community standard. SBOL is supported by 21 software tools, including both commercial and academic efforts. To facilitate the adoption process, the SBOL Developers Group has developed a written specification document and associated software libraries to enable third-party developers to include SBOL in their workflow and software tools. As one way to improve productivity, SBOL encourages and facilitates the description and sharing of designs through libraries. By encouraging adoption of SBOL, authors also hope to improve the reproducibility of results in the field; if SBOL files are provided as supplementary material to journal articles, other researchers can more easily build on prior work. More broadly, SBOL contributes to the implementation of principled engineering for biological organisms through standardization of the information exchange.
_

Figure above shows Synthetic Biology Open Language (SBOL) standard visual symbols for use with BioBricks Standard.
_____
_____
Synthetic biology, Nanotechnology and Bionanoscience:
Nanobiotechnology, bionanotechnology, and nanobiology are terms that refer to the intersection of nanotechnology and biology. Nanotechnology refers to the scale at which a heterogeneous set of activities takes place. Nanotechnology, the engineering of systems at the molecular scale, though longer established than synthetic biology, is also one of the newer disciplines within science. While synthetic biologists may for strategic reasons want to avoid the public attention that has surrounded nanotechnology, insofar as synthetic biology occurs at the nanoscale, it would not be unreasonable to consider it a form of nanotechnology. The large global nanotechnology community (dominated by chemists, physicists and engineers) is eyeing what the European Union terms in vitro synthetic biology as a means of providing the “production facilities” for nanoscale fabrication. Already, nanoscientists are using viruses to construct battery parts. The molecular-scale motors and other machines that nanotechnology creates (or can envisage) have a self-evident relevance to any scientist in the business of synthesizing whole cells or other living systems. Such is the overlap between nanoscience and synthetic biology that attempts to define their respective boundaries are as difficult as they are futile. Bionanoscience is a forum for a rapidly growing sphere of research, emphasizing links among structure, properties and processes of nanoscale phenomena in biological, biomicking and bioinspired structures and materials for a range of engineered systems. Coverage of research includes experimental (imaging, design and synthesis, biotechnology and protein engineering), theoretical (statistical mechanics, nanomechanics, quantum mechanics) and computational (bottom-up multi-scale simulation, first principles methods, supercomputing) research.
_
DNA nanotechnology:
DNA nanotechnology uses the unique molecular recognition properties of DNA and other nucleic acids to create self-assembling branched DNA complexes with useful properties. In this field, nucleic acids are used as non-biological engineering materials for nanotechnology rather than as the carriers of genetic information in living cells. DNA is thus used as a structural material rather than as a carrier of biological information. DNA nanotechnology involves forming artificial, designed nanostructures out of nucleic acids, such as DNA tetrahedron. As a chemical polymer, DNA has several unique properties that make it intriguing. First, the compact helical form and simple base-pairing rules of double-stranded DNA allow us to consider DNA as a technology to reliably position atoms in three-dimensional (3D) space at nanometer resolutions. The emergence of DNA origami and single-stranded tiles to form complex 2D and 3D shapes has been used by researchers to tackle problems from materials to therapeutics. Base-pairing and strand-invasion properties of DNA have also allowed researchers to explore interesting information processing and computational capabilities using small libraries of oligos. Finally, direct encoding of digital information into DNA sequence has recently been shown to outpace most other technologies for data density in three dimensions. Nanomechanical devices and algorithmic self-assembly have also been demonstrated, and these DNA structures have been used to template the arrangement of other molecules such as gold nanoparticles and streptavidin proteins.
______
______
RNA synthesis and RNA synthetic biology:
In contrast to methods for synthesizing other biopolymers, RNA is usually synthesized without cells or cell extracts. Typically, research needs can be met by run-off transcription of synthetic oligos, PCR products, or linearized plasmids using coliphage T7 RNA polymerase, but there are limitations. RNA molecules play important and diverse regulatory roles in the cell by virtue of their interaction with other nucleic acids, proteins and small molecules. Inspired by this natural versatility, researchers have engineered RNA molecules with new biological functions. In the last two years efforts in synthetic biology have produced novel, synthetic RNA components capable of regulating gene expression in vivo largely in bacteria and yeast, setting the stage for scalable and programmable cellular behavior. Immediate challenges for this emerging field include determining how computational and directed-evolution techniques can be implemented to increase the complexity of engineered RNA systems, as well as determining how such systems can be broadly extended to mammalian systems. Further challenges include designing RNA molecules to be sensors of intracellular and environmental stimuli, probes to explore the behavior of biological networks and components of engineered cellular control systems.
ncRNA:
One of the most important discoveries of the last few years has been the identification of small, non-protein-coding RNAs (ncRNAs) that act as integral regulatory components of cellular networks. ncRNAs serve an astonishing variety of functions and thus play important roles in many intracellular processes, from transcriptional regulation, gene silencing, chromosomal replication, through RNA processing and modification, mRNA stability and translation, to protein degradation, and translocation, etc. In synthetic biology, ncRNAs have been shown to have advantages in circuit engineering. Orthogonally acting ncRNA regulators that work independently in the same cell have been used to engineer higher-order regulatory functions. Systematic identification and characterization of ncRNAs in genomes has become one of the most exciting challenges in cellular and development biology.
______
______
Protein engineering:
Protein engineering is the process of developing useful or valuable proteins. It is a young discipline, with much research taking place into the understanding of protein folding and recognition for protein design principles. It is also a product and services market, with an estimated value of $168 billion by 2017. There are two general strategies for protein engineering: rational protein design and directed evolution. In rational protein design, a scientist uses detailed knowledge of the structure and function of a protein to make desired changes. In general, this has the advantage of being inexpensive and technically easy, since site-directed mutagenesis methods are well-developed. However, its major drawback is that detailed structural knowledge of a protein is often unavailable, and, even when available, it can be very difficult to predict the effects of various mutations. Computational protein design algorithms seek to identify novel amino acid sequences that are low in energy when folded to the pre-specified target structure. While the sequence-conformation space that needs to be searched is large, the most challenging requirement for computational protein design is a fast, yet accurate, energy function that can distinguish optimal sequences from similar suboptimal ones. Computing methods have been used to design a protein with a novel fold, named Top7, and sensors for unnatural molecules. The engineering of fusion proteins has yielded rilonacept, a pharmaceutical that has secured Food and Drug Administration (FDA) approval for treating cryopyrin-associated periodic syndrome. In directed evolution, random mutagenesis is applied to a protein, and a selection regime is used to select variants having desired traits. Further rounds of mutation and selection are then applied. This method mimics natural evolution and, in general, produces superior results to rational design.
_
Protein engineering has always benefited from improvements in synthetic capabilities such as DNA shuffling, site-directed mutagenesis and low-cost gene synthesis. De novo synthesis, however, provides a more powerful tool to engineer new protein functions by taking advantage of computational design and metagenomic information. For example, Bayer et al. synthesized 89 methyl halide transferase enzymes found in metagenomic sequences from diverse organisms and showed large improvements in enzymatic activities. As another example, Kudla et al. and Quan et al. constructed and characterized libraries of reporter genes (154 and 1,468 genes, respectively) to study codon usage. More recently, another group has used oligo pools combined with multiplexed reporter assays to construct >14,000 reporter constructs and measured their transcriptional and translational rates to understand how N-terminal codon bias affects protein expression. Finally, the development of deep mutational scanning techniques to measure structure-function relationships in multiplex will enable rapid characterization of large designed synthetic gene libraries as synthesis methods improve.
_
SCOPE:
Structure-based combinatorial protein engineering (SCOPE) is a synthetic biology technique for creating gene libraries (lineages) of defined composition designed from structural and probabilistic constraints of the encoded proteins. The development of this technique was driven by fundamental questions about protein structure, function, and evolution, although the technique is generally applicable for the creation of engineered proteins with commercially desirable properties. Combinatorial travel through sequence spacetime is the goal of SCOPE.
__
SpyTag and SpyCatcher:
Protein engineers have adapted natural proteins that form covalent bonds to create ‘unbreakable’ peptide tags, including split inteins, sortase, transglutaminase and SpyTag/SpyCatcher. SpyTag is a short peptide that forms an isopeptide bond upon encountering its protein partner SpyCatcher. This covalent peptide interaction is a simple and powerful tool for bioconjugation and extending what protein architectures are accessible. Modifying and assembling proteins is a key challenge for our ability to explore and harness living systems. Bioconjugation allows us to study and manipulate the properties of proteins, for example by allowing tracking, interaction sensing or conferring improved therapeutic properties. Additionally, bioconjugation gives the ability to create novel devices and biomaterials for anything from energy harvesting and medical diagnostics to cancer cell capture or drug deliver.
_

Figure above shows generation, reaction and uses of SpyTag/SpyCatcher. (a) Cartoon of splitting CnaB2 into SpyCatcher (grey) and SpyTag (red). Residues forming the isopeptide are shown as sticks (based on PDB 2X5P and 4MLI) [30]. (b) Environment of the isopeptide bond between Asp117 (carbons orange) and Lys31 (carbons yellow), facilitated by Glu77 (carbons grey). (c) Discussed applications of SpyTag/SpyCatcher. (d) Reaction mechanism. Lys31 nucleophilically attacks Asp117, followed by proton transfers involving Glu77, leading to a neutral tetrahedral intermediate and then release of water and formation of the amide bond. SpyTag/SpyCatcher has now established itself as a simple route to covalent protein conjugation and is quickly finding application by a range of laboratories.
___
What is Synthetic Protein?
Synthetic proteins are man-made molecules that mimic the function and structure of true proteins. Proteins are central to life because they control almost all cellular processes, including initiating most of the reactions that occur in living cells. In early 2011, Princeton University scientists built the first artificial proteins capable of sustaining life in cells. Synthetic proteins have genetic sequences that are not seen in natural proteins. Building an artificial protein that can sustain life is significant because it proves the molecular parts needed for life are not limited to the proteins and genes found in nature. In nature, proteins are produced from the instructions that are encoded into cellular DNA. Researchers have long sought synthetic proteins that act like natural proteins for a range of biomedical applications, including therapeutic drugs that can be given orally because they won’t be degraded by enzymes. A protein’s identity and biological activity are dictated by its unique sequence of amino acids, which are the building blocks of protein. There are about 20 amino acids. Amino acids, in turn, contain atoms including hydrogen, carbon, nitrogen, oxygen and sulfur. Amino acids also can be synthetically made. The research at Princeton opens the door to the possibility of creating synthetic proteins that carry out the same functions as natural proteins. Princeton researcher Michael Fisher likens this to taking a sentence, changing the words and then testing the sentence to see if it retains its meaning despite the new words. The amino acid sequences in each protein dictate how the protein folds into a three-dimensional structure, which in turn affects the stability of the structure. Proteins must fold to function. Creating synthetic proteins may help researchers understand this biological process. Understanding this process may unlock the knowledge researchers need to understand conditions such as Alzheimer’s disease, as errant folding of proteins in your brain can lead to this condition. Understanding how proteins fold also may help researchers find compounds that will prevent errant folding of proteins. Researchers working on synthetic proteins also hope to understand why certain amino acid sequences are central to human existence. The human body produces about 100,000 different proteins. However, the Princeton research demonstrates that there is the potential for many more. The question of whether these 100,000 proteins are somehow special or whether evolution simply has not progressed to make more varieties remains unanswered. Creating synthetic proteins also may help researchers learn more about cell signalling and immune responses to pathogens, according to the University of Illinois.
_____
______
Tissue engineering:
_
Tissue engineering is the use of a combination of cells, engineering and materials methods, and suitable biochemical and physicochemical factors to improve or replace biological tissues. Tissue engineering involves the use of a scaffold for the formation of new viable tissue for a medical purpose. While it was once categorized as a sub-field of biomaterials, having grown in scope and importance it can be considered as a field in its own. While most definitions of tissue engineering cover a broad range of applications, in practice the term is closely associated with applications that repair or replace portions of or whole tissues (i.e., bone, cartilage, blood vessels, bladder, skin, muscle etc.). Often, the tissues involved require certain mechanical and structural properties for proper functioning. The term has also been applied to efforts to perform specific biochemical functions using cells within an artificially-created support system (e.g. an artificial pancreas, or a bio artificial liver). The term regenerative medicine is often used synonymously with tissue engineering, although those involved in regenerative medicine place more emphasis on the use of stem cells or progenitor cells to produce tissues.
_
Application of Synthetic Biology to Regenerative Medicine:
Traditional efforts in regenerative medicine have always depended on using the natural, evolved behaviours of human cells. The earliest to be exploited were those concerned with wound healing and with tissue engraftment: together, these form the basis of reconstructive surgery, whether this is routine skin grafting or highly experimental transplantations of a hand or even a face. From the middle of the last century, first researchers and then clinicians began to exploit an additional feature of the normal body, the ability of stem cells to regenerate missing tissue. Use of stem cells from bone marrow to reconstitute the haematopoietic system was achieved in the 1950s in both rodents and humans: it has since become a relatively routine procedure following treatment for leukaemia or following accidental exposure to ionizing radiation. This century, the range of stem cell treatments has expanded greatly, at least in the experimental phase, and includes treatment with a variety of stem cells (including mesenchymal, perivascular, endothelial, neuronal, embryonic and limbal) with the aim of treating diseases such as diabetes, paraplegia, ataxia, multiple sclerosis, and heart failure. So far, the clinical outcomes of most early trials have been disappointing, although the increasing commitment of industry to exploring this field suggests that optimism is far from lost. In all cases, though, the aim has been to use the natural abilities of cells to make trophic factors and to produce new tissues as they would in normal development and tissue maintenance. An even more recent development has been the idea of engineering ‘scaffolds’, either wholly artificial or made by manipulation of natural molecules or mixtures of artificial and natural molecules, to guide cells to make tissues with specific shapes. Examples include the formation of a collagen pattern in the shape of a human nipple, the formation of functional heart valves, reconstruction of cartilage, bone, oesophagus and bladder wall. In a variation on that theme, the engineering of structures that already incorporate cells in situ has been used to produce functional heart tissue. Natural, de-cellularized scaffolds obtained by detergent washing matrices of natural organs have also been used successfully for tissue engineering. The possibility of engineering a matrix that has a shape different from that of any natural tissue allows some creativity, but the actions of the cells themselves are still controlled by their evolved ‘developmental programmes’. This fact imposes a significant limitation on the scope of conventional tissue engineering. It is in liberating the field from this limitation that the potential of synthetic biology lies. Synthetic biology uses interchangeable and standardized “bio-parts” to construct complex genetic networks that include sensing, information processing and effector modules: these allow robust and tunable transgene expression in response to a change in signal input. The rise of this field has coincided closely with the emergence of regenerative medicine as a distinct discipline. Unlike synthetic biology, regenerative medicine uses the natural abilities of cells to make trophic factors and to produce new tissues as they would in normal development and tissue maintenance.
There are four main areas in which the techniques of synthetic biology might be applied to promote regeneration;
- Biosynthesis and controlled release of therapeutic molecules
- Synthesis of scaffold material
- Regulation of stem cells
- Programming cells to organize themselves into novel tissues.
_______
_______
Synthetic biology projects (SBPs) in vivo and in vitro:
The basic elements of chemistry and biology are few, but the synthetic combinations are unlimited and awe inspiring. The first international conference on synthetic biology charted its goals as understanding and utilizing life’s diverse solutions to process information, materials, and energy. As a bonus, genetic systems are biocompatible, renewable, and can be optimized by Darwinian selections. SBPs entail the complex manipulation of replicating systems, ranging from the sophisticated genetic engineering of organisms to the chemical synthesis of unnatural replication. It thus seems appropriate to divide synthetic biology into two classes, in vivo and in vitro. Of the current SBPs, the in vivo ones have received more coverage in the literature, perhaps because of safety concerns and the obviousness of scalability.
____
In vivo SBPs:
In vivo SBPs mostly involve bacterial engineering, have diverse goals, and are generally more suited than in vitro SBPs for large-scale production/conversion of materials. Neobiotic constructions with new functions now encompass redesigned metabolic pathways for pollution remediation and for synthesis of drugs and plastics. Multiplex regulatory circuits have been pieced together to test theories of pathway control, alter phenotypes, and generate biosensors. Significant reduction (15%) of a bacterial genome has proved possible by leveraging a very small number of deletion oligodeoxyribonucleotides (oligos) to reduce recombination and increase electroporation efficiency. System designs can be combinatorial or modular, inspired by electronic circuits, although not intended to replace them. Even the parts themselves can be redesigned: e.g., Escherichia coli and yeast have been endowed with expanded genetic codes by engineering an orthogonal suppressor tRNA/aminoacyl-tRNA synthetase/unnatural amino acid triple; this will lead to new pharmaceuticals. In contrast to in vitro SBPs, some in vivo SBPs require strict safety regulations. The synthesis of poliovirus from oligos heralded not only designer viruses/cells for vaccines and gene/cell therapies, but also new dangers. This stimulated an action plan to regulate world suppliers of DNA synthesizers, DNA precursors, and oligos. Ethical and safety issues have been, and must continue to be, regulated. Several groups have proposed to create bacteria with chromosomes synthesized entirely from synthetic oligos. This might be done stepwise or by inactivating the endogenous bacterial chromosome and then somehow transforming and rebooting the bacterium with an entire in vitro-synthesized genome. One goal is to test theories of the minimum number of genes required for bacterial replication. This exploits lists of indispensable genes of a minimal Mycoplasma bacterium. A major hurdle is that dispensability of single genes does not assure viability of combinations of deletions (e.g., pairwise synthetic lethals). A second goal is to synthesize bacteria with genomes that are globally mutated rather than severely truncated. Several specific applications can be envisioned. For example, freeing up of certain codons would facilitate extending the code with unnatural amino acids. Replacing all 378 UAG stop codons of E. coli with UAA stop codons might allow deletion of release factor 1 (RF1), thereby enabling insertion of an unnatural amino acid at a plasmid-encoded UAG codon without competition from RF1 or chromosomal UAG codons. Global switching of nonsynonymous codons should prevent functional exchanges of genetic material with natural species, decreasing the chance of environmental contamination.
__
In vitro SBPs:
Time and again, decreasing the dependence on cells has increased engineering flexibility with biopolymers and self-copying systems. For example, evolution has been engineered in vitro using very alien designs that accelerate selection of almost any imaginable molecular function. Decreasing dependence on cells also facilitates increased understanding. The increased engineering flexibility and understanding that will emerge if replication can be completely weaned from cells is enticing. Though this may seem inevitable, it is sobering to remember that polymerase synthesis requires a translation apparatus that is dependent for its construction and function on more than 100 macromolecules, many of which are post-transcriptionally modified. Many biopolymer syntheses are already better scaled up in cell-free systems, such as linear DNAs by oligo synthesis and PCR, unmodified RNAs by in vitro transcription, and peptide libraries by in vitro transcription/translation. And engineering flexibility is much greater in vitro, unshackled from cellular viability, complexity, and walls. One promise of in vitro SBPs is applications. Current in vitro methods for synthesizing proteins and evolving protein, nucleic acid, and small-molecule ligands will be improved to accelerate production of new reagents, diagnostics, and drugs. New methods will be developed for synthesizing circular DNAs, modified RNAs, proteins containing unnatural amino acids, and liposomes. The other promise of in vitro SBPs is basic knowledge. Until we can assemble a form of life in vitro from defined, functionally understood macromolecules and small-molecule substrates, how can we say that we understand the secret of life?
______
Cell-free synthetic biology:
An alternative and emerging field is cell-free biology, which is defined as the “activation of complex biological processes without using intact living cells”. Cell-free systems provide an unprecedented and otherwise unattainable freedom of design to modify and control biological systems. It features the ability to focus on production of a single compound without physical barriers, facilitates substrate addition, product removal and rapid sampling, provides direct access to reaction conditions, and utilises the entire reactor volume. This approach transforms crude cell lysates into “factories” with commercial potential for making pharmaceutical proteins and biomolecules. Another advantage is that there is no conflict between microbial growth and engineering design objectives. The most prominent example is cell-free protein synthesis (CFPS), which allows for the synthesis of proteins containing non-natural amino acids. Major application-oriented advantages of cell-free systems are that gene expression of multiple products may be tuned to facilitate proper product interactions, reaction and product stability may be optimised by adjusting DNA template concentrations and controlling the redox potential for optimal disulphide bond formation, the possibility for recombinant expression of toxic proteins, and the production of complex biocatalysts. They overcome inherent limitations of living cells, enable control of gene expression, chassis optimisation, in situ monitoring, and automation. This new paradigm will enable a deeper understanding of why nature’s designs work as they do, and open the way to novel therapeutics, sustainable chemicals, and new materials that have been impractical, if not impossible, to produce by other means. Cell-free systems are used to develop new reaction pathways that significantly increase productivity, e.g. to microbe-based systems. It also allows for the faster and more predictable development of modular gene circuits, as control of reaction environment and components, and access to the reaction is greatly facilitated – applications are the engineering of minimalistic artificial cells and cell-like microdevices.
_
Comparison of in vitro cell-free systems and traditional in vivo cell systems:
| Feature | In vitro cell-free system | In vivo cell system |
| Manipulation of transcription and translation | Easy to control in an open environment | Hard because of cell membrane as the barrier |
| Post-translational modification | Hard | Easy |
| Self-replication | Hard | Easy |
| DNA template | Plasmids or PCR products | Plasmids or genomes |
| Synthesis of membrane proteins and complex proteins | Easy synthesis by adding surfactants or adjusting the system environment | Hard synthesis due to limited intracellular environment |
| Incorporation of unnatural amino acids into proteins | Easy | Hard |
| Ability to only produce the desired products | Easy achievement by focusing on the target metabolic pathways | Hard achievement due to complicated cellular metabolism |
| Toxic tolerance | High | Low |
| Integration with materials | Easy | Hard |
| Design-build-test-learn cycle | Two days | Two weeks |
| Biomanufacturing | High production rate | Modest production rate |
| High product yield | Modest product yield | |
| Easy purification process without cell lysis | Cell lysis prior to product purification | |
| Cost | Modest to high | Low to modest |
_
Benefits of cell-free synthetic biology:
Divorcing biological production from living things makes sense, for three reasons.
- The first is efficiency. Living organisms are shaped by evolution to survive and reproduce. That wastes energy. Consider insulin made in vats of genetically modified yeast or bacteria. Those bacteria use valuable nutrients to build a host of other proteins besides insulin which are vital for their own survival but worthless to humans. With cell-free biology, more of those nutrients could be turned into the end-product that is being produced.
- Living creatures are also irritatingly fragile. Genetically engineered bacteria can be used, for instance, to make a fuel called isobutenol. But it is a solvent, and kills the bacteria before they can make very much. A cell-free system is more robust. The second benefit of cell-free biology is that it has the potential to avoid some of the social and environmental drawbacks associated with relying on living organisms.
- The third reason is ethical. Animals have a capacity for suffering that the cellular machinery from which they are built does not.
_
Mammalian Synthetic biology:
In recent years, the promise of engineered mammalian cell-based devices has been heralded by breakthroughs in the treatment and potentially cures of some cancers. To extend these successes to a range of diseases and applications, we need to develop novel platforms and therapeutic strategies based upon custom-programming novel cellular functions — a capability that is beyond the reach of current approaches. Ultimately, realizing the full potential of synthetic biology to impact medicine may include engineering varied biological systems to interface with our mammalian biology in a manner that is programmable and beneficial.
_
Platform cell factories:
Synthetic biology and metabolic engineering interact to turn living cells into microbial factories used in industrial biology. The aim is to have a limited number of “platform cell factories” available to produce a wide range of fuels and chemicals. A major advantage of such platform is that it may be used to insert many different synthetic pathways. For example, a platform cell factory may be created such that it produces an important precursor metabolite for many products, e.g. acetyl Co-A for the production of polyketides (antibiotics, anticancer drugs and immunosuppressors), lipids (dietary supplements, pharmaceuticals and biodiesels) and isoprenoids (perfumes, biodiesels, antimalarial drugs, antibiotics, rubber, dietary supplements, food ingredients and vitamins).
_____
Biohacker and Biohacking:
We all know who a hacker is. A hacker is an intruder in the digital world. Then who is a biohacker? Someone who hacks into biological networks? Apparently, that’s partially true. However, unlike the term hacker, biohacker has more positive connotations. If you try to look at the term biohacker within the light of your understanding of the term hacker, the former term may appear to be more of a misnomer because in reality there’s nothing illegal about biohacking, at least not yet! Biohacking is a relatively new practice which involves ordinary people exploring biology in personal laboratories. It is often called do-it-your-self biology. But the concept is highly interesting. Biohacking gives you a freedom to explore biology, kind of like you would explore good fiction. Don’t get the wrong idea that it is directionless amateur biology. Biohackers are not confined to doing basic biological experiments; they explore advanced biological considerations like the complex DNA and how different genetic make-ups affect the growth and functioning of different living beings. Biohacking can also apply to the use of advanced IT for hydroponic plant systems or other projects that apply IT concepts to biological organisms. Biohacking can also include body modifications, in which groups of people known as “grinders” experiment with implants and other methods of applying technologies to their bodies, such as wearable computing.
_____
_____
Research examples of synthetic biology:
_
Cancer treatment:
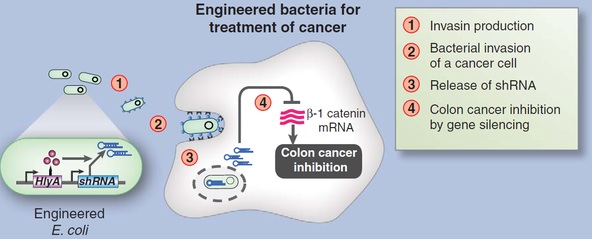
A lab at UCSF programmed E. coli to invade mammalian cells under hypoxic conditions, a rough tumor indicator. A different study improved on this by programming the invading E. coli to silence a colon cancer gene (CTNNB1), inhibiting tumor growth. The E. coli express a small RNA molecule that binds to the CTNNB1 mRNA, marking it for destruction. Human colon cancer cells grafted under the skin of lab mice were effectively targeted by injecting the engineered E. coli, an intriguing early step.
_
Prevent cholera:
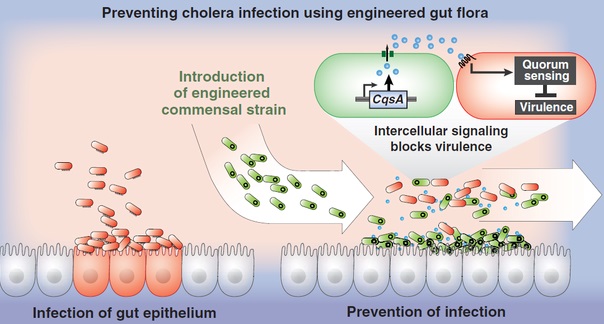
A study called on E. coli in their usual environment: the intestines. The authors programmed E. coli to produce signalling molecules recognized by Vibrio cholerae, the bacterium that causes cholera. These signalling molecules prevent the V. cholerae bacteria from producing toxins that cause infection. Mice fed the reprogrammed E. coli were much more likely to survive a subsequent V. cholerae exposure.
_
Destroy biofilms:
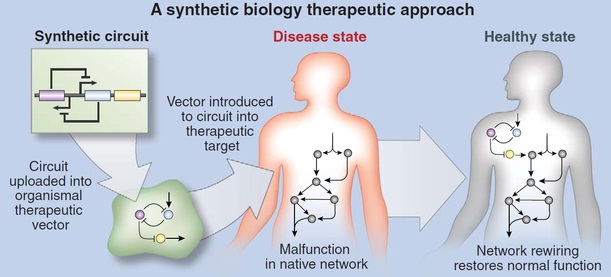
Bacteria and the human body are both friend and foe. Some bacteria conspire against us to cause severe illness; others live harmlessly inside us, even playing crucial roles in maintaining our health. Perhaps the most pressing challenge in our fight against pathogens is the arms race between modern medicine and antibiotic resistant bacteria. Ordinary natural selection, aided by poor healthcare management and patient noncompliance, has created a global crisis where pathogens are evolving resistance to our treatments. Enter the engineered bacteriophage, variations on viruses that infect only specific bacteria. Persistent bacterial infections hide themselves inside a mucous-like protective coat called a biofilm. A bacteriophage can be engineered to force infected bacteria to do two things. The first is, on infection, to quickly produce large quantities of new virus, burst open and die. This kills the bacterium, helping to reduce the infection and spread the virus rapidly to the remaining bacteria. The virus itself poses no risk to human health. The second is to produce an enzyme that breaks down the biofilm, exposing the bacteria to both antibiotics and the body’s immune system. Investigators successfully engineered the T7 phage, a virus that infects E. coli, to degrade biofilms. The viruses invade E. coli cells and hijack their protein synthesis machinery, churning out viral proteins. The engineered version of T7 also contains a gene coding for the enzyme DspB, a molecular wrecking ball that destroys biofilm. Lab tests showed this eventually killed 99.997% of biofilm bacteria. Another study produced bacteriophages that, once inside an infected bacterium, turned off the mechanisms that protect it from antibiotics. Treating E. coli infected mice with both antibiotics and the engineered bacteriophage resulted in an 80% survival rate, compared to 20% with antibiotics alone.
_
Application of synthetic biology in cyanobacteria and algae: a 2012 study:
Owing to the relatively simple genetic contents and the ability to capture solar energy, fix CO2, grow fast and directly synthesize specific products, cyanobacteria and algae have become excellent candidates for building autotrophic cell factories to produce renewable surrogate fuels and chemicals. With a large pool of genome sequences and improved genetic tools being available, application of synthetic biology in these photosynthetic microorganisms are highly desirable. In recent years, exciting results have been achieved not only in understanding of the fundamental molecular mechanisms but also in producing various interest products, such as biofuels and chemicals, utilizing cyanobacteria and algae as the production platforms. Nevertheless, synthetic biology in cyanobacteria and algae is still in its infancy and synthetic biologists are facing great challenges and opportunities in addressing various issues, such as improving the tools for genetic manipulation, enhancing light harvesting, increasing CO2 fixation efficiency, and overcoming of the intracellular oxidative stress.
_
Bacteriophages use an expanded genetic code on evolutionary paths to higher fitness: a 2014 study:
The evolution of life on Earth has been dictated by the underlying constancy of the nearly universal twenty amino acid genetic code. However, examples of natural genetic codes that have been functionally expanded with a 21st amino acid and the multitude of known post-translational protein modifications suggest that, while aspects of the genetic code have been optimized by evolution, it does not provide the necessary chemical diversity to best perform all functions of potential benefit to organisms. Technologies exist to augment genetic codes with a non-canonical amino acid (ncAA) by introducing an orthogonal aminoacyl-tRNA synthetase (aaRS) and a cognate tRNA recognizing the amber stop codon. Authors hypothesized that organisms given the ability to encode a 21st amino acid would evolve to utilize this new chemical building block on mutational pathways to higher fitness. Bioengineering advances have made it possible to fundamentally alter the genetic codes of organisms. However, the evolutionary consequences of expanding an organism’s genetic code with a non-canonical amino acid are poorly understood. Here authors show that bacteriophages evolved on a host that incorporates 3-iodotyrosine at the amber stop codon acquired neutral and beneficial mutations to this new amino acid in their proteins, demonstrating that an expanded genetic code increases evolvability.
_
Synthetic biology of fungal natural products (NPs): a 2015 review:
Microorganisms are a treasure trove of NPs and the potential has just been realized with the beginning of the genomics era. Concerning the synthetic biology aspects of NP research much has also been done in the model organism Saccharomyces cerevisiae because of its vast toolkit in making different genomic manipulations. But filamentous fungi also hold the potential as organisms that can be used in the field of synthetic biology to essentially control the production of NPs. Whether looking at it from the perspective of novel products or optimizing production conditions of known bioactive molecules, fungi have proven their own potential as work horses in the field of NP research. From the vast array of different NPs produced to the ease for genetic manipulation, filamentous fungi have proven to be an invaluable source for the further development of synthetic biology tools. Synthetic biology for the discovery and understanding of fungal NPs is an ever-evolving field. With the advancement of the different techniques the possibilities are endless for the production of novel/bioactive NPs. Additionally, with the rapid discovery in different genome editing and genetic manipulation tools such as the bacterial derived CRISPR-Cas9 system, these could also be applied to filamentous fungi to further expand the toolbox for the next new NPs. Moreover, other efforts must be done in order to create an organism with a minimal genome. This would mean for an organism to display reduced genome complexity and be engineered to have all the necessary production chassis for NP production. Filamentous fungi harness the capacity to produce a multitude of different NPs, they just need to be discovered.
_
Synthetic biologists engineer inflammation-sensing gut bacteria: a 2017 study:
Synthetic biologists at Rice University have engineered gut bacteria capable of sensing colitis, an inflammation of the colon, in mice. The research points the way to new experiments for studying how gut bacteria and human hosts interact at a molecular level and could eventually lead to orally ingestible bacteria for monitoring gut health and disease. Sensor bacteria have evolved tens of thousands of genetically encoded sensors, many of which sense gut-linked molecules. Thus, genetically engineered sensor bacteria have tremendous potential for studying gut pathways and diagnosing gut diseases. The idea was to use sensor bacteria, in this case an engineered form of Escherichia coli, to sense thiosulfate and related sulfur-containing compounds that may also be biomarkers of colitis. There were well-understood methods for programming E. coli to produce a fluorescent green protein in response to specific stimuli, but there were no known genes—in any organism—that were used to sense thiosulfate, and few for the other compounds. Researchers spent one year engineering E. coli to express the sensor genes, validate their function and optimize them to respond to the potential biomarkers by producing a green fluorescent protein signal. It took another year to prove that the system worked and detected colon inflammation in mice. The researchers administered orally two drops containing about a billion sensor bacteria to both healthy mice and to mice with colitis. They measured the activity of the sensor bacteria in each group six hours later. The tell-tale green fluorescent protein showed up in the feces of the mice. Though it was not visible to the unaided eye, it could easily be measured with a standard laboratory instrument called a flow cytometer. The team found that the thiosulfate sensor was activated in the mice with inflammation, and was not activated in the healthy mice. Furthermore, the researchers found that the more inflammation the mouse had, the more the sensor was activated. The study shows that gut bacteria can be outfitted with engineered sensors and used to noninvasively measure specific metabolites and that this result could open the door to many new studies that could help elucidate a wide range of gut processes.
_
Engineered Cells treat Diabetic Mice: a 2017 study:
In a sweet new pair of papers, Martin Fussenegger’s lab at ETH Zurich has used two different synthetic biology approaches to dynamically correct both type 1 and type 2 diabetes in mice. In both papers, researchers engineered synthetic gene circuits into human kidney cells (HEK293), embedded them in alginate micro-beads, and implanted the combination into diabetic mice.
- Anti-Diabetes Circuit One: Glucose + Calcium → Insulin or GLP1
In the first paper, a team led by Mingqi Xie coupled calcium signalling induced by high glucose to secretion of insulin or GLP1. To do this in kidney cells, they first had to insert the gene for a voltage-gated calcium channel, Cav1.3. When blood glucose is high, this channel opens, causing an influx of calcium. Next, they found an engineered, calcium-sensitive promoter to drive gene expression when intracellular calcium was high. For type 1 diabetic mice, they made the cells produce insulin, and for type 2 diabetic mice, they produced the therapeutic protein GLP1. In both cases, the implanted, engineered cells lowered the mice’s persistent high blood sugar and improved glucose homeostasis in response to a meal. Importantly, modelling and experiments showed that the treatment was safe, with minimal danger of an insulin overdose.
- Anti-Diabetes Circuit 2: Insulin → Adponectin
Haifeng Ye made another synthetic gene circuit to correct the insulin resistance in type 2 diabetes. This strategy took advantage of the MAPK pathway that naturally responds to insulin. The key innovation for this dish was a fusion between ELK1 (a component of the insulin response pathway) and TetR, a non-native transcription factor. When insulin is high, the hybrid transcription factor activates expression of adiponectin, a natural hormone that increases the body’s insulin sensitivity. Again, following transplantation of engineered cells into type 2 diabetic mice, they kept blood sugar in check. As a final aperitif, diabetic mice with these engineered implants even ate less and lost weight!
____
Highly oriented photosynthetic reaction centers generate a proton gradient in synthetic protocells: a 2017 study:
Photosynthesis is responsible for the photochemical conversion of light into the chemical energy that fuels the planet Earth. The photochemical core of this process in all photosynthetic organisms is a transmembrane protein called the reaction center. In purple photosynthetic bacteria a simple version of this photoenzyme catalyzes the reduction of a quinone molecule, accompanied by the uptake of two protons from the cytoplasm. This results in the establishment of a proton concentration gradient across the lipid membrane, which can be ultimately harnessed to synthesize ATP. Herein authors show that synthetic protocells, based on giant lipid vesicles embedding an oriented population of reaction centers, are capable of generating a photoinduced proton gradient across the membrane. Under continuous illumination, the protocells generate a gradient of 0.061 pH units per min, equivalent to a proton motive force of 3.6 mV⋅min−1. The photosynthetic reaction center (RC), an integral membrane protein at the core of bioenergetics of all autotrophic organisms, has been reconstituted in the membrane of giant unilamellar vesicles (RC@GUV) by retaining the physiological orientation at a very high percentage (90 ± 1%). Owing to this uniform orientation, it has been possible to demonstrate that, under red-light illumination, photosynthetic RCs operate as nanoscopic machines that convert light energy into chemical energy, in the form of a proton gradient across the vesicle membrane. This result is of great relevance in the field of synthetic cell construction, proving that such systems can easily transduce light energy into chemical energy eventually exploitable for the synthesis of ATP. Remarkably, the facile reconstitution of the photosynthetic reaction center in the artificial lipid membrane, obtained by the droplet transfer method, paves the way for the construction of novel and more functional protocells for synthetic biology.
_
In vivo Gene Editing on the Brain: a 2017 study:
A new Nature Biotechnology study from the lab of Jennifer A Doudna has described a major step toward the in vivo application of CRISPR-Cas9-mediated gene editing to correct the genetic causes of neurological diseases. One major problem is how to deliver Cas9 constructs to the desired tissue, as the application of viral vectors or plasmids encoding Cas9 can lead to integrational mutagenesis, detrimental immune responses caused by persistent expression, and off-target activity. To avoid these problems, Staahl et al have created a non-genetically encoded, preassembled, and short-lived Cas9 ribonucleoprotein (RNP) complex targeted for cell penetration thanks to the addition of an optimized pattern of Simian vacuolating virus 40 (SV40) nuclear localization sequences. Initial assessments employed neural stem cells and terminally differentiated neurons carrying a fluorescent reporter gene silenced by the inclusion of a stop cassette. Treatment with the engineered Cas9 RNP complex and a guide RNA targeting the stop cassette led to reporter gene expression in both cell types and provided proof-of-concept to move this gene-editing strategy in vivo into a reporter mouse model. The authors injected the same Cas9-guide RNA RNP complex into the adult mouse hippocampus, striatum, and cortex and assessed gene editing and reporter gene expression after 12–14 days. Excitingly, they observed high levels of reporter gene expression in diverse neuronal subtypes in all regions tested, with no signs of an innate immune response. However, the Cas9 RNP complex did not target the reporter stop cassette in astrocytes, an abundant support cell present in the brain, suggesting that engineered RNPs exhibit preferential neurotropism, a characteristic that may prove advantageous in future cell-specific applications. This study has discovered that having CRISPR-Cas9 on the brain can produce exciting new results. Engineered Cas9 RNP complexes promise to contribute greatly to tissue-specific editing and to help construct effective in vivo therapeutic applications.
_______
_______
Challenges in synthetic biology:
_
Overview of Challenges in Synthetic Biology:
- Scientific:
- Orthogonality in Biological Systems
- Knowledge of intrinsic properties and functioning of the parts, devices and systems involved
- Accounting for evolution
- Technological:
- Adapt current protocols for scope and scale in SynBio
- Availability of parts and devices
- Organizational:
- Critical mass of practitioners adopting the ‘ethos’
- IP issues
- Societal:
- Ethical, Legal, Social, Safety, Security, Governance
____
Major Challenges in synthetic biology:
Can engineering approaches tame the complexity of living systems?
The complexity of biology is challenging on two levels. First, interactions of synthetic components with endogenous players in different pathways within a given cell are inevitably a problem. Modern technologies that look at large ensembles of molecules, such as DNA arrays, proteomics and metabolomics, help us to understand how pathways are connected to one another. However, the introduction of a synthetic pathway may accidentally set off different pathways. Then there is the interaction of the engineered entity with the mammalian system. Researchers are just coming to grips with the complexities of human systems. They still do not understand the dynamics of systems biology. They do not even understand the differences among humans in terms of genome. If you want to implant something which interfaces with a very complex system, this is very difficult. Synthetic biology tools currently developed may get lost in the noise of complex systems. Molecular biologists can’t always predict outcomes of genetic manipulations. If the outcome of a simple genetic manipulation can’t be predicted with certainty, it’s going to be very difficult to predict the outcome of a complex engineered biological system within a human.
_
To read some accounts of synthetic biology, the ability to manipulate life seems restricted only by the imagination. Researchers might soon program cells to produce vast quantities of biofuel from renewable sources, or to sense the presence of toxins, or to release precise quantities of insulin as a body needs it — all visions inspired by the idea that biologists can extend genetic engineering to be more like the engineering of any hardware. The formula: characterize the genetic sequences that perform needed functions, the ‘parts’, combine the parts into devices to achieve more complex functions, then insert the devices into cells. As all life is based on roughly the same genetic code, synthetic biology could provide a toolbox of reusable genetic components — biological versions of transistors and switches — to be plugged into circuits at will. Such analogies don’t capture the daunting knowledge gap when it comes to how life works and the difficulties multiply as the networks get larger, limiting the ability to design more complex systems. A 2009 review showed that although the number of published synthetic biological circuits has risen over the past few years, the complexity of those circuits — or the number of regulatory parts they use — has begun to flatten out. Challenges loom at every step in the process, from the characterization of parts to the design and construction of systems. There’s a lot of biology that gets in the way of the engineering.
_
- Designer cells can evolve in unpredictable ways:
As helpful as evolution has been for actual life in the real world, life’s ever-changing nature is annoying if you’re trying to engineer life to become a predictable tool. Here’s why: cells acquire random mutations in their DNA. And some cells will produce more offspring than others or completely die off. The result is that every new generation is slightly different than the one before. That can be an annoyance if, say, you are trying to design cells to perform a specific task in a pharmaceutical factory.
_
- Cells are very messy:
Cells are far more disorganized than a circuit board or computer program. The elements of a circuit board can be lined up in a precise order so that the output of one element can be funnelled straight into the input of the next. But a cell is an altogether messier situation. The molecules in a cell, including those that people are using as inputs and outputs, are generally lumped together in the same space and — literally — jiggling around randomly. So there’s a way higher chance of something cross-reacting, and that can cause problems.
_
- Mammals’ cells are difficult:
Cells from more complex creatures, like mammals, tend to be far more difficult to engineer than, say, bacteria. Mammals’ cells, for example, usually have two copies of each gene in a cell, whereas bacteria generally have one. Also, the processes that regulate what genes get used are more multilayered and complicated. And inserting and deleting genes in mammals’ cells is also far more difficult.
_
- Many of the parts are undefined:
A biological part can be anything from a DNA sequence that encodes a specific protein to a promoter, a sequence that facilitates the expression of a gene. The problem is that many parts have not been characterized well. They haven’t always been tested to show what they do, and even when they have, their performance can change with different cell types or under different laboratory conditions. The Registry of Standard Biological Parts, which is housed at the Massachusetts Institute of Technology in Cambridge, for example, has more than 5,000 parts available to order, but does not guarantee their quality. The registry has been stepping up efforts to improve the quality by curating the collection, encouraging contributors to include documentation on part function and performance, and sequencing the DNA of samples of parts to make sure they match their descriptions. Measurements are tricky to standardize, however. In mammalian cells, for example, genes introduced into a cell integrate unpredictably into the cell’s genome, and neighbouring regions often affect expression. This is the type of complexity that is very difficult to capture by standardized characterization.
_
- The circuitry is unpredictable:
Even if the function of each part is known, the parts may not work as expected when put together. Synthetic biologists are often caught in a laborious process of trial-and-error, unlike the more predictable design procedures found in other modern engineering disciplines. Computer modelling could help reduce this guesswork. Using computer modelling techniques, researchers could optimize computationally rather than test every version of a network. But designs might not have to work perfectly: imperfect ones can be refined using a process called directed evolution.
_
- The complexity is unwieldy:
As circuits get larger, the process of constructing and testing them becomes more daunting. A system developed by Keasling’s team, which uses about a dozen genes to produce a precursor of the antimalarial compound artemisinin in microbes, is perhaps the field’s most cited success story. Keasling estimates that it has taken roughly 150 person-years of work including uncovering genes involved in the pathway and developing or refining parts to control their expression. For example, the researchers had to test many part variants before they found a configuration that sufficiently increased production of an enzyme needed to consume a toxic intermediate molecule. People don’t even think about tackling those projects because it takes too much time and money. To relieve similar bottlenecks, an automated process is developed to combine genetic parts. The parts have pre-defined flanking sequences, dictated by a set of rules called the BioBrick standard, and can be assembled by robots. At Berkeley, synthetic biologist J. Christopher Anderson and his colleagues are developing a system that lets bacteria do the work. Engineered E. coli cells, called ‘assembler’ cells, are being equipped with enzymes that can cut and stitch together DNA parts. Other E. coli cells, engineered to act as ‘selection’ cells, will sort out the completed products from the leftover parts. The team plans to use virus-like particles called phagemids to ferry the DNA from the assembler to the selection cells. Anderson says that the system could shorten the time needed for one BioBrick assembly stage from two days to three hours.
_
- Many parts are incompatible:
Once constructed and placed into cells, synthetic genetic circuits can have unintended effects on their host. Even a simple circuit, comprising a foreign gene that promoted its own expression, could trigger complex behaviour in host cells. When activated in E. coli, the circuit slowed down the cells’ growth, which in turn slowed dilution of the gene’s protein product. This led to a phenomenon called bistability: some cells expressed the gene, whereas others did not. To lessen unexpected interactions, researchers are developing ‘orthogonal’ systems that operate independently of the cell’s natural machinery. Another solution is to physically isolate the synthetic network from the rest of the cell.
_
- Variability crashes the system:
Synthetic biologists must also ensure that circuits function reliably. Molecular activities inside cells are prone to random fluctuations, or noise. Variation in growth conditions can also affect behaviour. And over the long term, randomly arising genetic mutations can kill a circuit’s function altogether.
_
- Cells are not exactly digital:
Though incredibly powerful as a guiding framework for designing, building, and testing genetic circuits, the digital circuit metaphor has limits. Biological systems differ from electronic ones in fundamental ways, and modelling genetic regulation remains under determined. Synthetic biology researchers continue to incorporate new ideas and theories to describe, model and predict genetic circuit behaviors. A new and promising area utilizes analogies to analog circuitry.
_
- Expensive and unreliable research process:
Presently, Synthetic Biology is an expensive and unreliable research process. It is expensive because DNA synthesis is quite expensive. For example the bacteria Mycoplasma genitalium has the smallest genome out of all living cells. It consists of just 517 genes, totalling to 580 kb. Taking the current average price of gene synthesis as $1 per base pair, it would take 5.8 million dollars to synthesize just a minimal living entity. So, currently, mass production of applications based on Synthetic Biology is not yet feasible through artificial DNA synthesis. Synthetic Biology might prove unreliable because unlike components used in other engineering approaches, the behavior of biological components such as DNA, protein, etc. is affected even by slight modifications in the internal or external environment of the cell. Apart from the piece of machinery working for the application there are numerous other components, which are vital for the survival of living cells, and these may interfere with the normal functioning of genetic circuit, hence rendering the internal environment unpredictable. Thus, Synthetic Biology has to cope with the inherent randomness inside the cell. Unreliability also arises because unlike electronics there are no wires in the cell. A signal meant for one part of biological system may affect the other part. For example, if a biological system consists of 3 different inverters, then the signal meant for 1st inverter may diffuse inside the cell and affect the 2nd and 3rd inverters directly. This may trigger inappropriate responses.
_
Although synthetic biologists have accomplished a great deal in a short time, major obstacles remain to be overcome before the practical applications of the technology can be realized. One problem is that the behavior of bioengineered systems remains “noisy” and unpredictable. Genetic circuits also tend to mutate rapidly and become nonfunctional. Drew Endy of M.I.T., one of the pioneers in the field, believes that synthetic biology will not achieve its potential until scientists can predict accurately how a new genetic circuit will behave inside a living cell. He argues that the engineering of biological systems remains expensive, unreliable, and ad hoc because scientists do not understand the molecular processes of cells well enough to manipulate them reliably. Writing in Nature in late 2005, Endy suggested three strategies for overcoming these obstacles. The first, standardization, refers to the “promulgation of standards that support the definition, description and characterization of the basic biological parts, as well as standard conditions that support the use of parts in combination and overall system operation.” The M.I.T. Registry of Standard Biological Parts is a first step toward that end. The second, decoupling, is the effort to “separate a complicated problem into many simpler problems that can be worked on independently, such that the resulting work can eventually be combined to produce a functioning whole.” Finally, abstraction is a method for organizing information describing biological functions into “hierarchies” that operate at different levels of complexity. Following these strategies, Endy writes, “would help make routine the engineering of synthetic biological systems that behave as expected”.
_____
_____
Who owns the intellectual property rights in synthetic biology?
Some commentators continue to argue that synthetic biology, like other developments such as the sequencing of genes, should not be patentable. The knowledge, they insist, should be freely available to all. However, the patentability of biotechnology inventions in general is now well established. That said, patenting issues in this field continue to be debated. Two problems in particular have emerged: the creation of overly broad patents that may foster monopolies, hamper collaboration, and stifle innovation by other researchers; and, conversely, the creation of unduly narrow patents that can impede subsequent applications because of the complexity of licensing arrangements required to deal with multiple holders. The multidisciplinary nature of synthetic biology, which requires that patent expertise be drawn from several different fields, may serve to exacerbate these problems. Synthetic biology may pose special problems for those seeking ownership of, or access to, what might become vast arrays of new technologies. Both patent thickets (the need to receive licenses from multiple patent-holders) and the “anticommons” (many patent owners blocking each other) are potential roadblocks to the use and distribution of these technologies. This is an area that will need significant attention as the field develops.
_______
_______
Synthetic biology, a profound challenge for Governance:
Synthetic biology poses what may be the most profound challenge to government oversight of technology in human history, carrying with it significant economic, legal, security and ethical implications that extend far beyond the safety and capabilities of the technologies themselves. Yet by dint of economic imperative, as well as the sheer volume of scientific and commercial activity underway around the world, it is already functionally unstoppable. With hundreds of millions of dollars worldwide already spent or committed to synthetic biology R&D across several sectors, and what is almost certainly millions more in undisclosed venture financing and corporate partnerships, companies are driving hard to deliver products for commercial release. This drive to market, coupled with no substantive expert, stakeholder or public policy discussion regarding the balance of risk and benefit for its products, has led many observers to declare that synthetic biology is a juggernaut already beyond the reach of governance.
_
Proponents are quick to point out that synthetic biology research and its products are not entirely unregulated. In the United States, the NIH still requires laboratories receiving NIH funds to comply with laboratory procedures as outlined in their Recombinant DNA Guidelines. A drug produced by a synthetic organism would be evaluated like any other by the Food and Drug Administration. Also, depending on the application, the Environmental Protection Agency or the U.S. Department of Agriculture would oversee the potential release of synthetic organisms into the environment. This argument, however, presumes that present regulations are appropriate for evaluating the products of synthetic biology. The critical question that has not been explored is whether synthetic biology poses unique risks that are unconsidered by present health and safety regulations (and regulatory approaches), as well as by financial regulations that govern intellectual property rights and trade.
_
Some of synthetic biology’s researchers, investors and funders acknowledge the possibility of unintended consequences, but for the most part they minimize the risk, openly acknowledging that they want to avoid synthetic biology becoming the new target for the negative perceptions that many people around the world continue to hold for biotech crops and other biotech products. As a group, they overwhelmingly insist that if synthetic biology is to fulfil its promise, scientists must be trusted to do the right thing, and that existing regulations are sufficient to shield the public from any hazards that might result from the products of synthetic biology. This perspective is best expressed by a recent statement made by Victor de Lorenzo, vice director of the National Centre of Biotechnology in Madrid, Spain. In a 2006 article in the journal of the European Molecular Biology Organization, he said, “I think the question of regulation should not be the first question. … Let’s first see what [the technology] is good for. If you first ask the question about risk, then you kill the whole field.” The main argument used in favor of self-regulation of synthetic biology’s processes is that they are simply the result of a more sophisticated application of the aforementioned laboratory techniques developed for working with recombinant DNA. As for the products of synthetic biology, practitioners argue that they already fall within the purview of existing regulations that govern genetically engineered organisms and the substances that these organisms may produce. But these characterizations sell short several fundamental, related differences between the two practices, and ignore the history of how genetically engineered organisms came to be as lightly regulated as they are today.
_
In the US, synbio falls under the mantle of the National Institutes for Health Guidelines for Research involving Recombinant DNA Molecules. Regulators feel these guidelines can manage risks that might arise in the research stage of synbio, but more information will be needed to assess the risks inherent in containing completely synthetic organisms. Since synbio research is largely proprietary, there is concern that information related to risks might be withheld by companies claiming intellectual property rights. In 2010, the Department of Health and Human Services created guidelines to screen synthetic DNA sequences for any attempts to create dangerous toxins or biological weapons, but compliance by DNA synthesizing companies is voluntary. For planned releases, synbio organisms are subject to the same rules and regulations as genetically modified organisms, which are overseen by the Environmental Protection Agency, the Food and Drug Administration, and the Department of Agriculture.
_
Should synbio organisms be subject to additional inspection because they use synthetic DNA?
After Venter’s announcement in 2010, President Obama charged a commission to examine the implications of synthetic biology. The commission’s report, issued in December 2010, analyzed the risks and benefits of synbio, and determined that new regulations were not needed. It recommended that synbio scientists regulate themselves, that the President’s office coordinate oversight by the relevant agencies, and that the agencies coordinate synbio risk assessment, allowing synthetic organisms to be released into the field only after a reasonable review. 58 environmental, public interest and religious groups from 22 countries denounced the commission’s recommendations because they “1) ignore the precautionary principle, 2) lack adequate concern for the environmental risks of synthetic biology, 3) rely on the use of ‘suicide genes’ and other technologies that provide no guarantee of environmental safety, and 4) rely on ‘self-regulation,’ which means no real regulation or oversight of synthetic biology.” The groups called for a moratorium on the release and commercial use of synthetic organisms until a serious study of the potential environmental, health and socio-economic impacts has been conducted.
_
Meanwhile millions of dollars are being invested in synbio by corporations such as BASF, DuPont, Cargill, Weyerhaeuser, and Syngenta, and the oil companies BP, Shell, and ExxonMobil that are positioning themselves to control the future of fuel. The Gates Foundation invested $42.6 million into Amyris for research on artemisinin. Money is also pouring into synbio from the U.S. Department of Energy and the U.S. military, which invested $6 million in research on synthetic organisms that can live forever or be controlled with a kill switch. Just recently, the Defense Advanced Research Projects Agency (DARPA) committed $30 million to speed up the development of synbio by lowering costs and shortening the timelines of product development. Outside the U.S., synbio research is ongoing in Europe, Israel, Japan, India and China; and synbio technology will soon be tested in countries like Brazil, Mexico, South Africa and Malaysia.
_
A poll of 1,000 Americans taken in September 2010 revealed that people are almost evenly split between those who believe the benefits of synbio will outweigh the risks and those who don’t; 32% are not sure. It appears that people are taking a wait-and-see attitude towards synbio, which is probably a good thing for now. But every day DNA sequencing and DNA synthesizing get cheaper and quicker— it’s crucial that we, the public, become properly informed about synthetic biology because it has the potential to radically alter our lives and our planet.
_
Opposition to synthetic biology:
On March 13, 2012, over 100 environmental and civil society groups, including Friends of the Earth, the International Center for Technology Assessment and the ETC Group issued the manifesto The Principles for the Oversight of Synthetic Biology. This manifesto calls for a worldwide moratorium on the release and commercial use of synthetic organisms until more robust regulations and rigorous biosafety measures are established. The groups specifically call for an outright ban on the use of synthetic biology on the human genome or human microbiome. Although some of the safety tenets for oversight discussed in The Principles for the Oversight of Synthetic Biology are reasonable, the main problem with the recommendations in the manifesto is that the public at large lacks the ability to enforce any meaningful realization of those recommendations.
_____
_____
Synthetic biology R & D, market and companies:
Synthetic biology represents an amalgam of scientific disciplines and sub-disciplines, public and private funding, public and private institutions, complex cross-sector collaborations and, in some cases, new approaches to intellectual property protection. The iGEM competition is only one example of the investment money and taxpayer-funded research dollars that are flooding the nascent field of synthetic biology. The potential payoff for the ability to build and sell novel living organisms is considered to be so great that venture capitalists, government agencies and multinational corporations, including BP (formerly British Petroleum), Shell, Cargill, and Dupont, are already investing in research and partnerships with startup companies to drive synthetic biology products to market as quickly as possible. Not surprisingly, most of the significant synthetic biology research and development is taking place in the United States, where most of the world’s biotechnology R&D activities are also centered. But other countries, most notably those in Europe, are also investing heavily in synthetic biology development. Although synthetic biology is becoming a global research enterprise, the U.S. is the leading nation in the world. In 2000, two U.S. research groups reported the creation of genetic oscillators and toggle switches that function in an analogous manner to electrical circuits, which marks the birth of the synthetic biology field. Since then, the U.S. government has been the biggest investor in this emerging discipline, providing approximately $500 million to $1 billion research funding since 2005, with a yearly spending estimated at $140 million. Many U.S. research centers focusing on synthetic biology have been established, including but not limited to Synthetic Biology Engineering Research Center (Synberc), the Centers for Synthetic Biology at MIT and University of California at San Francisco (UCSF), and the J. Craig Venter Institute. Moreover, U.S. industry has also been investing heavily in the medical and biotechnological applications of synthetic biology with an expected market value of $10.8 billion by 2016. Exemplary companies are from multinationals such as DuPont, BP, ExxonMobil, to start-ups such as Synthetic Genomics, Amyris, Intrexon, Ginkgo Bioworks, and Zymergen. Globally Synthetic Biology has advanced rapidly in the last decade. According to Synthetic Biology Project at the Wilson Center (USA), the United States has invested approximately $820 million in Synthetic Biology research between 2008 and 2014. The UK has funded nearly $165 million in Synthetic Biology research since 2010. The International Genetically Engineered Machines Competition (iGEM) has grown from five US teams in 2004 to 280 teams from six continents in 2015. As per Synthetic Biology Products and Applications Inventory hosted by The Synthetic Biology Project, there are more than 100 products/applications that are close to market entry or on the market. In addition, several U.S. government agencies, including the Departments of Defense and Energy, the National Institutes of Health, and the National Science Foundation, have already made investments of millions of dollars in synthetic biology centers and projects, and published NSF research priorities for the 2009 fiscal year indicate synthetic biology funding may increase. A handful of science-minded foundations, most notably the Bill and Melinda Gates Foundation, are investing in synthetic biology projects. Not wanting to be left behind, the European Union is funding the development of a European strategy for synthetic biology, including “stimulation activities” for the mobilization of public and private resources to fuel the nascent industry. Researchers in Africa, Canada, India, Israel, Japan, Korea, Latin America, Slovenia, Turkey, and many other countries are said to be actively pursuing synthetic biology projects as well.
_
Synthetic Biology Markets:
One study reported that synthetic biology market reached nearly $3.9 Billion in 2016 and should reach $11.4 Billion by 2021. Another study forecasts the $3 billion global market of 2013 to grow to $38.7 billion by 2020. Agriculture, biofuels, pharmaceuticals and chemicals are the chief product categories enabled by synbio processes. 2016 was a big year for the synthetic biology industry with over $900 million raised from either venture capital or the public markets. This is an incredible number considering that the whole industry raised $800 million in the whole of 2015.
_
Synthetic Biology Companies:
The advancement of the field in the past decade has been phenomenal. Suffice it to look at how many synbio start-up companies have been created and now thrive, almost ready to commercialize their products. Their main goal is to produce sustainable goods useful to solve modern society problems. Leading the pack was the initial public offering by Intellia Therapeutics, which is a gene editing company and spun out of UCSF, which raised $108 million when it IPO’d. Ginkgo Bioworks raised an astonishing $100 million to fund their expansion and building of their Bioworks 2 foundry in Boston. Editas Medicine, another gene editing company that spun out of MIT, also IPO’d raising $94.4 million. Modern Meadow is trying to create animal food and sustainable animal materials without the need of animal slaughter and much lower use of land, water, energy and chemicals. Glowing plants is doing exactly what their name suggests: producing plants able to glow in the dark and that could one day substitute electric lighting. Synthetic DNA company, Twist Bioscience, continues its dramatic rise with raising $61 million for the scale-up and commercial operation of its silicon chip-based high throughput low-cost gene synthesis platform. The consumer sector is well-represented by successive funding rounds from Bolt Threads which raised $50 million for engineered silk fabrics and Modern Meadow which raised $40 million for its leather replacement product. Engineered cell therapies are a hot new area with Wendell Lim’s Cell Design Labs raising $34.4 million, a spin-out from UCSF; and Synlogic, a spin-out from Jim Collins and Tim Lu’s lab at MIT that is engineering E. coli for drug delivery into the gut. Caribou Biosciences, a third gene-editing company, raised $30 million in a Series B funding, and Calysta announced their $30 million round for Series C funding to advance its gas fermentation platform. Amyris, which has continued to show increase in revenue this year, closed a $20 million. Pivot Bio, a seed-coating company, which has been in stealth mode for a number of years came on to the scene with its $16 million Series A. Synthetic biology products may eventually comprise a significant portion of what analysts at Morgan Stanley estimate will be a trillion-dollar market for alternative fuels by 2030. Several companies, including Dupont, already produce commercial “bioplastics” that are manufactured by semi-synthetic bacteria. The synthetic biology company Solazyme recently announced that it would partner with Chevron, the world’s seventh-largest corporation, to develop biodiesel from synthetically redesigned algae. BP is an equity investor in Craig Venter’s company, Synthetic Genomics, Inc.
_______
_______
Applications of synthetic biology:
Synthetic Biology has the potential to make the process of development of an organism comprehensible to us as well as unlock many of the mysteries of biology with possible applications in medicine and energy production. It is believed that Synthetic Biology shares the potential, together with Nanotechnology and Artificial Intelligence to generate new entities, which can reproduce and evolve at will. These entities can then be used to solve problems not possible by a human mind.
_
Proponents of this new engineering discipline claim that the ability to create, manipulate and cheaply manufacture customized or unique life forms will produce many benefits across a wide range of applications, from medicine to energy generation and environmental remediation. In the near term, their vision of the future includes designer microorganisms and other engineered life forms that can be deployed as “devices” to stimulate tissue repair and cell regeneration and sense changes in body chemistry that might be precursors to disease. They also say synthetic organisms will be able to produce new kinds of pharmaceutical compounds and plastics, as well as detect toxins, break down air and water pollutants, destroy cancer cells, and generate hydrogen and other substances for new energy technologies. Synthetic biology can be regarded as a platform technology that cuts across several key market sectors, such as energy, chemicals, medicine, environment and agriculture. Its formative years have been spent in developing the basic tools for applications in biofuels and other bio-based products, where the earliest products have been seen. It holds out very high expectations and potential for applications to human and animal health, with the potential for greatest benefits in the developing and poor nations. With a growing global population and threats to water and soil quality, agricultural applications are envisaged that could have far-reaching consequences for productivity and efficiency, but in many parts of the world such agricultural applications are controversial.
_
In fact, the technologies and products for creating synthetic components are already affordable and widely available to virtually anyone with access to the Internet, a credit card and a shipping address—or to any clever biology student, for that matter. When Eckard Wimmer, professor at the State University of New York, Stony Brook, who first synthesized the poliovirus from single nucleotides, was interviewed for a 2006 journal article on synthetic biology, he said, “With this technology you can make poliovirus for 50 cents. In five years you [could] have this synthesis facility in every university lab. … You cannot stop this technology because there is a great hunger for it from many biologists.” The more cheaply you can “print” DNA, the better it’s going to be. Sequencing has become really cheap. The synthesis is the part that’s still fairly expensive, but there are companies that are trying to break barriers. We’re also going to get better-automated work flows—by using low-cost lab robots, for example. It is already common practice for people to decide the piece of DNA code they need, type it into a computer, and have somebody else do all the building work in the laboratory.
_
Synthetic biology applications:
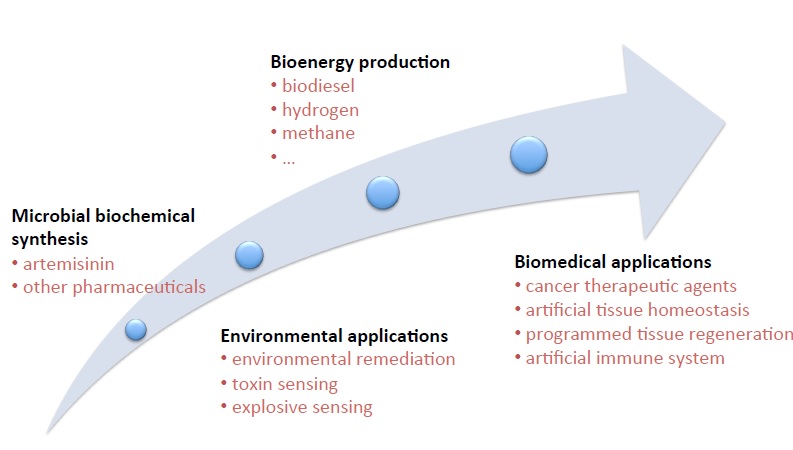
Synthetic biology has a vast range of potential practical applications (Porcar and Pereto 2012). It is perceived as a way to tackle problems, among others, in cell and tissue engineering, gene therapy, biologically derived materials, biocatalysis and natural product synthesis (Arkin and Fletcher 2006). In addition, it is believed to facilitate mass production of useful compounds and a variety of chemicals (drugs, biofuels, etc.), to be key in the development of bioremediation, to increase crop yield, lead to the production of novel food ingredients, and improve human health (Porcar and Pereto 2012). Upon careful design, it offers the possibility to minimise unwanted (side) effects (like production of any undesirable substances that might reduce yield or inhibit metabolic pathways), to reduce energy costs to the cells, and to establish good conversion from substrate(s) to desired product (Ellis and Goodacre 2012). Major efforts toward potential application of synthetic biology include the production of biofuels like ethanol, algae-based fuels, bio-hydrogen and microbial fuel cells; bioremediation like wastewater treatment, water desalination, solid waste decomposition and CO2 recapturing; the production of biomaterials like bioplastics, bulk chemicals, pharmaceuticals, flavourings, fragrances, and compounds for cosmetics; and finally the production of novel cells and organisms, which includes the generation of protocells and xenobiology.
_______
The factsheet on synthetic biology [NEST, 2006], produced by an expert working group, outlines a number of the potential applications that are promised by the new methodology under the heading, ‘The Vision of Synthetic Biology’. These are listed under the following headings:
- Biomedicine
-Complex molecular devices for tissue repair/regeneration
-Smart drugs
-Biological delivery systems
-Vectors for therapy
-Personalised medicine
-Cells with new properties that improve human health
- Synthesis of biopharmaceuticals
-Complex natural products
- Sustainable chemical industry
-Environmentally friendly production of chemicals
- Environment and energy
-Bioremediation
-Production of energy
-GMO safety
- Production of smart materials and biomaterials
- Security/counter-terrorism.
___

____
Synthetic biology may offer the potential for economic growth through trans-sectoral impacts, in areas such as energy, health, and the environment. Developments currently envisaged include:
- environmental applications, such as detecting environmental contaminants using biosensors and removing such contaminants using specifically tailored plants or microorganisms;
- health-related applications, such as diagnosing, monitoring, and responding to disease conditions in humans and animals and developing and manufacturing new drugs and vaccines;
- industrial applications, such as employing plants, microorganisms, and specifically tailored enzymes for developing biofuels, as well as devising more efficient biomanufacturing and synthesis processes using chemical technology.
___
Solving hunger:
Synthetic biology may help farmers feed more people. For millennia, crops have been bred with an eye toward improved harvests. Later, genetic manipulations upped plant yields and made crops more resilient against drought and other hazards. Now, scientists are looking at tweaking photosynthesis. “You don’t need to increase the biomass of plants by that much to solve the food problems across the world,” says Harvard’s Pamela Silver. One idea is that new enzymes could boost the amount of energy that plants can extract from the sun. Another suggests there might be a totally different way to pull usable carbon from the atmosphere. In the April 2012 Applied and Environmental Microbiology, Silver and colleagues reported engineering a bacterium to churn out up to 200 percent of its initial cellular mass as sugar. The work could be used to develop plants that produce more food per harvest.
__
Synthetic biology in microorganisms:
Microbes, in particular Escherichia coli or yeast, may also be used as experimentally convenient heterologous hosts to reconstitute biosynthesis (Li and Pfeifer 2014). Such an approach offers considerable advantages as compared to production in, e.g., the native plant host or chemical synthesis strategies, which may be hampered by slow growth kinetics and low native titres. Companies design strains (e.g. Escherichia coli Clean Genome®, Scarab Genomics) with “enhanced genetic stability, improved metabolic efficiency and improved production yields” with the aim of creating efficient production platforms. The desired properties are achieved by deleting nonessential gene, insertion sequence (IS) elements, recombinogenic/mobile DNA, cryptic viruses and virulence genes, and the strains are being offered as a platform to optimise processes for the production of, e.g., therapeutic proteins, plasmid DNA and vaccines. Also Saccharomyces cerevisiae is already well adapted to industrial conditions and thus its use for industrial production is easy and straight-forward (“plug-and-play solution”) (Nielsen and Keasling 2011). Remarkably both Escherichia coli and Saccharomyces cerevisiae are in addition important model organisms, ensuring the availability of an impressing amount of data originating from basic research. Another important species that may serve as platform cell factory is Corynebacterium glutamicum (Becker et al. 2013). It has been suggested as a model organism for synthetic biology as it is capable of producing a variety of valuable chemicals and materials, and is already applied in the industrial production of amino acids (Woo and Park 2014). A number of approaches to optimise Corynebacterium glutamicum, including the development of standard DNA parts, DNA/RNA parts, and devices (e.g. to sense metabolites) are discussed by Woo and Park (2014). In general, strain development is an important application for synthetic biology in microbes (as for example the generation of optimised Corynebacterium glutamicum strains for the production of amino acids or even the establishment of multi-use platform strains) (Wendisch 2014).
_
Algae for the production of desired compounds:
As molecular genetic manipulation of eukaryotic algae and/or prokaryotic blue-green algae (cyanobacteria) is easier than that of higher plants this field is emerging much faster than the latter (Lee 2013). Potential applications include biofuel-production, ultimately by direct conversion of sunlight to fuel. It may also be used to replace biomass production on arable land and the use of freshwater by employing other sources like sea-, ground- or even waste water. Biofuels and byproducts can be synthesised from a large variety of algae (Menetrez 2012). Using algae and microalgae for the production of biofuels is an attractive application due to their potential to accumulate high amounts of lipids and due to high starch content providing a good source for bioethanol production (Safi et al. 2014). In addition, they can be cultured with an inexpensive nutrient regime, have faster growth rate compared to terrestrial plants and high biomass production. As they provide an alternative to current biofuel crops (e.g. soybean, corn, rapeseed and lignocellulosic feedstock) also less favoured environments (land that is unsuitable for agriculture, brackish coastal water and seawater) may be used, adding to the potential to provide remediation for waste (Safi et al. 2014; Menetrez 2012).
_
Synthetic biology in other species:
There are also attempts to use hosts beyond bacteria and yeast, e.g. to produce spider silk (dragline silk protein) in the milk of transgenic mice (Xu et al. 2007). The animal host was more efficient as compared to microbial ones in expression and homogeneity. Recently, synthetic biology has also been suggested as providing new strategies for therapeutic applications (Ye and Fussenegger 2014). For this, for example gene circuits are assembled into biosensing devices. The designed circuits monitor, quantify, and treat diseases by sensing disease signals, and producing and releasing tailor-made therapeutic molecules. Another recent development aims at regulating gene drives that influence reproductive capacity (Oye et al. 2014). Potential applications are the elimination of mosquito-borne diseases like malaria and dengue, reversing the development of pesticide and herbicide resistance, and the local eradication of invasive species. However, it has been acknowledged that this development has substantial implications concerning environmental and security aspects, and risk management (Oye et al. 2014).
_
Synthetic biology in plants:
Concomitant with recent advances in plant biotechnology, the field benefits from methods for synthetic biology that have already been successfully applied by the microbial biotechnology community. In particular DNA assembly techniques are also adopted by plant biologists (Patron 2014). However, the progress in synthetic biology in plants is slower compared to that in microbial systems (O’Connor and Brutnell 2014). In the plant field, Arabidopsis thaliana is the model organism, and a plethora of information on gene function or metabolic and regulatory pathways has been created by basic research (Kliebenstein 2014). Thus, it may be seen as the plant equivalent to Escherichia coli or yeast, offering the possibility to use it as a platform organism (Nielsen and Keasling 2011). Besides Saccharomyces cerevisiae and Escherichia coli, Candida utilis, Streptomyces avermitilis, and Bacillus subtilis have been used as heterologous hosts for the production of plant-derived isoprenoid products, like lycopene from tomato, artemisin against malaria from Artemisia annua, and paclitaxel (taxadiene) with anti-cancer properties from Taxus brevifolia (reviewed in Li and Pfeifer (2014)). Another example is the production of isoprenoids in Escherichia coli (Ajikumar et al. 2010).
_
“Glowing plants”:
A further research for using synthetic biology techniques is demonstrated in the design/ the creation of glowing plant. In the so called “Glowing Plant project”, synthetic biology techniques and software from Genome Compiler, for the design and print DNA, are used for transformation processes of Arabidopsis thaliana. These processes will lead to the production of luciferase and luciferin, which appears in an emission of weak, green-blue light by endowing it with genetic circuitry from fireflies. Finally the creation of a so called “Glowing Plant” is completed/finished (Callaway 2013). Pollack (2013) tinkers with this idea one stage further for the development of glowing trees that can replace electric streetlamps and potted flowers luminous enough to read by.
______
______
Medical Synthetic Biology:
- Re-programming stem cells
- Regenerative medicine
- Alternative processes of drug production
- New therapeutic methods (including de novo designed vaccines)
- Non-invasive diagnostics
- Engineering human immune cell responses (which provide defences against cancer, inflammation, autoimmune diseases…)
____
The Clinical Potential of Synthetic Biology:
One way to look at medicine is that it attempts to repair malfunctions of the human body, be they internal errors such as genetic diseases or invasions of parasites and pathogens. Synthetic biology aims to re-engineer biological processes, and to do so in such a way as to produce specific, targeted outcomes. It’s no accident, then, that a great deal of hope and effort is being invested in developing synthetic biology for many difficult to treat diseases such as cancers, antibiotic resistant infections or genetic disorders. Even though the discipline is in its infancy, there are already some promising approaches emerging from labs around the world. There are number of ways in which synthetic biology may help human health. These approaches are universally elegant and demonstrate an impressive diversity of ideas.
______
- Fighting Infection:
The discovery and development of antibiotics has had a profound effect on human health. Many previously deadly diseases are now easily cured. But, inevitably, their impact is starting to wane as bacteria fight back and acquire resistance. Drug development has slowed and new approaches to treating antibiotic resistant infections are needed.
_
Drug production:
It has been estimated that for every successful drug compound, 5,000 to 10,000 compounds must be introduced into the drug-discovery pipeline. On average, it takes $802 million and 10 to 15 years to develop a successful drug. Given this very low success rate and the incredibly high costs, drug companies must introduce as many drug candidates into their pipelines as possible. Natural products have been important sources of drug leads; as much as 60 percent of successful drugs are of natural origin (Cragg et al., 1997), and some of the most potent natural products have been used as anticancer, antibacterial, and antifungal drugs. However, most natural products have evolved for purposes other than the treatment of human disease. Thus, even though they can sometimes function as human therapeutics, their pharmacological properties may not be optimal. Furthermore, many are produced in miniscule amounts in their native hosts, thus making them expensive to harvest.
_
_
Synthetic Biology provides New Approach to Antibiotic Production: 2017 study:
Researchers from Imperial College London report that they have re-engineered baker’s yeast (Saccharomyces cerevisiae) to manufacture penicillin, which, in lab experiments, had antibacterial properties against Streptococcus bacteria. The authors of the study (“Biosynthesis of the Antibiotic Nonribosomal Peptide Penicillin in Baker’s Yeast”), which is published in Nature Communications, say their new method demonstrates the effectiveness of using this kind of synthetic biology as a route for discovering new antibiotics. This could open up possibilities for using re-engineered yeast cells to develop new forms of antibiotics and anti-inflammatory drugs from nonribosomal peptides such as penicillin, they add. Nonribosomal peptides are normally produced by bacteria and fungi, forming the basis of most antibiotics today. In their experiments, the team used genes from the filamentous fungus (Penicillium chrysogenum) from which penicillin is naturally derived. These genes caused the yeast cells to produce penicillin via a two-step biochemical reaction process. First the cells made the backbone molecule by a complex reaction, and then this was modified by a set of further fungal enzymes that turn it into the active antibiotic. During the experimentation process, the team discovered that they didn’t need to extract the penicillin molecules from inside the yeast cell. Instead, the cell was expelling the molecules directly into the solution it was in. This meant that the team simply had to add the solution to a petri dish containing Streptococcus bacteria to observe its effectiveness. In the future, this approach could greatly simplify the molecule testing and manufacturing process, noted Ali Awan, Ph.D., co-author from the department of bioengineering at Imperial College London. Researchers believe yeast could be the new mini-factories of the future, helping them to experiment with new compounds in the nonribosomal peptide family to develop drugs that counter antimicrobial resistance.
_
With the rise of multiresistant pathogens, novel antimicrobial compounds are increasingly needed. Since the discovery line of novel drugs has diminished in the recent years, novel approaches, such as those proposed by synthetic biology, are in demand. For example, a synthetic mammalian gene circuit was utilized for the discovery of novel antituberculosis compounds. Ethionamide is an antibiotic often used for treatment of tuberculosis; however, ethionamide-based therapies are sometimes unsuccessful due to the development of resistance by Mycobacterium tuberculosis. The resistance develops when M. tuberculosis protein EthR represses the transcription of EthA, which converts ethionamide into a toxic metabolite. A rationally designed chemical library was screened for a compound that would inhibit EthR binding to EthA promoter. The interaction between the latter was assayed in human cells through a reporter gene expression. The screening revealed 2-phenylethyl-butyrate as a potent inhibitor of EthR, which dramatically increased the sensitivity of M. tuberculosis to ethionamide. This work was a demonstration of a generic screening platform for the discovery of novel antituberculosis drugs.
_
Sitagliptin, Merck’s first-in-class dipeptidyl peptidase-4 inhibitor, is marketed under the trade name Januvia® as a treatment for type II diabetes. The chemical manufacturing route to Sitagliptin developed by Merck won a Presidential Green Chemistry Challenge Award in 2006, but there were still several opportunities for improvement. Codexis and Merck collaborated to develop a novel, environmentally benign alternative manufacturing route. Using synthetic biology and its directed evolution technologies, Codexis discovered and developed a transaminase capable of enabling the new biocatalytic route, which is currently in scale-up towards commercial manufacture.
_
Synthetic biology also paved a new road for discovering novel anticancer agents. Cytotoxic anticancer drugs are believed to discriminate between cancerous and normal tissues by preferentially killing actively dividing cells through targeting DNA replication, which makes cytotoxic drugs more generic compared to “targeted” anticancer drugs. For the discovery of novel cytotoxic drugs, a high throughput-compatible mammalian cell based assay was devised. CHO-K1 cell line was engineered for tetracycline-responsive overexpression of human cyclin-dependent kinase inhibitor p27Kip1, which is a negative regulator of G1-S transition. The engineered cells proliferate normally in the presence of tetracycline. However, upon withdrawal from the antibiotic, they diverge into a heterogeneous population of growth-arrested and proliferation-competent cells due to a spontaneous loss of p27Kip1 in roughly half of the cells. These proliferating cells were assumed to imitate the neoplastic cell characteristics. The assay was validated by scoring the viability of arrested and proliferating cells upon exposure to clinically licensed cytotoxic drugs. It is expected that the assay will be useful for high throughput screening of novel anticancer drugs.
_
Natural products have been valuable in therapeutic areas such as infectious diseases and oncology. These drugs, however, are produced in small amounts in native hosts, and therefore, extraction of these drugs from native hosts is usually uneconomical or can have a negative impact on the environment. A powerful solution is drug production in metabolically engineered microorganisms or plant cells, which can be made capable of large-scale production. A prominent recent example is pathway optimization for overproduction of taxadiene, a precursor to an anticancer drug taxol. In this study, Escherichia coli was used as an expression host, where the overall pathway was partitioned into two modules. Unlike in previous studies, where these two modules were engineered separately, here, the modules’ expression was varied simultaneously by using various promoters and gene copy numbers. This approach allowed identification of an optimally balanced pathway using a small combinatorial space. The titer of taxadiene was improved 15,000-fold, yielding approximately 1 g/L of taxadiene in fed-batch bioreactor fermentations.
_
The discovery of drugs does not always translate to the people who need them the most because drug production processes can be difficult and costly. Antibiotics are industrially produced from microbes and fungi, and are therefore widespread and cheap. Conversely, many other drugs are isolated from hosts that are not as amenable to large-scale production and are therefore costly and in short supply. Such drugs include the antimalaria drug artemisinin and the anticancer drug taxol. Fortunately, global access to drugs is being enabled by hybrid synthetic biology and metabolic engineering strategies for the microbial production of rare natural products. In the case of artemisinin, there exist two biosynthetic pathways for the synthesis of the universal precursors to all isoprenoids, the large and diverse family of natural products of which artemisinin is a member. The native isoprenoid pathway found in Escherichia coli (the deoxyxylulose 5-phosphate (DXP) pathway) has been difficult to optimize, so instead researchers have synthetically constructed and tested the entire Saccharomyces cerevisiae mevalonate-dependent (MEV) pathway in E. coli in a piece-wise fashion (for example, by separating the ‘top’ and ‘bottom’ operons). The researchers initially used E. coli as a simple, orthogonal host platform to construct, debug and optimize the large metabolic pathway. They then linked the optimized heterologous pathway to a codon-optimized form of the plant terpene synthase ADS to funnel metabolic production to the specific terpene precursor to artemisinin. This work allowed them to build a full, optimized solution that could be ultimately and seamlessly deployed back into S. cerevisiae for cost-effective synthesis and purification of industrial quantities of the immediate drug precursor of artemisinin.
_
Newer antibiotics:
Researchers provided examples where synthetic biology can be used to construct new antimicrobial agents by building upon natural systems. By swapping biological assembly modules in secondary metabolic pathways, they can create entirely new chimeric chemical entities. Alternatively, they can use computational approaches to create small focused `smart’ libraries of antimicrobial peptides and significantly reduce the costs associated with drug discovery. They can re-engineer phage therapeutics and leverage phage-derived products to create programmable therapeutics that extend our notions of traditional antibiotics. Antibiotic discovery has been defined by periods of great ingenuity that have culminated in the golden era of antibiotic discovery and medicinal chemistry, where most of our current arsenal of antimicrobials originated. A new interdisciplinary approach is required to tackle the challenges that we face today in regards to antimicrobial discovery. By exploiting enhanced ability to program biology and remodel natural systems, researchers are poised to potentially usher in a new era of antimicrobial discovery in the early 21st century. Antibiotics, and many related bioactive secondary metabolites can be synthesized by highly modular molecular machines, encoded by large multigene clusters in microbial genomes. Their natural modularity makes these biosynthetic machines attractive targets for an engineering-inspired synthetic biology approach. Synthetic biology can be used to rapidly identify novel antibiotics by a systematic awakening of silent gene clusters detected by comprehensive genome mining. It can also complement the established strategies of combinatorial biosynthesis and mutasynthesis, to enable the rapid generation of new chemical diversity. Finally, synthetic biology can expand the toolbox of metabolic engineering to construct powerful host strains (chassis) for the industrial production of bioactive metabolites.
_
Another very different approach to infectious disease is seen in a synthetic biology approach that could be used to tackle malaria. The parasite that causes this disease has to spend part of its life cycle inside a mosquito. Genetically modified mosquitoes can be engineered to block this stage, but that will only work if the genetic alterations are spread quickly to the whole mosquito population. A piece of synthetic DNA has been constructed that should, in principle, encourage another set of genes to spread rapidly throughout a breeding population, almost like an infectious genetic disease. And in laboratory tests it did indeed spread throughout a caged population very quickly. This was a proof of principle, and did not carry any anti-malaria payload, so to speak. The next step would be to add an anti-malaria genetic modification to this system, producing, in theory, a genetic construct that would reduce or even eradicate malaria transmission.
______
- Cancer:
One of the greatest challenges for cancer treatments is to eliminate cancerous cells in the human body without damaging associated tissue. There are two synthetic biology approaches which have produced promising results in the lab. The first involved engineering bacteria to produce a protein that makes them stick to human cells, but to produce that protein only in the absence of oxygen. Tumours often grow in low levels of oxygen as their blood supply is poor. The hope is that when the bacteria encounter a low oxygen tumour, they will stick to and invade the cancerous cells. The engineered bacteria were shown to invade human cells in the test tube only when oxygen levels were low. A potential problem with this approach, though, is that it would rely on the blood supply to deliver the bacteria to the cancer. However, tumours often have poor blood supply, making them low in oxygen, which is why this approach works in the first place. A lack of blood makes them susceptible, but also makes delivering the treatment a challenge. This obstacle has been circumvented in a different approach that tackles one of the genes involved in turning cells cancerous in the first place. The CTNNB1 gene is involved in many colon cancers when it behaves in an abnormal fashion. Reducing the output of this gene when this occurs could potentially stop colon tumours from growing and spreading. The researchers engineered a bacterium that could penetrate colon cancer cells and interfere with the workings of the CTNNB1 gene and demonstrated that it could indeed target colon cancer cells growing in laboratory mice [vide supra].
__
Oncolytic Virotherapy:
Chemotherapy and radiotherapy are used extensively in the clinic but often target noncancerous tissues and have limited toxicity to cancer cells. More sophisticated technologies capable of discriminating between cancerous and healthy tissues are therefore needed. One of the developing fields that can potentially provide a solution is oncolytic virotherapy, which focuses on engineering viruses capable of infecting and killing cancers. Some viruses are naturally oncotropic, and many also have tissue tropism, which has been a starting point for engineering tumor-specific oncolytic viruses. A combination of classical genetic engineering (through modification or transfer of one or two natural genes) and the synthetic biology concept of rationally designing functions not present in nature has been employed to reengineer viruses that specifically kill cancer cells. Thus, an adenovirus was constructed in which viral genes needed for its replication (E1A and E4) were brought under the control of the gene regulatory region of the human E2F1 gene that in normal cells is repressed by the RB tumor suppressor gene product. Since many tumor cells lost this suppressor, selective viral gene expression, replication, and progeny production/cell lysis can occur in a variety of tumor cells, but not normal cells. Similarly, a pox virus that shows tumor-specific replication (in clinical trials) based on targeting multiple mechanisms was rationally constructed by simple genetic engineering, involving viral thymidine kinase gene inactivation and expression of a human transgene for granulocyte-macrophage colony stimulating factor (GM-CSF).
_
Designer Anticancer Bacteria:
Engineering bacteria to invade and kill cancer cells is another promising strategy for cancer treatment. Salmonella, Clostridium, and other genera have been shown to have tumor-tropism and the ability to kill cancer cells, which was exploited for engineering of even more potent anticancer bacterial strains. In a recent study, tumor specificity, which is an important attribute of anticancer bacterial therapy, was addressed. To inhibit nonspecific invasiveness of Salmonella, single-domain antibody against human tumor-associated antigen CD20 was expressed on the bacterial cell surface. The engineered Salmonella was found to preferentially invade and destroy CD20+ lymphoma xenografts in mice while significantly minimizing nonspecific cell invasion.
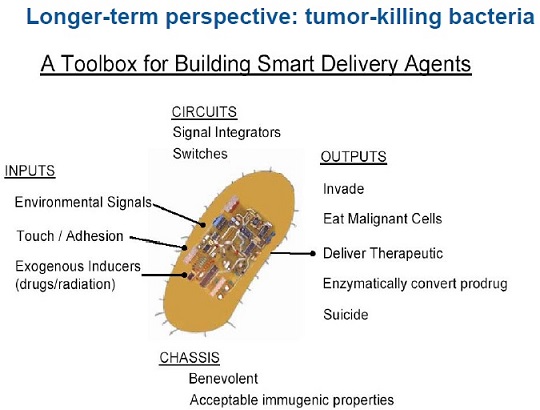
_
Chimeric Antigen Receptors (CAR) Engineered T cells therapy:
Adoptive T cell therapy has been shown to be effective in initiating lasting antitumor responses. In some cases, though, the effectiveness of the technique is limited since the function of redirected T cells relies on the presentation of tumor antigens by the major histocompatibility complexes (MHC), which are often inhibited in cancerous cells. Engineering of T cells to express chimeric antigen receptors (CARs) allows MHC-independent T cell activation and proliferation. CARs are modular fusion proteins consisting of an extracellular antigen recognition element, usually single chain variable fragment (scFv) antibody, a transmembrane domain, and an intracellular signalling domain, usually from T cell coreceptor CD3ζ or Fc receptor γ. To date, the most encouraging clinical observations were achieved with CARs specific for CD19 antigen, which is expressed in B cell malignancies such as B cell leukemia/lymphoma, but not by normal essential tissues.
_
Biologists aim for better cancer-fighting cells by creating new Notch molecules: a 2016 study:
In two studies published in Cell, scientists synthesized new forms of a molecule that stretches from the inside of a cell to the outside. In so doing, they took a step toward improving on a new cancer therapy that is shaking up oncology. More than any potential use in cancer treatment, however, the studies suggest that it’s possible to engineer a customized switch into a cell — able to recognize any molecule in the body and turn on any genes in response. Cells might be able to sense molecules associated with injury and turn on genes that stimulate repair, for instance. Or they might sense molecules that scream “cancer” and activate genes that let the immune system kill tumor cells. Or they might even sense proteins that make up tiny, man-made scaffolds and fill them with bladder or liver or other specialized cells to create replacement organs. “It sounds like magic,” said Wendell Lim of the University of California, San Francisco, who led both studies. “But we think we can program cells to sense anything [in the body] and respond by activating any gene we choose.” Lim and his team made new versions of the inside-to-outside protein molecule called Notch, it lets cells sense who their neighbors are and what the neighborhood is like. Each Notch molecule is a nano-version of a member of a bucket brigade, standing in a doorway with one arm stretching outside, grabbing buckets, and the other reaching inside, passing the buckets along. Notch (a “receptor,” in bio-speak) basically grabs onto molecules outside the cell and then reaches into the cell’s nucleus to turn particular genes on or off. That results in, for example, the formation of blood vessels and brain neurons. Nature has made only four Notch molecules. Lim and his colleagues found that quite unimaginative. They therefore created new Notches, with new outside-sensing parts and new gene-activating parts, in mouse cells. Some of the newly Notched cells sensed a molecule commonly found on the immune system’s B cells and glowed emerald like the brilliant green fluorescence in some ocean creatures. Other mouse cells with man-made Notch proteins sensed the same molecule but turned on genes that caused the cells to become muscle cells. “We can engineer Notch to sense whatever [molecular] signal we want and hook it up to almost any gene we want to turn on,” said Lim. To repair damaged tissue, for instance, “you could engineer Notch to sense proteins released by the body as a result of injury and turn on genes in stem cells that cause them to differentiate into any cells you want,” perhaps those of damaged heart muscle or torn ligaments. In principle, Lim said, scientists could engineer Notch to sense man-made molecules, including those in the scaffolds that researchers are using to build organs. “There are so many possibilities,” he said. In the second study, the UCSF scientists created synthetic Notches for T cells, the immune system’s engulf-and-devour troops that are being used to destroy cancer cells. These cells have been somewhat successful against leukemia: Biologists have genetically engineered T cells to produce a molecule on their surface that recognizes and clutches targets on these cancerous cells. Trouble is, some of those tumor targets are also on healthy cells, so the engineered T cells (called CAR Ts, for “chimeric antigen receptor” T cells) ravage healthy cells, too. In addition, scientists haven’t managed to make CAR T cells that devour solid tumors. The UCSF scientists created T cells with both lab-made Notch and CAR receptors that sense molecules on cancer cells. Notch both recognizes a tumor-cell molecule and turns on genes that let the T cell recognize a second, different tumor-cell molecule. When they turned these engineered cells loose on tumors in mice, the scientists found that the cells devoured the tumors while sparing similar but healthy tissue. Harnessing that finding to produce a cancer therapy is years away, but if even one of the uses for lab-made Notch pans out, it will show that synthetic biology really can improve on nature.
_______
- Vaccines:
Synthetic biology has also been turned onto the challenge of developing new vaccines. A vaccine works by offering the body’s immune system a sample of the disease causing organism, known as an antigen, so that it can remember it and attack it if it invades in the future. An established way of doing this is called attenuation, in which a virus or bacterium is crippled so it cannot cause disease, but retains enough identifying features for the immune system to recognise it. This is, however, a delicate balancing act that doesn’t always work. One rather elegant piece of synthetic biology has been to produce an artificial cell-like body that can alert an immune system but not cause disease. It works by wrapping some genes and the mechanism to translate them in a membrane similar to our own cell membrane. The genes included can, in theory, be changed for those from any disease causing organism. This will result in little fatty bubbles, called liposomes, that resemble part of the virus or bacterium. However, because they contain nothing else they are not able to produce disease, removing at a stroke the balancing act of attenuation – that tricky process by which an infectious organism is deactivated but not totally destroyed.
_
Conventional vaccinations are usually delivered by injection; however, the procedure is not without risks or discomfort. One example of addressing this issue is engineering of oral plant tissue-based vaccinations, which considerably reduce the risk of contamination with mammalian pathogens and do not require costly purification and downstream processing. Moreover, rigid plant cell walls protect antigen degradation in the acidic environment of the stomach. For example, unicellular green alga Chlamydomonas reinhardtii chloroplasts were used for vaccine formulation against Staphylococcus aureus infection. Chloroplasts were engineered for stable expression of the D2 fibronectin-binding domain of S. aureus fused with a mucosal adjuvant cholera toxin B subunit, which improves antigen-specific immune responses. Mice treated with transgenic algae had significantly reduced pathogen load in the spleen and the intestine, and 80% of the pretreated mice survived lethal doses of S. aureus, which makes C. reinhardtii an attractive platform for oral vaccine development.
_
S.cerevisiae can also be manipulated to express foreign antigens that would stimulate an immunologic response. Recombinant yeast vaccines engineered to express viral or tumor antigens have been demonstrated to activate dendritic cells (DCs) and confer protective cell-mediated immunity against tumor cells. One example is S. cerevisiae vector engineered to express a transgene encoding human carcinoembryonic antigen (CEA), which is associated with tumor growth. Human DCs were activated by CEA and subsequently activated cytotoxic T-cells specific for CEA+ human tumor cells.
_
Reengineering of viruses for vaccine design is another interesting strategy in vaccine development. Thus, poliovirus was synthetically attenuated by recoding the poliovirus capsid protein with underrepresented codons and synthesizing the recoded DNA de novo. Recoding of poliovirus decreased rates of protein translation and resulted in attenuation of the virus in mice. The attenuated virus generated effective immune response in mice, indicating that virus attenuation via codon deoptimization could provide an alternative method of vaccine generation.
______
- Friendly Bacteria:
We carry inside us 10-100 times more bacteria than we do human cells. These are essential for life, helping us to digest food, produce some vitamins and ward off invading pathogenic bacteria. These bacteria, collectively called the microbiome, live happily inside us and are potentially excellent targets for synthetic biologists. One example is the development of E. coli, the common gut bacterium, that can help fight off cholera, at least in mice. The E. coli were engineered to produce a chemical signal that cholera bacteria use to coordinate infection. The signal effectively swamped and so jammed the cholera bacteria’s signals. Baby mice given these engineered bacteria followed, 8 hours later, by cholera bacteria had an increase in survival rates of 80% over mice given cholera alone [vide supra]. A second approach to utilising the microbiome is to engineer bacteria to produce useful drugs inside the body. The trick here would be to make sure that they are produced in the right amounts at the right place in the body, relying on the ability of synthetic biology to build in mechanisms to respond to external stimuli. These would turn on when they detect pathological conditions (rather like the cancer targeting bacteria), and turn off again when the disease has passed.
_
MIT biologists are reprogramming gut bacteria as “live therapeutics.” 2016 study:
The human gut microbiome — which includes the community of trillions of bacteria living within our intestines — has been called one of the next big frontiers in medicine. In recent years, a growing body of research has shown that the bacteria in our gut exert a powerful influence on our immune and endocrine systems, brain health, mood and cognitive function, and other key biological processes. In new research, biologists and medical engineers at the Massachusetts Institute of Technology are reprogramming gut bacteria to act as “living therapeutics” that can correct the metabolic dysfunctions underlying certain ailments. Lu and Dr. Jim Collins, Synlogic co-founder and biological engineer, developed “genetic circuits” made of synthetic DNA or RNA that carry instructions for certain bacteria, telling them to seek out and cure infections. Essentially, the researchers are tweaking the genetic codes within the bacteria in order to program them like a computer. The bacteria can be programmed, for instance, to detect inflammation in the gut and create anti-inflammatory molecules on the spot, as well as producing molecules to boost immune system function. So far, the research team has focused on programming E. coli Nissle (not to be confused with plain E. coli), a strain of bacteria found in the gut that’s widely used as a probiotic. Using this method could offer certain advantages over traditional treatments for inflammatory digestive disorders like Crohn’s disease and ulcerative colitis — it’s potentially more precise and safe than the commonly used anti-inflammatory treatments, the researchers say. Two synthetic biotics drug candidates — designed to treat rare genetic metabolic disorders by flushing toxic substances out of the body — are currently slated to enter clinical trials within the next year. Collins likens the drugs to “biological thermostats” — they “detect and regulate the amount of an enzyme or metabolic byproduct in a patient’s body.” One of the drugs is designed to treat urea cycle disorder, a rare condition affecting up to 6,000 people in the U.S. that impairs an individual’s ability to process ammonia. The other is for phenylketonuria (PKU), an inherited condition that causes a dangerous excess of the amino acid phenylalanine (which is found in food that contains protein) to accumulate in the body, forcing patients to undertake an extremely low-protein diet. PKU affects roughly 13,000 people in the U.S. “Synlogic is programming these probiotic microbes to consume ammonia or phenylalanine,” Collins explained in a statement. “They are reaching levels that are expected to be clinically meaningful, which is quite remarkable.” Ultimately, Synlogic is looking to create synthetic biotic treatments for not only rare genetic disorders but also for a range of ailments with metabolic components, including autoimmune diseases, cardiovascular disease and central nervous system disorders.
______
- Cellular and Regenerative Medicine:
An important topic is engineering of human cells to behave in specific, useful, ways. The challenge here is that the majority of synthetic biology to date has been done in bacteria. Mammalian cells like ours are significantly more complex and therefore significantly harder to engineer. However, it has been done. Mice have been engineered to contain a synthetic biological mechanism that is turned on by the presence of uric acid, the chemical responsible for gout, and produce enzymes that remove the uric acid. Once it is all gone then the mechanism turns off. This mimics the behaviour of many different natural cellular processes, miniature thermostats turning off and on in response to a myriad of chemical signals in the body. The system was tested in mice genetically engineered to over-produce uric acid. This new system succeeded in reducing their uric acid levels and the clinical problems such as gout and crystals in the kidneys associated with excess uric acid.
_______
- Early and better medical diagnosis:
Detecting urinary tract infection (UTI):
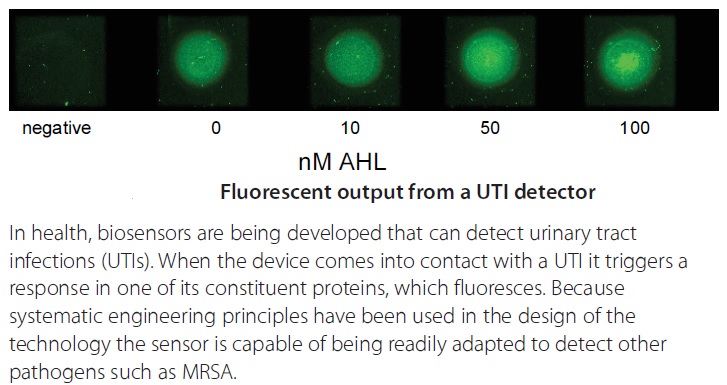
______
- Organ transplantation:
Synthetic Genomics has a major program that aims to change the pig genome so that pig organs — hearts, lungs, kidneys — can be used for organ transplantation into humans. Pig organs, particularly the heart and lungs, are about the same size as human organs, and if we can change a number of genes so they have human genes and human proteins, that will allow them to be transplanted without massive rejection.
_______
- Disease Mechanism Investigation in Immunological Disorders
Synthetic biology has been helpful in providing mechanistic insights into certain human disorders. In particular, it provided a framework for generating disease models and discovering new drug targets. For example, the contribution of genetic defects that result in abnormal B cell development in agammaglobulinemia, a primary immunodeficiency, was investigated by reconstituting functional parts of key natural complexes in an orthogonal environment. This approach is often implemented to provide an isolated, well-characterized environment. Patients were screened for genes that were expressed in the early stages of B cell differentiation. Once a defect in the immunoglobulin-β (Igβ) encoding gene was identified, the mutant Igβ and other constituents of the human B cell antigen receptor (BCR) were reconstituted on the surface of cultured Drosophila melanogaster cells. Mutant Igβ abolished the assembly of the BCR on the cell surface, and failure to assemble the BCR complex, in turn, caused a complete block of B cell development. The described process was proposed as a likely mechanism of agammaglobulinemia in some patients. In another example, synthetic presentation of an entire human peptidome on the surface of T7 phage allowed to discover new self-antigens (autoantigens) that could lead to autoimmune diseases. Enrichment of autoantigens was carried out using antibodies from patients with neurological syndromes. The enriched antigens were subjected to high-throughput sequencing, which revealed new antigens that could be used in accurate diagnostic tests and designing new therapeutics.
_____
- Sequence-Specific Endonucleases for disruption of Bacterial and Viral Infections:
Another novel approach of developing antibacterial and antiviral agents is exploitation of sequence-specific endonucleases, such as ZFNs, TALENs, or the CRISPR/Cas system. While the NHEJ pathway in most eukaryotes can quickly repair extensive site-specific double strand DNA breaks, poor efficiency or absence of this pathway in many prokaryotes can render the aforesaid endonucleases lethal. Thus, cytotoxicity of the CRISPR/Cas system was exploited for programmable removal of bacterial strains. It was shown that the CRISPR/Cas system targeting endogenous genes at species-specific sites can be employed for the development of species and even strain specific bactericidal agents. This was shown in an experiment with a mixed population of E. coli strains K-12 and BL21, with the extent of removal of >99.999% of the targeted bacterial strain. Genome editing tools can also be used to establish viral resistance in humans or develop potent virus disrupting agents. For example, HIV-1 resistance in human CD4+ T cells was established using a ZFN targeting human endogenous HIV coreceptor CCR5. When targeting directly viral genomes, TALENs and CRISPR/Cas9 were shown to be successful in disrupting hepatitis B virus and latent HIV-1 provirus, respectively.
_____
- Treatment of Metabolic Disorders:
Bacterial Devices:
Disorders of human metabolism encompass a diverse group of complex diseases that usually result from genetic enzyme deficiency or epigenetic alterations. For many metabolic disorders, treatment is currently unavailable, while others are controlled by dietary restriction or supplementation. With the aim of tackling these disorders, the first synthetic biology proof-of-principle studies have been conducted by engineering bacterial circuits capable of restoring normal metabolism. Thus, for treatment of diabetes, bacteria were engineered to stimulate intestinal epithelial cells to secrete insulin in response to glucose. E. coli strain Nissle 1917 was engineered to express and secrete glucagon-like peptide 1 (GLP-1) as well as pancreatic and duodenal homeobox gene 1 (PDX-1), proteins that are known to stimulate intestinal epithelial cells to synthesize insulin. Cultured epithelial cells grown in cell-free media pretreated with engineered bacteria were stimulated to secrete insulin up to 1 ng/mL. However, implementation of the strategy in commensal bacteria cocultured with epithelial cells in vitro or in vivo implementation is yet to be shown.
Mammalian Pharmaceutically Controlled Open-Loop Circuits:
To be more therapeutically relevant, the synthetic biology field is currently developing further by expanding its mammalian gene circuit repertoire. In particular, for the treatment of metabolic disorders, it is imperative to develop interactive gene networks that would stimulate the expression of therapeutics in a controlled, regulated manner. This can be achieved either by open-loop circuits, where an input signal triggers the output in a linear fashion, or a closed-loop circuit, where the output feeds back on the input signal, the latter giving a more stable output control. In a recent study, an open-loop circuit for the treatment of the metabolic syndrome was developed. Metabolic syndrome is a co-occurrence of functionally linked health problems, such as hypertension, hyperglycemia, obesity, and dyslipidemia, which are usually treated independently. In this study, a synthetic circuit was devised where a pharmaceutical targeting one of the health conditions, antihypertensive drug guanabenz, is also an input for the signal transduction to express GLP-1 fused to leptin. Both of the latter are therapeutic peptide hormones, GLP-1 stimulating the secretion of insulin and leptin regulating energy intake and expenditure. Administration of this circuit in mice with the metabolic syndrome phenotype resulted in simultaneous attenuation of hypertension, hyperglycemia, obesity, and dyslipidemia. Thus, this study demonstrated the feasibility of treating a complex metabolic health condition by obtaining a triple output upon the administration of a single input, a pharmacological drug.
Mammalian Closed-Loop Circuits:
Small-molecule drug-based intervention to treat physiological abnormalities in metabolic disorder patients may provide a controlled way of therapeutic delivery, yet prolonged daily administration of a drug can lead to unwanted side effects. To this end, the development of closed-loop circuits would be advantageous since it would remove the reliance on repeated administration of a therapeutic. Implementation of this approach was described using a prosthetic gene network that could sense and restore normal physiological uric acid levels through controlled expression of urate oxidase. Urate oxidase was put under direct control of bacterial uric acid sensor HucR, which binds its target DNA motif in the absence of uric acid. The synthetic circuit stabilized the blood urate concentration in urate oxidase-deficient mice with acute hyperuricemia.
Mammalian Open-Loop Optogenetic Devices:
Switching from drug-dependent gene regulation to molecule-free electromagnetic gene regulation in vivo for therapeutic applications is becoming another appealing approach. Thus, the field of optogenetics is becoming increasingly popular due to anatomical specificity and precise temporal control of gene expression. Recently, the first optogenetic device for the controlled production of a therapeutic protein in an animal disease model was reported. Here, shGLP-1 hormone was put under transcriptional control of melanopsin, a blue light sensor protein. Melanopsin belongs to a family of ion channel proteins, such as channelrhodopsin, that transform the light-based energy to ion-based membrane potential and trigger an intracellular signalling cascade. The calcium-dependent signalling cascade eventually activates a transcription factor that controls the expression of the hormone. Encapsulated cultured human cells were implanted in a mouse model of human type II diabetes. Upon illumination with blue light, type II diabetic mice showed improved glucose homeostasis.
______
Figure below shows health applications of synthetic biology and associated risks:
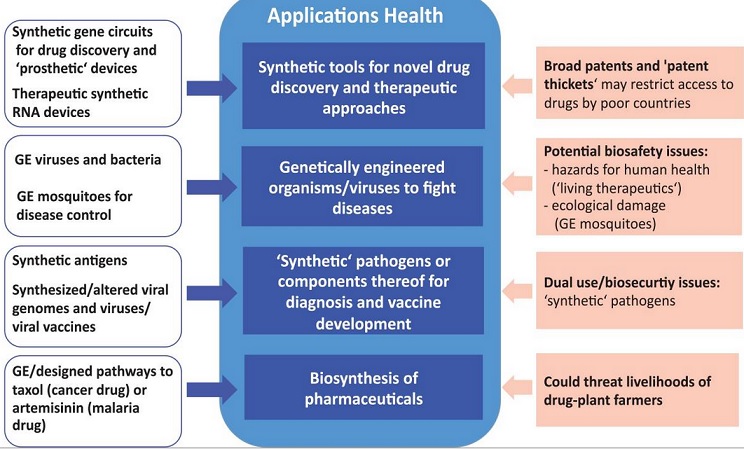
______
______
Synthetic biology for Energy and Biofuel:
Few things are certain in life, but one constant remains: a finite supply of fossil fuels cannot sustain the needs of a world population of 7.5 billion people. The need for biofuels is rapidly evolving at a global scale.
_
In an attempt to create renewable and sustainable carbon-based fuels, first-generation biofuels have been developed that are based on plant oils (biodiesel) or on cane sugar and crop starch (ethanol). Besides the “fuel-vs.-food” issue and negative effects on GHG emissions and biodiversity from land-use change, these fuels have undesirable chemical properties that prohibit their use for certain purposes or with existing infrastructure. New generations of biofuels based on non-edible, lignocellulosic plant parts, special energy grasses or microalgae have thus been envisaged. In addition, rather than producing biodiesel or ethanol, some approaches aim to create “drop-in” fuels that can use existing infrastructure and can be mixed with fossil fuels in any ratio. Drop-in fuels are those renewable fuels which can be blended with petroleum products, such as gasoline, and utilized in the current infrastructure of pumps, pipelines and other existing equipment. Under such a definition, a biofuel would require some percentage of gasoline blender , derived from unique gasoline stocks, to form the fuel’s base. These are based on synthetic hydrocarbons or higher-chain alcohols (like butanol) with high energy content, allowing gasoline, diesel and even aviation fuels to be replaced. In addition, strategies have been devised that use microorganisms to produce hydrogen. All these approaches involve synthetic biology ideas and can be ascribed to one of two fundamental strategies: the microbial synthesis of fuels from materials produced by plants or their direct microbial photosynthesis from CO2 and water. An early hope for synthetic biology was that it could wean society off fossil fuels. Engineering microbes to churn out hydrocarbons would presumably be a lot cleaner and more climate-friendly than extracting and burning coal and oil. Since 2000, the U.S. Department of Energy has poured millions of dollars into funding synthetic biology biofuels research, such as new types of algae to secrete biodiesel or other engineered fuels that don’t have to be pumped from the ground. So far, progress has been limited.
_
- Sugar to Biodiesel and Drop-In Fuels:
The transfer of multiple genes from different organisms into E. coli, and the deletion of different endogenous genes, allowed efficient new pathways to be generated for producing butanol and branched-chain higher alcohols from sugar. Of special interest with regard to the synthetic biology idea is that these include synthetic pathways based on computer-aided design with enzyme-based kinetic control mechanisms, allowing the efficient production of the non-native alcohol products. The generation of new pathways based on combining different genes from distinct organisms also allowed biodiesel and alkanes to be synthesized from sugar in E. coli, yeast and other fungi, and alkanes in microalgae. Noteworthy, for biodiesel production a first sensor-regulator system was designed and integrated in E. coli to adapt gene expression dependent on levels of a key intermediate (fatty acids) that significantly increased product yield. Since these approaches use available sugar (e.g. from sugar cane or corn), they do not depend on expensive technology to obtain sugar from lignocellulose or for direct light conversion (e.g. photobioreactors). At the same time, they allow to synthesize drop-in fuels.
_
Diesel is the most widely used liquid fuel in the world. This energy dense fuel supports the transport of 70 percent of U.S. commercial goods and is in high demand in the developing world to support the heavy equipment (trucks, bulldozers, trains, etc.) required for infrastructure development. Today there is no cost effective renewable alternative to diesel. LS9 has developed a platform technology that leverages the natural efficiency of microbial fatty acid biosynthesis to produce a diversity of drop-in fuels and chemicals. Using synthetic biology, LS9 has developed microbial cells that can perform a one-step conversion of renewable carbohydrates (sugars) to two diesel alternatives, a fatty acid methyl ester (biodiesel ASTM 6751) and an alkane (ASTM D975). Synthetic biology has been essential in engineering the LS9 microbial catalysts. The biosynthetic pathways to produce finished fuel products do not exist in the native E. coli host. LS9 designed the pathways, synthesized the genes encoding each enzyme in the pathway, and constructed multigene biosynthetic operons enabling production. To improve yield, productivity, and titer – the drivers of process economic efficiency – the biosynthetic pathways and host metabolism have required significant genetic optimization. LS9 developed capabilities for the computational design and automated parallel construction of gene, operon, and recombinant cell libraries that have enabled the rapid construction and evaluation of thousands of rationally engineered microorganisms. This capability in combination with state of the art screening, process development, and analytical methodologies has enabled LS9 in only a few years to advance from concept to a process slated for commercial-scale demonstration.
_
- Lignocellulose to Biodiesel and Drop-In Fuels:
Several pathway engineering approaches aim to synthesize biofuels from lignocellulosic polysaccharides (cellulose, hemicellulose), making available non-edible plant parts. For example, a pathway to produce isobutanol was constructed in a native cellulose-degrading bacterium using various genes from different organisms. Similarly, genes to make use of cellulose or hemicellulose were transferred into different microorganisms, some of them containing one or several exogenous genes, in order to synthesize butanol, biodiesel or hydrocarbons.
_
- Direct Synthesis of Biodiesel and Drop-In Fuels from Light, Water and CO2:
Higher photosynthetic yields per area, less need for arable land or the use of brackish or sea water have inspired various approaches aimed at producing biofuels in microalgae. These include the generation of new metabolic pathways by combining genes from distinct organisms in cyanobacteria to synthesize products that can be converted to or act as drop-in fuels, such as isobutyraldehyde or butanol derivatives. Cyanobacteria have also been metabolically engineered to efficiently produce and secrete fatty acids (to synthesize biodiesel) or alkanes, with secretion allowing continuous and energy-saving production schemes. In contrast to the previous examples, in the case of alkane synthesis and secretion, introducing as few as two genes from other cyanobacteria was sufficient to build a pathway for linear alkane synthesis and a module for alkane secretion, allowing to generate these functions in robust cyanobacterial genera that may be exploited for industrial use. However, although different studies have suggested the technical feasibility and economic viability of industrial-scale biofuel production by microalgae, there is as yet no such product on the market.
_
Direct photosynthetic production of biofuels may strongly benefit from higher efficiencies in solar light conversion and by reducing the amount of biomass that has to be grown. A nascent concept taking these factors into account is microbial electrosynthesis, which may be described as an artificial form of photosynthesis to produce organic compounds and energy-rich fuels. Here the higher efficiency in photovoltaics to harvest light energy (compared to natural photosynthesis) can be used to supply electrons via electrodes to certain microorganism in order to reduce CO2 to multicarbon products. Recently, electrosynthesis of isobutanol and 3-methyl-1-butanol (which can be used as drop-in fuels) has been achieved by introducing a synthetic metabolic pathway to these products (previously constructed in E. coli) into the lithotrophic bacterium Ralstonia eutropha.
_
- Microbial Synthesis of Hydrogen from Light and Water:
The prospective use of hydrogen as a non-carbon fuel has raised interest in certain photosynthetic microorganisms, such as algae and cyanobacteria, that can produce hydrogen from water and light. Effective production, however, is limited by several issues, including the oxygen sensitivity of hydrogenases (the enzymes that can reduce protons and release molecular hydrogen) and inefficiencies in utilisation of solar light energy. So far, several approaches based on alteration of the expression of genes, including those for light-harvesting proteins, or the introduction of heterologous hydrogenase genes have aimed to improve hydrogen production by increasing the efficiency of light conversion or by reducing oxygen production or sensitivity in green algae and cyanobacteria. Rather than these more “traditional” genetic engineering approaches, synthetic biology approaches to construct new pathways for microbial hydrogen production might significantly contribute to solving these problems in the future.
_______
_______
Synthetic Biology in food industry:
The early interest of Synthetic Biology (SynBio) companies was in the area of new biofuels and alternatives to petroleum-based products. However, the companies are finding it increasingly difficult to break into established commodity markets because of high volumes and low prices, and the lower crude oil prices that do not make them cost-competitive. As a result, Synthetic Biology companies are now turning to high value low volume fine chemicals like food and fragrance ingredients to target immediate and attractive consumer markets (Hayden, 2014). Synthetic Biology has been slowly entering the food market with the entry of SynBio vanillin in 2014. Some of the recent examples for the commercial deployment of Synthetic Biology approaches in the food sector and those in lab trials are listed in the table below:
Synthetic Biology products/ pipeline for food industry:
| Product (Application Category) | Developer (Partner) | Current Status |
| Resveratrol (Dietary supplements) | Evolva | Launched in 2014 |
| Vanillin (Flavour and fragrance) | Evolva (IFF) | Launched in 2014 by IFF |
| Nootkatone (Flavour and fragrance) | Evolva, Isobionics | Launched in 2015 |
| Valencene (Citrus Flavouring) | Evolva, Isobionics | Launched in 2015 |
| Stevia (Sweetener) | Evolva (Cargill) | Scale-up |
| Saffron (Flavour and fragrance) | Evolva | Development phase |
| Animal-free milk (from Yeast) | Muufri | Lab trials |
| Real Vegan Cheese (milk from yeast) | Counter Culture Labs & BioCurious | Lab trials |
| Animal-free egg white | Clara Foods | Lab trials |
_
Synthetic biology could solve our banana problem:
The research findings published by the group of scientists from Wageningen University in the Netherlands claim that an aggressive fungus known as “Panama Disease” is at risk of wiping out the Cavendish banana – the world’s most popular banana – within a few years. This wouldn’t be the first time Panama Disease struck – in the 1960s, it drove another type of banana – the Gros Michel – to near-extinction. What’s concerning is that a new strain of Panama Disease has now appeared, for which bananas have no real defense. Moreover, the new strain appears to be resistant to current fungicides. Cavendish bananas account for 99 percent of all bananas in the world, so this is a big problem. Synthetic biology could come to the rescue. In this case, the DNA of the Cavendish banana could be genetically engineered to resist the Panama Disease that the Dutch researchers isolated as the source of a potential banana extinction. The fungus attacks the banana by destroying the banana plant’s water-transporting mechanism, causing it to wilt rapidly and die of dehydration. So any edits to the banana DNA would need to figure out a way to rehydrate the banana — or prevent the fungus from striking in the first place. This new, synthetically modified banana would look like a real banana and taste like a real banana and it would have almost exactly the same DNA as a real banana — except that it would be engineered in a bio-foundry by a team of technologists. This genetically engineered banana would have some of its genetic material designed or edited to behave differently than it does now.
_
There are a growing number of genetically-engineered foods that are being created. Would you believe meat that’s made in a laboratory? Or eggs that have been derived from plants, not chickens? Or how about milk that’s made from genetically-engineered yeast? Some synthetic biology innovators even talk about a “post-animal bio-economy,” in which we don’t even need animals to produce certain dairy or protein products. The company producing milk from bacteria is called Muufri. Pronounce the name the right way, and you get what the big idea is – “moo-free” milk. Milk without cows. Thanks to current gene-editing techniques such as CRISPR, it’s possible to create apples that don’t turn brown after you slice them and potatoes that don’t bruise. Recently, the FDA recently approved genetically-engineered salmon that’s able to grow faster than regular salmon, marking the arrival of the first-ever genetically-engineered food product that has been approved for human consumption within the United States.
_
The fact that Synthetic Biology has been used in making an ingredient does not mean it is unsafe, unnatural and unregulated. The SynBio based products may be identical to the compounds made using traditional methods or as extracted from plants and hence might be safe for consumers. Describing the process as natural brewing technology should not exempt the manufacturers from disclosing that a Synthetic Biology approach has been adopted in making an ingredient. Safety aside, the consumer should know the process involved in making the ingredient and be given a choice to opt for it. The full potential of Synthetic Biology as a new tool in commercial biotechnology can be realised only if there is transparency and open information exchange among all the stakeholders involved. One company, Sample6, is working toward finding and eliminating potentially life-threatening bacterium in food before it hits shelves. Its integrated systems quickly and easily detect harmful or unwanted bacteria in products for a wide variety of industries, including food and healthcare. They’ve developed a test kit that can detect Listeria, for example, while food is still in the processing plant. Such kits provide results in just three to four hours, while the traditional process can take up to 48 hours.
_
Non-traditional food sources:
NASA has studied the potential of algae and cyanobacteria to provide nutritional diets for spacefaring humans since the 1960s. One ounce of the cyanobacterium seaweed spirulina contains just 80 calories, 2 grams of fat, 1 gram of dietary fiber, 16 grams of protein, and 44% of the daily recommended intake of iron. Synthetic biology aims to improve on those numbers even further. Algae companies such as Aurora Algae, Blue Marble Biomaterials, and Solazyme are just some of the names targeting nutraceutical applications for their platforms. The nutritional oils these companies produce can replace pricey, unhealthy oils currently accepted as the status quo in foods. If Solazyme has its way, then a healthy diet may one day include ice cream, candy, and cookies. Dr. J. Craig Venter, founder of Synthetic Genomics, even sees synthetic biology disrupting the world’s meat production. According to Venter, “It takes 10 kilograms of grain and 15 liters of water to produce one kilogram of beef.” It will be a long while before you eat meat grown in a bioreactor, but the day will surely come. One company called Real Vegan Cheese is made up of a team of biohackers who are creating a substance that has the same molecular identity as cow’s milk. This milk is then used to make vegan cheese — a cheese made from what is essentially real cow’s milk, only with zero animal involvement. Perfect Day Foods is a company making dairy products without cows; Clara Foods, who are using cell culture to make egg whites; and an avian tissue research project with the goal of producing turkey and chicken meat without animals. Cellular agriculture has endless possibilities, including the ability to make more nutrient-packed foods with a longer shelf life, as well as foods tailored for specific uses and preferences, such as meat with lower saturated fat, lactose-free milk, cholesterol-free eggs, or egg whites specifically intended for different baked goods like meringues or fluffy angel food cakes.
_____
Synthetic biology in agriculture:
Synthetic biology – an emerging science that involves the design and construction of biological devices and systems for useful purposes – could impact agriculture. Synthetic biology could bring the following to agriculture: the ability to raise crops with fewer pesticides; greater food security; improved nutrition; livestock that could produce medications or biological substances; and, an optimal source of biofuel. Anything that can be made in a plant can now be made in a microbe. Many forms of life being developed by synthetic biology are, however, being patented, thus the benefits will reflect the economic interests of those who invest in and develop them.
_____
_____
Industry:
_
Naturally Replicating Rubber for Tires:
Isoprene is an important commodity chemical used in a variety of applications, including the production of synthetic rubber. Isoprene is naturally produced by nearly all living things (including humans, plants and bacteria); the metabolite dimethylallyl pyrophosphate is converted into isoprene by the enzyme isoprene synthase. But the gene encoding the isoprene synthase enzyme has only been identified in plants such as rubber trees, making natural rubber a limited resource. Currently, synthetic rubber is derived entirely from petrochemical sources. DuPont, together with The Goodyear Tire & Rubber Company, is currently working on the development of a reliable, high-efficiency fermentation-based process for the BioIsoprene™ monomer, and synthetic biology has played an important role in making this undertaking a reality. Although plant enzymes can be expressed in microorganisms through gene transfer it is a long and cumbersome process, as plant genes contain introns and their sequences are not optimized for microorganisms. DNA synthesis and DNA sequencing have enabled the construction and rapid characterization of metabolically engineered microorganism strains to produce isoprene. Synthetic biology has enabled the construction of a gene that encodes the same amino acid sequence as the plant enzyme but that is optimized for expression in the engineered microorganism of choice. This method has provided massively parallel throughput which has made it possible to identify and track genetic variation among the various strains, providing insights into why some strains are better than others. Continued use of synthetic biology should help refine DuPont’s biocatalyst for the production of BioIsoprene™ monomer.
_
Delivering Economic, Renewable BioAcrylic:
Acrylic is an important petrochemical used in a wide range of industrial and consumer products. Acrylic ingredients make paints more durable and odor-free, adhesives stronger and longer-lasting, diapers more absorbent and leak-proof, and detergents better able to clean clothes. Today, petroleum-based acrylic is an $8 billion global market. OPX Biotechnologies (OPXBIO) is developing renewable biobased acrylic to match petro-acrylic performance and cost but with a 75 percent reduction in greenhouse gas emissions. BioAcrylic from OPXBIO also will reduce oil-dependence and offer more stable prices. The key to realizing these benefits, as with any biobased product, is a highly productive and efficient microbe able to use renewable sources of carbon and energy (for example corn, sugar cane, or cellulose) in a commercial bioprocess. A microbe that meets these criteria for BioAcrylic has not been found in nature, so OPXBIO is applying its proprietary EDGE™ (Efficiency Directed Genome Engineering) technology to redesign a natural microbe to achieve these goals. With EDGE, OPXBIO rapidly defines and constructs comprehensive genetic changes in the microbe to optimize its metabolism for economical production of BioAcrylic. OPXBIO has advanced its BioAcrylic production process from pilot to large demonstration scale. The company has established a joint development agreement with The Dow Chemical Company, the largest producer of petro-acrylic in the United States, to bring BioAcrylic to market by 2016.
__
Bioplastics:
Metabolix is bringing new, clean solutions to the plastics, chemicals and energy industries based on highly differentiated technology. For 20 years, Metabolix has focused on advancing its foundation in polyhydroxyalkanoates (PHA), a broad family of biopolymers. Through a microbial fermentation process, the base polymer PHA is produced within microbial cells and then harvested. Development work by Metabolix has led to industrial strains of the cells, which can efficiently transform natural sugars into PHA. The recovered polymer is made into pellets to produce Mirel™ Bioplastics by Telles products. Conventional plastics materials like polyvinyl chloride (PVC), polyethylene teraphthalate (PET), and polypropylene (PP) are made from petroleum or fossil carbon. The PHA in Mirel bioplastics is made through the fermentation of sugar and can be biodegraded by the microbes present in natural soil or water environments. Although PHAs are produced naturally in many microorganisms, the cost and range of compositions required for successful commercialization dictated that PHA pathways had to be assembled in a robust industrial organism that does not naturally produce the product. Metabolic pathway engineering was used to accomplish this task, relying on modern tools of biotechnology. These include DNA sequencing and synthetic construction of genes encoding the same amino acid sequence as in the donor strain, but optimized for expression in the engineered industrial host. These technologies provided rapid development and optimization of robust industrial production strains that would not have been feasible using classical techniques relying on isolation and transfer of DNA from one species to the other. This has allowed Metabolix to successfully commercialize Mirel bioplastics. More than 50 years after it was first considered as a potentially useful new material and following several efforts by leading chemical companies to commercialize PHAs based on natural production hosts, Metabolix has made these products available at a commercial scale.
_
Materials production:
By integrating synthetic biology approaches with materials sciences, it would be possible to envision cells as microscopic molecular foundries to produce materials with properties that can be genetically encoded. Recent advances towards this include the re-engineering of curli fibers, the amyloid component of extracellular material of biofilms, as a platform for programmable nanomaterial. These nanofibers have been genetically constructed for specific functions, including: adhesion to substrates; nanoparticle templating; and protein immobilization. Until recently, creating silk has been the exclusive domain of silkworms and some spiders, as well as the occasional superhero. Today, though, inside the laboratories of Bolt Threads in Emeryville, Calif., fermentation tanks use yeast, sugar—and some DNA code borrowed from spiders—to form a material that is then spun into fibers the way traditional silk, rayon, and polyester is made. The result, the company says, is fabric that is stronger than steel, stretchier than spandex, and softer than silk. “This is a new era of materials,” says Dan Widmaier, Bolt’s CEO. Most textiles today are made from petroleum-based polyester, which is harmful to the environment when disposed of. By contrast, Bolt’s fabric will be biodegradable, the company says. As Widmaier puts it, the new material “has massive potential to change the world for the better.”
_
Industrial Enzymes:
Researchers and companies utilizing synthetic biology aim to synthesize enzymes with high activity, to produce products with optimal yields and effectiveness. These synthesized enzymes aim to improve products such as detergents and lactose-free dairy products, as well as make them more cost effective. The industrial enzyme industry is in search of sustainable processes that enable higher yields, more enzyme production; and higher activity, more efficient, affective, dynamic enzymes. From creating lactose-free dairy products to fast-acting laundry detergents, innovation is key in engineering improved, cost-effective end-products for textiles, foods, detergents, animals, and more.
_______
_______
Cleaning up environment:
The toxic contamination of soil and water and an increase in atmospheric greenhouse gases (GHGs) due to human activities, including industrial production processes and the use of fossil fuels, have become major environmental issues on a global scale. These may be addressed by several approaches related to the synthetic biology idea. Microbes are already used at oil spill sites, eating petroleum components and converting them into less hazardous by-products. Designing synthetic versions that can do the job quicker, and perhaps break down more stubborn pollutants such as pesticides and radioactive waste, would be a logical next step. Researchers at Spain’s National Center for Biotechnology have designed circuits capable of redirecting microbes to feast on industrial chemicals instead of sugar.
_
Environmental cleaning can be done through various synthetic biology approaches:
- Environmental (Whole-Cell) Biosensors:
Bacteria equipped with pollutant-responsive gene-regulation units and/or metabolic pathways for pollutants, coupled to reporter genes, have early been generated to detect and measure environmental contaminants such as heavy metals, explosives or pesticides.
_
- Removal of Environmental Pollution by Genetically Engineered Organisms:
While decontamination of water or soil by microorganisms (bioremediation) is a process that can occur naturally (intrinsic bioremediation), it may be enhanced by the addition of nutrients (biostimulation), additional microorganisms (bioaugmentation) or by plants (phytoremediation). Synthetic biologists are trying to engineer microorganisms to remediate some of the most hazardous environmental contaminants, including heavy metals, and nerve agents like sarin. Such organisms have enormous potential for decontaminating hazardous waste spills and treating byproducts from nuclear energy and disposal sites.
_
Biocatalytic carbon capture:
Installing post-combustion carbon capture, or PCCC, systems in a power plant can be pretty cost-prohibitive, which puts those calling for increasingly tougher pollution and emissions regulations in a tough spot. Storing carbon dioxide underground can be even more expensive, besides the fact that it has been demonstrated at only relatively small scales. Enzyme producers Codexis and CO2 Systems teamed up with Alcoa and the Department of Energy to pioneer a different approach. Codexis hijacked microbial genomes to increase the carbon capture ability of natural carbonic anhydrase by 2 million-fold, which could reduce scrubber column size by 95%, chemical use by 80%, and capital expenditures for a PCCC system by $146 million. The technology not only reduces emissions and costs but also stores carbon in various alumina and fertilizer products — effectively turning CO2 into a revenue stream.
_
- Production of Chemicals from Renewable Sources:
Based on multiple genes from different organisms, pathways have been constructed and optimized by metabolic engineering to efficiently produce chemicals in microorganisms and plants. For instance, in an attempt to produce biodegradable plastics, a pathway to synthesize lactic acid from sugar was generated in E. coli and switchgrass (Panicum virgatum L.) was engineered to produce polyhydroxy-alkanoates (PHA). Likewise, a complex pathway (made of an optimized plant gene and 8 genes from yeast) was transferred to and expanded in E. coli to synthesize isopenoids, and various genes from Klebsiella pneumonia and yeast were used to construct a pathway in E. coli to directly produce the commodity chemical 1,3-propanediol from glucose. Interestingly, a new efficient pathway for the biosynthesis of a chemical that is produced in nature in trace amounts only was constructed by adding a single enzyme activity to an organism. Thus, an artificial pathway for the efficient production of isobutene, a chemical that can be used to synthesize plastics, rubber or fuels, has been generated in E. coli, based on the introduction of a mevalonate diphosphate decarboxylase (MDD) activity derived from a protein-engineered version of an MDD from an archebacterium (that cannot produces isobutene). Finally, we would like to acknowledge the recent generation of E. coli strains that directly produce 1,4-butanediol (BDO), an important commodity chemical for products such as plastics, rubber or solvents.
_
Making “Green Chemicals” from Agricultural Waste:
Surfactants are one of the most useful and widely sold classes of chemicals, because they enable the stable blending of chemicals that do not usually remain associated (like oil and water). Today, nearly all surfactants are manufactured from either petrochemicals or seed oils, such as palm or coconut oil. Worldwide production of surfactants from petrochemicals annually emits atmospheric carbon dioxide equivalent to combustion of 3.6 billion gallons of gasoline. Production from seed oil is greener, but there is a limit to the amount of seed oil that can be produced while protecting the rainforest. To address this problem, Modular has developed microorganisms that convert agricultural waste material into useful new surfactants. Dr. P. Somasundaran of the University Center for Surfactants (IUCS) at Columbia University finds that Modular’s surfactant is 10-fold more effective than a similar commercially available surfactant. Modular has developed an engineered microorganism that converts soybean hulls into a surfactant for use in personal care products and other formulations. The hull is the woody case that protects the soybeans, and it cannot be digested by humans or other monogastric animals, such as pigs. The U.S. produces about 70 billion pounds of indigestible soy carbohydrate annually, and Modular seeks to upgrade this underutilized material by converting it into a variety of useful new chemical products.
_
Pigeon poop goes green:
Health officials are concerned with the health risks posed by pigeon poop droppings, which can harbor dangerous fungi and bacteria. Where does synthetic biology come into play? A harmless microbe, such as those in yogurt, was designed to be fed to and temporarily change the gut flora of these annoying, city-dwelling birds. The concept proposes that the modified birds could be released into the urban wild wielding their biodegradable, environmentally friendly surfactant droppings.
_____
_____
Synthetic biology research to meet critical Army needs:
Living organisms have a unique set of capabilities as they can reproduce, repair and heal themselves, and can sense, respond and adapt to their environment. These are processes that are controlled at the genetic level and are harnessed through synthetic biology. Integrating these types of engineered cells into devices enables autonomous biohybrid systems to be developed with unparalleled capabilities. The potential systems that could be developed include synthetic photosynthetic genetic circuits, which could be introduced into the bacteria integrated into electronic devices to power them. Other robust bacteria could be genetically engineered with biological tasting or smelling capabilities that interface with the electronics to form an advanced biosensor. Custom consortia, or mixed-cell populations, could be tailored to produce biochemicals on demand under field conditions, as a probiotic to protect Soldiers from infection, or genetically tuned to form smart, living paints. In order to move synthetic biology to the field, where it will benefit the Soldier, scientists need to use a host organism, or chassis, that can survive and thrive under field conditions. Synthetic biology has been largely built upon E. coli, and complex genetic systems continue to be engineered in this bacterium. However, E. coli is highly adapted to laboratory conditions and is no longer a suitable synthetic biology host for the field. So synthetic genetic systems must be inserted into fieldable organisms to meet army needs.
_
Synthetic biology to help colonize Mars:
Synthetic biology can greatly accelerate the development of human space exploration, to the point of allowing permanent human bases on Mars within our lifetime. Among the technological issues to be tackled is the need to provide the consumables required to sustain crews, and using biological systems for the on-site production of resources is an attractive approach. However, all organisms we currently know have evolved on Earth and most extraterrestrial environments stress the capabilities of even terrestrial extremophiles. Two challenges consequently arise: organisms should survive in a metabolically active state with minimal maintenance requirements, and produce compounds of interest while relying only on inputs found in the explored areas. A solution could come from the tools and methods recently developed within the field of synthetic biology. Cells brought along for the journey could be cultured using the abundance of elements and sunshine found on Mars to produce dietary supplements, building materials, and even biopolymer resins for 3-D printing factories. Photosynthetic algae and bacteria could even be spread across the planet to pump greenhouse gases and oxygen into the Martian atmosphere and create a habitable environment, albeit over the course of decades or even centuries. Ironically, our evolution into a multiplanetary species may very well hinge on our ability to work with bacteria.
_____
_____
Synopsis of potential areas of applications for synthetic biology is delineated in the table below:
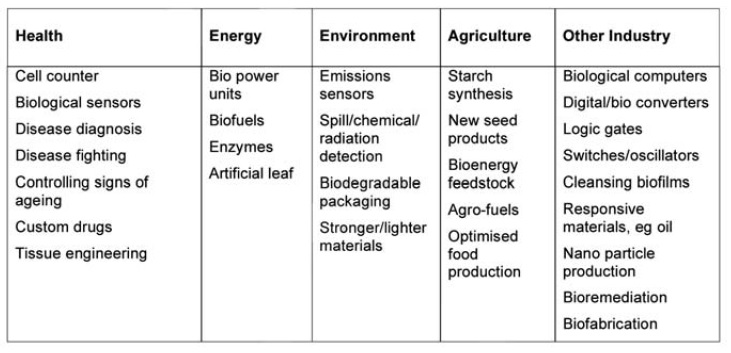
______
______
Potential benefits of synthetic biology:
The benefits of pursuing synthetic biology can be divided into two categories: advancing basic knowledge and creating new products. Needless to say, the distinction between basic knowledge and practical applications is hardly watertight. For example, to get his commercial venture of creating the minimal genome platform off the ground, Venter and colleagues have to first do the basic scientific work of determining what are the minimal requirements for life. Nonetheless, it is a distinction often used in these discussions and has been described as a “central tension in synthetic biology.”
_
Advancing knowledge and understanding:
One goal of synthetic biology is to better answer basic questions about the natural world and to elucidate complex biological processes—about how DNA, cells, organisms and biological systems function. How did life begin? How does a collection of chemicals become animated life? And, of course, what is life? Synthetic biologists take to heart the last words that the physicist Richard Feynman putatively wrote on his chalkboard: “What I cannot create I do not understand.” One of the hopes is that, by engineering or reengineering living organisms in the lab, synthetic biologists will be able to understand how the biological world works in areas where earlier analytical approaches fell short. As the molecular biologist Steven Benner has suggested, the proof of the pudding may be in the making. Scientists like Benner hope that synthetic biology will allow for biological hypotheses to be tested more rigorously.
_
Creating useful applications:
A second sort of benefit of synthetic biology would come in the form of practical applications, such as the creation of new energy sources, new biodegradable plastics, new tools to clean-up environments, new ways of manufacturing medicines and new weapons. It is hoped not only that these applications will create products that are completely new but also that their production will be cleaner, faster and cheaper than we can currently achieve. Perhaps precisely because many of the objections to “re-engineering nature” may stem from concerns about the environment, scientists and funders interacting with the press have particularly stressed the potential “green” synthetic biology applications: from biofuels to carbon sequestration, from oil spill remediation to arsenic-sensing bacteria. To use an example that is closer to market, Keasling’s work to engineer bacteria to produce artemisinic acid is notable not because this is a novel drug we do not know how to acquire; it is a naturally occurring product of the sweet wormwood herb. The problem, as Keasling sees it, is that the plant takes too many months to grow, and harvest yields are simply too small to meet the global need for effective malaria combination treatments. Even at around $2.40 per treatment, the parts of the world that need multi-course antimalarials most are least able to afford them. By combining genes and molecular pathways from the wormwood plant, bacteria and yeast into a bacterial “chassis,” Keasling trusts that the medication’s cost can be driven down to pennies; his teams have already increased synthetic artemisinin output 10-million-fold since the first experiments in 1999. Here the economic benefits of synthetic biology have the potential to have a positive impact on public health. Many scientists see Keasling’s work as only the beginning. Projects such as Endy’s Biobricks Foundation and Venter’s biological specimens circumnavigation are creating massive genetic sequence repositories that will make it possible to avoid starting from square one with each new project. Researchers associated with these projects are working to describe existing, and to create new, bio-parts and bio-tools so that the next pharmaceutical does not take many tens of millions of dollars and hundreds of person-years of effort to produce. The iGEM competition for undergraduates was founded to show that it does not take a doctoral degree to design a biotechnology product. Much of the economic promise of synthetic biology rests in its rational approach to biological design, which could reduce research and development time. Other efforts go beyond the “biofactory” models, which have been the bread and butter for the biotechnology industry since the development of biosynthetic drugs like insulin. Researchers are working to engineer a tumor-destroying bacterium. Other groups, including the Defense Advanced Research Project Agency, have funded early projects to develop biological computers. The Defense Science Board Task Force on Military Applications of Synthetic Biology is studying possible ways to apply synthetic biology to military technology. De novo protein engineering could allow for the creation of wholly new gene products, for which no known natural template exists. Instead of searching for a vaccine from known compounds, scientists hope to be able to design new targeted cures. Proponents of human enhancement technologies are excited about prospect of creating artificial chromosomes containing genes that would dramatically augment human traits—or create wholly new ones.
______
______
Risks and criticisms of synthetic biology:
An assessment of the risks involved in synthetic biology research must begin with two obvious points. First, because engineered microorganisms are self-replicating and capable of evolution, they belong in a different risk category than toxic chemicals or radioactive materials. Second, some of the risks of synthetic biology are simply indefinable at present — that is, there may be risks that we cannot anticipate with any degree of precision at this early stage in the development of the field. That said, we can use history as a guide — particularly the history of recombinant DNA technology — to discern three main areas of risk in synthetic biology. First, synthetic microorganisms might escape from a research laboratory or containment facility, proliferate out of control, and cause environmental damage or threaten public health. Second, a synthetic microorganism developed for some applied purpose might cause harmful side effects after being deliberately released into the open environment. Third, outlaw states, terrorist organizations, or individuals might exploit synthetic biology for hostile or malicious purposes.
_
Synthetic biology raises many ethical, environmental and moral concerns.
Below are a few:
- Effects are irreversible — synthetic biology intend to permanently alter a species, with the potential for irreversible ripple effects, including possibly wiping out a species entirely, whether intentionally or by accident. Driving a specific trait through a population, plants or other organisms could also lose the natural diversity that enables survival and adaptation in different environments and under different environmental pressures.
- Unintended consequences of permanently changing species — there are many unresolved problems, such as off-target and non-target effects, or horizontal gene transfer. For example, how would engineered mosquitoes continue to evolve? How would they impact the ecosystem? If a mosquito species were to be eradicated, would a more invasive species fill the space? What would the impact be on all of the species that feed on mosquitoes?
- Agricultural impacts could be severe — synthetic biology has huge potential for big agribusinesses, which have a special interest in redesigning a seed or plant for maximum profit potential. Applications might include engineering wild plants to respond to use of particular chemicals or wiping out a weed or insect entirely. For example, eradicating pigweed, a weed in the U.S. that is closely related to the South American crop amaranth could have severe impact. If an engineered gene to eradicate pigweed were to cross-pollinate with amaranth and spread into South America, drastic problems affecting livelihoods of farmers and food security could result. Secure food systems, particularly in a climate uncertain future, will require maximum diversity and resilience.
- Potential for military or commercial misuse — synthetic biology obviously has the potential to be misused (think bioweapons). Insects engineered to carry disease? Seeds designed to deliberately suppress food crops or crash a harvest? These scenarios could have widespread and profound impacts. We need systems in place to prevent them.
- There are no regulations to prevent accidental escape in synthetic biology, and voluntary regulations are guaranteed to fail as synthetic biology knows no political boundaries. Therefore we need international regulations, not a patchwork of national regulations from countries where corporations dominate politics.
- Applications of synthetic biology pose enormous potential impacts on biodiversity and the livelihood and food security of smallholder farmers, forest-dwellers, livestock-keepers and fishing communities who depend on biodiversity, especially in the developing world.
- The behavior of synthetic biological systems is inherently uncertain and unpredictable, yet the precautionary principle is not guiding research and development of synthetic organisms. Risk assessment protocols have not yet been developed to assess the potential ecological risks associated with synthetic biology. Synthetic organisms are currently being developed for commercial uses in partial physical containment (i.e. fermentation tanks or bioreactors) as well as for intentional non-contained use in the environment. Many of the researchers who are most active in the field of synthetic biology do not have training in biological sciences, biosafety or ecology.
- Although existing national laws and regulations may apply to some aspects of the emerging field of synthetic biology, there is no comprehensive regulatory apparatus for synthetic biology at the national or international level.
_
New methods in risk assessment:
Researchers must decide whether a new synbio technique or application is safe enough (for human health, animals, and the environment) for use in restricted and less-restricted settings. The following examples of synbio products and technologies warrant a review and adaptation of current risk assessment practices:
- Newly created DNA-based systems and parts that are substantially different from existing life forms
- Novel minimal life forms and whether they will survive in different environments
- The potential infectious nature and survivability of newly created protocells
- Exotic biological systems based on alternative biochemical structures (e.g., expanded genetic code and genetic alphabet).
Synthetic biology, however, is not just about new risk. It is also about constructing new biological systems that make biology even safer to engineer. For this reason, researchers also need better safeguards.
_
Despite potential benefits, critics of synthetic biology—university ethicists, some journalists and conservative religious groups—have argued that the emerging field will create a world of Frankensteins and unnatural beings. They worry that releasing synthetic life into the environment, whether done deliberately in a potential environmental application or by accident, could have an adverse effect on our ecosystem. These technologies, they argue, could be used for bioterrorism that would do enormous amount of damage, because synthetic biology allows for the construction of microorganisms that would have incapacitating, or lethal, effects on humans. This argument is very similar to the “unintended consequences” argument used by anti-GMO critics. Without any real evidence of likely dangers, critics conjure up fears as a way of convincing people to distrust this new technology. Critics have also argued that the benefits of synthetic biology are not significant enough to justify the associated risks. For thousands of years, science and religion have clashed, and the notion of “playing God” seems to be the basis for objection each time. Nearly every biotechnological accomplishment—the advent of anaesthesia, birth control, stem cell research and genetic engineering, to name a few—has been met with objections and charges that scientists have violated the natural order. However, this argument ignores the great strides made by science to feed the hungry and heal the sick. Surely, the “natural order” these critics refer to includes the progress of scientists to positively impact mankind. Without scientific progress that was initially described as ‘going against nature,’ humankind wouldn’t have found cures for deadly diseases or solutions to some of our biggest problems, such as finding a cure for polio or discovering the structure of DNA. Yet, it is the religious and philosophical issues that get most of the media attention, which often detracts from the progress being made as scientists address the risks of synthetic biology. Synthetic biology promises better drugs, less thirsty crops, greener fuels and even a rejuvenated chemical industry. Synthetic biology can help fight climate change and pollution. Potential benefits of synthetic life far outweigh risks Craig Venter said to the BBC in May of 2010: “Most people are in agreement that there is a slight increase in the potential for harm but there’s an exponential increase in the potential benefit to society.” People are generally more fearful of human-made risks, and less so of natural ones. That a bacterium can spontaneously evolve into a new version that can resist our arsenal of antibiotics doesn’t seem to bother people as much as the possibility that we can now manufacture such mutants. In fact synthetic organisms are unlikely to survive out of lab. There is a common misconception that synthetic biology is unnatural and more dangerous than genetic engineering. But the overwhelming majority of synthetic biology projects present little or no risk, especially when confined to biomanufacturing—that is, fermentation in large tanks to produce particular compounds and molecules. The most common industrial host organisms, such as special strains of yeast and bacteria that cannot survive outside a lab environment, have been used safely for 30 years.
__
Two threats more specifically associated with synthetic biology applications may emerge:
- Large-scale custom DNA synthesis (and new genome-assembly techniques) combined with knowledge from functional genomics on pathogens might facilitate the generation and malicious use of new pathogens by both nation states and non-state actors (e.g. rogue individuals or terrorist groups). Various governance options have been suggested both within and outside the field, concerning screening procedures for DNA synthesis, its equipment and reagents, or ethical training of researchers. Though much biotechnology knowledge and expertise has likely already proliferated globally, recent studies into various assessments on bioscience research and bioterrorism suggest that the attractiveness and feasibility of “synthetic” solutions for bioterrorist use may have to be reconsidered, especially when compared to available “low-tech” solutions. Still recent experiments, involving directed evolution and genetic-engineering, into the airborne transmission of the deadly bird-flu virus H5N1 in ferrets (a model to study influenza transmission in humans) have revigorated debates about conditions for publication of biosecurity-sensitive data.
- As regards the other threat that is more specifically linked to the onset of synthetic biology, it may become more difficult, or even impossible, to assess the risks of extensively genetically modified or (putative) entirely “synthetic” future organisms, based on similarities with donor and recipient organisms. This issue may become more significant as the areas of synthetic biology progress and it remains to be seen whether synthetic biology-derived containment strategies (including xenobiotic mechanisms) can contribute to solve biosafety issues in future. Risk assessment may thus need to shift from prediction-based assessment to (more) real testing.
__
Synthetic biology presents a set of risks that raise both ethical and security questions. Work in synbio is increasingly cheap and easy to practice outside the area of trained biologists thus posing the problem of lack of ethics and safety standards. However, even the existing standards, such as those developed in the US and other countries, are now more than a decade-old. This concern adds to environmental worries about the likelihood of synthetic microorganisms escaping research facilities and proliferating out of control, threatening public health. Tests in open environments could also easily disrupt ecosystems or ultimately lead to the extinction of some species. While some see synthetic biology as a ray of hope for many of the world`s challenges in health, energy or environment, to some its scope is overshadowed by the numerous pathogenic risks and hazardous spill-overs that it can cause. The hazards that sceptics caution against also include deliberate misuse or abuse by states, outlawed groups or terrorists who could use synthetic biology for bio-hacking. Just like with computer viruses, “lone operators” or groups could work to develop pathogens or viruses, a threat that many forecast to become more pressing in the next decade. The dangers associated with synthetic biology are in many ways no different than those prompted by biotechnology in general or genetic engineering but synthetic biology is quantitatively different in that it offers far more possibilities to manipulate biology.
_______
Societal Risk Evaluation Scheme (SRES):
One model for assessing risks of new synthetic biology technologies is called Societal Risk Evaluation Scheme (SRES) and it tries to make governance more anticipatory than just reactive. This is a tough problem. How do we predict the risks of technologies that don’t exist yet? How do we assess products that seem totally new? The field of synthetic biology is pushing the boundaries of what we can do with and to biology.
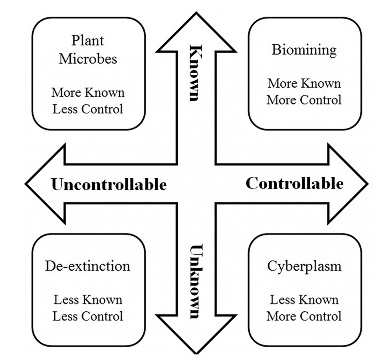
_
For the SRES, the experts evaluated information for eight categories:
- Human health risks;
- Environmental health risks;
- Unmanageability;
- Irreversibility;
- The likelihood that a technology will enter the marketplace;
- Lack of human health benefits;
- Lack of environmental benefits; and
- Anticipated level of public concern.
___
In the light of recent developments in synthetic biology community, a framework for risk research that addresses four public safety issues has been proposed by the Woodrow Wilson Synthetic Biology Project:
- How might synthetic organisms interact with natural ones?
- How well will they survive in receiving environments?
- How might they evolve and adapt to fill new ecological niches?
- What is the potential for gene transfer into unmodified organisms?
The synthetic biology community was invited to address these questions through designing, building, and testing new synthetic systems. The knowledge gained from the tests will help to close the existing knowledge gaps and contribute to the understanding of the biology behind synthetic higher plants and strengthen risk assessment processes. Adverse effects can result from unintended exposure to toxins or pathogens originating from synthetic plants. Infectious diseases can be considered resulting from accidental transmission of disease agents manipulated for the development of synthetic organisms. If the reproduction of such synthetic organisms is not limited, risks of transmission can increase and may spread to wider human community or the environment (Colussi 2013). A proper evaluation of the reproduction system of a synthetic plant therefore is a very important issue for the risk assessment.
Additionally, the careless use and implementation of pathogenic DNA sequences has to be avoided. Requirements need to be established for the performance of routine screenings for pathogenicity before development and assembling of synthetic DNA constructs (Hatch 2010). The commercialisation of a synthetic higher plant poses certain risks, one of which is the risk of increasing the probability of development of exotic plant species. In this context, it is pointed out that the accidental release of synthetic organisms is difficult to control, and also that hazards occur when these organisms replicate in the environment (Colussi 2013). Another risk is that a genetic exchange between synthetic organisms (biological entities) and natural organisms may occur. Such an exchange, called “genome contamination”, could affect human health, and also biological ecosystems influencing mutation and evolution.
_______
_______
Physical harms of synthetic biology: biosafety and biosecurity:
Physical harms are those which threaten the actual safety and security of humans or the environment. Two such harms that have been discussed at length in SynBio are biosafety and biosecurity. The risks created by the development of synthetic biology are of two types: biosafety, in which adverse consequences are the result of accidental or unforeseen events; and biosecurity in which the insights of synthetic biology are used with malign intent – in weapons, for example.
_
Biosafety:
Biosafety considers the potential negative effects of synthetic or artificial organisms on the environment or human beings, say for example if a synthetic entity were to be released beyond the laboratory and interact with or alter the environment in an unexpected way. Many areas of biological research create concerns about safety, but synthetic biology does pose some particular threats. It takes little imagination to appreciate that an entirely novel self-replicating organism that escaped the laboratory and entered the environment could cause all sorts of harm, depending on the properties and activities with which its designers had endowed it. While novel or highly modified organisms are unlikely to survive in an environment outside the laboratory or could be engineered to ensure this is not possible (Garfinkel et al, 2008), there may also be situations where there will be a need for trade-offs between benefits and risks. One method of minimising the likelihood of unforeseen consequences would be to create organisms that could survive only by relying on nutrients or other essential materials that are not found in nature. However, even this is not a foolproof recipe because many microbes have the capacity to transfer genes “horizontally”: to swap bits of genetic information with others of their own kind, and even with the members of other species. Moreover, a novel self-replicating microbe would presumably have the capacity to evolve, and might develop dangerous properties. Any synthetic organism would need to be handled with the highest safety standards – adapted, perhaps, from those already devised for handling genetically manipulated organisms – and subject to close regulation at national and European level. A further complication is that the release of a synthetic organism would not necessarily be accidental. To perform its task, a novel microbe engineered to clean up some form of environmental pollution would have to be released freely into that environment. Scientists contemplating any such action would have to set an exceptionally high threshold of certainty that the organism would be unlikely to trigger events which had not been contemplated. Yet biosafety does not solely concern the substantive issues of safety or containment, which to some extent are a matter of careful oversight and responsible scientific practice. Debates over biosafety also include determining what is ‘safe’ in SynBio (Garfinkel et al, 2008) and who should determine this. While there is general agreement that rigorous standards are required, there is less agreement on what these should be.
_
Biosecurity:
Biosecurity issues arise over the possible uses of the products of SynBio by those who wish to commit harmful acts such as bioterrorism (Bugl et al, 2007). This concern has been more widely discussed in North America than Europe, perhaps because the USA has already seen a successful biological attack. Much of the concern with biosecurity arises from the relative ease of obtaining materials necessary for baseline SynBio research outside of the more regulated environment of a university or research institute. Examples such as the synthesis of the virus that led to the 1918 influenza pandemic and the polio virus by way of procuring DNA sequences online from commercial providers, although undertaken by responsible scientists, illustrate that an individual with mal-intent or a nefarious state may be able to inflict harm to many. It also gives rise to concerns about ‘dual use’ problems in emerging technologies; by which the same application of SynBio could give rise to both beneficial and harmful consequences. There is some industrial self-oversight over sequencing orders, but there are concerns about whether, when or how other forms of monitoring should take place. Good regulation, though essential, can offer only limited protection against would-be bioterrorists who might be interested in synthetic biology as a weapon.
_
Effectively addressing biosecurity involves education, awareness, regulation, and oversight.
- Technical and regulatory checkpoints. DNA synthesis companies will need to check and screen orders to avoid the production of select agents, such as harmful viruses and bacterial DNA, as well as further develop and improve the technical means (e.g., software and databases) used to screen DNA orders.
- Awareness. While biosecurity awareness among European DNA synthesis companies is relatively high, among most practicing life scientists it is comparatively low. Awareness needs to be enhanced through better communication and cooperation between the synthetic biology and biosecurity communities.
- Education. Contemporary issues—such as past misuse of the life sciences for offensive bioweapon programs, the inadvertent results of security-related research, and the existence and operation of the Biological Weapons Convention—should be systematically included in undergraduate and graduate biology curricula.
- Governance and oversight. Addressing questions of governance and oversight of biosecurity will require more, and different, regulatory tools than are used when dealing with other societal issues. The involvement of all stakeholders is required to develop useful tools and avoid an oversight system with overly severe restrictions.
_
One further issue which overlaps with biosecurity and biosafety as physical harms is that of professional ethics within SynBio. Given that SynBio research involves professionals from a range of scientific disciplines working together for the first time, they may come together with different codes of conduct or expectations as to what constitutes responsible research. While it is important to recognise that researchers already appreciate the possible implications of their field, monitoring professional integrity may become a more pressing problem as the field advances.
__
Emergence of novel properties:
The application of synthetic biology techniques for the construction of new metabolic pathways and regulatory circuits will lead to radically different forms of life in the long run. These novel organisms may develop unpredictable new properties. It is disconcerting that the interaction of novel circuits with endogenous pathways and the interaction with changing environmental conditions is only rudimentary understood (Pauwels et al. 2013). There is only limited knowledge available which allows the forward engineering of genetic devices containing a maximum of 20 genes or biological parts at best (Schmidt and de Lorenzo 2012). Trial and error will be a long-term companion of synthetic biology and unexpected traits will almost certainly arise (Schmidt and de Lorenzo 2012). That unforeseen results may pose a serious health hazard is exemplified by the production of a new mouse pox virus which intentionally should induce infertility but killed not only all of the exposed native mice but also 50% of a vaccinated – and hence supposedly immune – control group (Schmidt and de Lorenzo 2012; Jackson et al. 2001). This observation implies that there are clear limits of predictive knowledge (Garrett 2011). The situation will deteriorate considering the combination of more and more elements from multiple and diverse sources of DNA (Fleming 2006). It is important to note that at present no one comprehensively understands which risks completely synthetic organisms will pose to humans, animals and the environment, what information is needed to assess these kinds of risks and who should be responsible for collecting the necessary data (Dana et al. 2012).
_
Bioterrorism:
The ability of synthetic biology to produce known, modified or new microorganisms designed to be hostile to humans is a major concern, and has been demonstrated by the synthesis of the polio virus and the pandemic Spanish Flu virus of 1918. A major issue in this respect is the ready availability and poor control over commercial DNA synthesis. Furthermore, in the future ‘garage biology’ (synthetic biology at home) may be established as a hobby. However, most concern arises from state-level biological warfare programmes. A number of proposals have been made by both scientific groups and government agencies to address the dual use (military/civilian) nature of synthetic genomics, including: controls over commercial DNA synthesis and public research; and considering the impact of synthetic biology on international bioweapons conventions. As yet there is no policy consensus on these issues. Furthermore, there is an ongoing debate about whether improved biosecurity measures should be achieved through professional self-regulation or formal statutory oversight.
_
Patenting and the Creation of Monopolies:
The drive to create a microorganism that can turn biomass into fuels such as ethanol or hydrogen is a major focus of research, which has prompted a concern that patenting may lead to the creation of commercial monopolies or inhibit basic research. In response, there have been moves to develop an open-source movement (based on so called BioBricks) involving creation of a ‘commons’ that will facilitate open scientific research.
_
Trade and Global Justice:
Perhaps the biggest success in synthetic biology to date has been in the production of terpenoids for the manufacture of the antimalarial medicine artemisinin, a drug that holds significant promise for worldwide malaria victims. However, there are concerns that synthetic artemisinin would ensure that no local production of natural Artemisia could be sustained in developing countries, thereby maintaining the discrepancy of wealth and health between rich and poor nations.
_
Creating Artificial Life:
One of the most potent promises of synthetic biology is the creation of ‘artificial life’. This has provoked fears about scientists ‘playing God’ and raises philosophical and religious concerns about the nature of life and the process of creation. It has been suggested that a stable definition of ‘life’ is impossible and that synthetic biologists are confused over what life is, where it begins and particularly, how complex it must be. In response a number of scientists have proposed a modified version of Turing’s test for life imitation. However, it is unclear whether these moves to undermine lay concepts of life will ameliorate deeper fears about the blurring of the boundary between the artificial and the natural world.
____
____
Synthetic Biology and Occupational Risk:
Forty two years ago, in February 1975, the Asilomar Conference on Recombinant DNA established guiding principles for safe conduct of experiments utilizing recombinant DNA technology, which facilitated the creation of a biotechnology industry in the 1980s. Synthetic biology promises tremendous societal benefits in treating human genetic disease. At the same time, synthetic biology has raised concerns about potential biosafety risks to workers and to society in general. Examples of existing regulatory standards applicable to biotechnology laboratory workers include standards for bloodborne pathogens; toxic and hazardous substances; access to employee exposure and medical records; hazard communication; exposure to toxic chemicals in laboratories; respiratory protection; and safety standards of a general nature. A recently published paper describes additional steps that could be taken to ensure the safety of workers in the synthetic biology workplace. It calls for (1) enhanced risk governance strategies including health surveillance, (2) proactive risk assessment involving the larger occupational safety and health practice community beyond biosafety research professionals, (3) the application of prevention-through-design principles to new methods of intrinsic and extrinsic biocontainment and a formal study of their effectiveness, (4) specific safety guidance for synthetic biology processes used in advanced manufacturing in the new bioeconomy, (5) attention by occupational medicine professionals to viral vector post-exposure, and (6) greater involvement by U.S. national occupational safety and health research and regulatory agencies in ensuring safe approaches to the development of synthetic biotechnology. The use of synthetic biology in advanced manufacturing requires that occupational safety and health practitioners not currently involved in biosafety research must be educated about risks to workers associated with synthetic biology.
_
Real-world Example:
An illustrative example of risks to workers in the synthetic biology workplace is application of viral vectors for gene therapy in research laboratories and health care settings. Some of the most widely used viral vectors for gene therapy are lentiviral vectors (LVVs). Unintentional exposure of workers to LVVs can result in the transduction of “off-target” cell types, generation of replication-competent lentivirus, and for insertional mutagenesis and the transactivation of neighboring genome sequences which could lead to cancer and other diseases in workers. In order to reduce occupational risks of LVVs, Schlimgen et al. proposed a three-pronged approach. First, Institutional Biosafety Committees should provide the support, guidance and training to principal investigators about potential risks and benefits of treating clinically relevant exposure incidents. Second, occupational health providers and laboratory personnel should weigh risks to determine individual’s preference for post- exposure prophylaxis. Third, information about LVV-exposed individuals should be collected to evaluate the long-term risks associated with lentiviruses.
_____
_____
Is Synthetic Biology genetic engineering by another name to circumvent the public scepticism surrounding GMOs?
Proponents of genetic engineering are keen to circumvent the public scepticism surrounding GMOs. They want to avoid the term GM in relation to gene- and genome-editing techniques in particular, hoping that such modified organisms will be excluded from GMO regulation. Clearly, this would be completely inappropriate, since these resulting GMOs would then not be subject to risk assessment, detectability and labelling rules. It would mean giving up the scientific safeguards of the precautionary principle and exposing citizens and the environment to unpredictable risks. Genetic engineering, whether it’s called GM, Synbio or NBTs, involves the application of an engineering mindset to the natural world. It means that living things are seen as composed of parts that may be disassembled and reassembled in an ‘improved’ or novel form. Living organisms are being re-imagined as data and software platforms. They may be added to or removed from an ecosystem, be reshaped or reprogrammed – without taking into account what impacts such changes have on the whole system. Proponents claim that GMOs, including the new techniques, are essential to help feed a growing global population, develop plants that can withstand climate change and replace fossil fuels with better alternatives. However, what would be the consequences of such approaches? Moreover, none of these promises have so far been fulfilled in over 20 years of GMO crop research and development. Proponents respond that we (society) need to reduce or remove regulation and increase the speed of application. The problems predicted by GMO critics, on the other hand, have to a large extent materialised. These include the contamination of non-GM crops; the emergence of pesticide-resistant pests and secondary pests (in response to pesticide-producing GM crops), requiring ever more pesticides; and the development of herbicide-tolerant persistent weeds, sometimes in invasive proportions (in response to herbicide-tolerant GM crops). These have all had negative impacts on farmers and communities, including serious health impacts from the multiple spraying of toxins (herbicides and pesticides). Our ability to make ever greater changes to the genetic makeup of living organisms should not blind us to the reality: our incomplete knowledge of these organisms and their interactions, and the dangers involved in trying to adjust nature to our needs and ‘improve’ it by engineering it. This is why the first step should be to use clear and applicable language rather than misleading terminology. In fact synthetic biology and NBTs carry similar risks to old-style GE, and even create novel hazards. Synthetic biology products deserve regulation at least as strict as those applying to GMOs. All synthetically created foods or edible organisms must go through the same regulations all other genetically modified organisms already are subjected to.
_______
_______
Knowledge will tell synbio consequences:
Our concern with gene editing, then, is not that it shouldn’t be done, but that it shouldn’t be done until we have adequate knowledge of the consequences. What’s going to make the difference? The difference will be when we attain more complete knowledge, which we just simply don’t have. Let’s take the example of the fruit fly. If it has a defect in its wing, we can find out today what structural protein has caused that defect and fix it. But it turns out that same gene that leads to that protein structure early on totally controls key development of the body as well as the wing. Only in its final stage does it become a structural protein. So if we intervened and thought we were just fixing the wing, we could be deforming the whole body of the fly.
_____
_____
Bioethics in synthetic biology:
Synthetic biology holds out the prospect of significant benefits to humanity. However, it also raises some important concerns. These include, for example, concerns about laboratory biosafety, the aggravation of injustices and challenges that the discipline may pose to existing systems of intellectual property rights etc. However, there are two concerns that are likely to garner most attention from bioethicists: (1) concerns about ‘playing God’, which have been prominent in closely related areas of science; (2) concerns about undermining the distinction between living things and machines, which attracted early attention from ethicists.
_
- Playing God:
Concerns about humans playing God can be understood in at least two different ways. On a religious interpretation, the concern is that humans are literally usurping the role of some higher being or god. This worry is often raised about attempts to alter natural genomes, so it would be surprising if it were not raised about attempts to design entirely new genomes. On secular interpretations, the concern is typically with humans failing to recognise their own limitations, for example, by overestimating their ability to control complex ecosystems. Again, we can imagine the same charge being made against synthetic biologists. Though concerns about playing God are not new with synthetic biology, the discipline may allow us to play God in qualitatively different ways. Humans have long been able to exert some influence on the genetic make-up of future beings through selective breeding; however we were constrained to working within the timescales and genetic possibilities dictated by evolution. Genetic engineering partially freed us from this constraint. Synthetic biology promises to free us from a further constraint: the need for a natural template on which future organisms must be based. It will allow us to design and create life, not merely to tinker with or modify it. There is another important respect in which synthetic biology differs from earlier enterprises deemed to involve playing God: it will enable us to create life from non-living, inorganic matter. Indeed, this is arguably the most distinctive role of synthetic biology, and it is a role that might well be assigned to God (or thought to require particular sensitivity to human limitations). The advent of synthetic biology could thus be viewed as a significant leap towards usurping the functions of God (or overstepping human limitations). It might therefore be argued that there is a need for specific ethical analyses of playing God concerns as applied to synthetic biology. _
- Organisms or machines?
A unique ethical concern about synthetic biology is that it may result in the creation of entities which fall somewhere between living things and machines. It is not difficult to see why some products of synthetic biology might fail to fit comfortably into our intuitive dichotomy between the living and the non-living. Consider, for example, the bacterial bio-factories that synthetic biologists hope to construct by adding suitable modules to a minimal bacterial chassis. These bio-factories might possess many of the characteristics that we ordinarily take to be definitive of life: for example, homeostatic physiological mechanisms, a nucleic acid genome and protein-based structure, and the ability to reproduce. But they would also possess many of the features characteristic of machines: for example, modular construction, based on rational design principles, and with specific applications in mind. Alternatively, consider the more remote but not entirely fantastic possibility of a synthetic bio-computer which performs many of the tasks currently performed by PCs, but which is based not on the silicone chip, but on neural networks composed of synthetic human nerve cells. Entities such as these certainly test our intuitive dichotomy between the living and the non-living in ways that it has hitherto not been challenged. The concern here appears to be that we will cease to regard the distinction between living things and machines as important. But—the argument would go—this distinction is important, for machines and living things differ significantly in their moral status. Machines, such as computers, have no intrinsic value (they are valuable only insofar they can be used to bring about valuable ends), no interests and no rights. Organisms, on the other hand, may possess all of these things. Thus, if the significance attached to the distinction between living things and machines were eroded, we might wrongly come to see living things as possessing less moral status than they actually have. This argument seems to overblow the significance of life, however. There are many living things (bacteria, for example) to which we already ascribe no moral status. We feel quite justified in killing or exploiting bacteria whenever it suits us. We certainly do not think that in doing so we a breaching their rights, obstructing their interests, or denying their intrinsic value: bacteria possess none of these things. This is because moral status is conferred not by life, but by characteristics that some living things possess (sentience, consciousness, self-consciousness and rationality are among the most obvious candidates). Synthetic biology may highlight the need for more secure accounts of what determines moral status than we currently have. However, the ethical work necessary to develop such accounts is already underway. Ethical controversies about abortion, stem cell research, human-nonhuman chimeras, artificial intelligence and the treatment of animals have ensured that questions about moral status enjoy a high priority on the bioethics agenda. So the need for specific attention to the moral status issues raised by synthetic biology is limited.
______
______
Mitigating the Risks:
- Biological containment:
The first step in mitigation potential risks by SB organisms is to impose physical barriers which should help to prevent accidental release into the environment (Schmidt and de Lorenzo 2012). As physical containment might not suffice, biological containment is proposed as a solution to its drawbacks (Wright et al. 2013; Marliere 2009). For biological containment the following lines of research are proposed and pursued:
(a) Induced lethality: “kill switches”, “suicide genes”:
This approach is prone to mutations reverting the targeted phenotype by deactivation of the lethal gene (Schmidt and de Lorenzo 2012). Due to the high rate of evolution of microorganisms this strategy is expected to be unreliable (Wright et al. 2013).
(b) Prevention of horizontal gene transfer:
The application of phage-resistant strains or of plasmids lacking proper transfer sequences is proposed (Skerker et al. 2009). However, the prevention of uptake of free DNA by natural transformation of competent microorganisms will be challenging (Wright et al. 2013).
(c) Trophic containment:
Auxotrophic SB microorganisms relying on nutrients only present in in vitro settings may be designed (Marliere 2009). Accidental release into the environment would lead to cell death due to starvation. This approach suffers from several drawbacks as the necessary nutrients might well be present in the environment or the auxotrophic mutant may use metabolites from neighbouring organisms or horizontal gene transfer might compensate for the auxotrophic mutations (Moe-Behrens et al. 2013; Wright et al. 2013).
(d) Semantic containment: Xenobiology:
The application of altered nucleotides and/or alternate backbones other than phospho-ribose and deoxyribose which would lead to incompatibilities with naturally occurring polymerases, and a confinement of the SB organism from the living environment appears to be promising (Schmidt 2010b; Marliere 2009). However, unnatural nucleotides and alternative backbones in nucleic acids may be toxic to conventional cells (Moe-Behrens et al. 2013).
_
- Screening of oligonucleotide orders:
At present, it is possible to place orders for oligonucleotides and genes over the Internet to custom supply houses, which synthesize any DNA sequence upon request and keep the transaction confidential. Oligonucleotide producers have emerged in several countries around the world, including nations such as China and Iran. A U.S. gene-synthesis company, Blue Heron Biotechnology, voluntarily uses special software to screen all oligonucleotide and gene orders for the presence of DNA sequences from “select agents” of bioterrorism concern. When such a sequence is detected, the request is denied, although there is currently no procedure for reporting such incidents to U.S. government authorities. Nevertheless, suppliers are currently under no legal obligation to screen their orders, and because many clients value confidentiality, companies might put themselves at a competitive disadvantage by doing so. There are two possible solutions to this problem. First, Congress could pass a law requiring U.S. suppliers to screen all oligonucleotide and gene orders for pathogenic DNA sequences. Alternatively, suppliers could agree among themselves to screen orders voluntarily, or legitimate researchers could choose to patronize only those companies that do so. Because the trade involves several countries, however, an effective regulatory regime would have to be international in scope.
_
- Ecological modelling of synthetic microorganisms:
Given the difficulty of predicting the risks to public health and the environment posed by synthetic microorganisms, it will be essential to study the ecological behavior of such agents in enclosed microcosms or mesocosms that model as accurately as possible the ecosystem into which the organism will be released. Such studies should examine the extent to which the genetic material from a synthetic microorganism is transferred to other organisms or persists intact in the environment. In the event that the uncertainties associated with the liberation of synthetic microbes prove to be irreducible, it may be necessary to ban all uses in the open environment until a robust risk assessment can be conducted for each proposed application.
_
- Oversight of research:
Research in synthetic biology may generate “dual-use” findings that could enable proliferators or terrorists to develop biological warfare agents that are more lethal, easier to manufacture, or of greater military utility than today’s bioweapons. In rare cases, it may be necessary to halt a proposed research project at the funding stage or, if unexpectedly sensitive results emerge that could threaten public health or national security, to place constraints on publication. Relevant guidelines for the oversight of “dual-use” research are currently being developed by the U.S. government’s National Scientific Advisory Board for Biosecurity and should eventually be “harmonized” internationally.
_
- Public outreach and education:
Because of the potential for intense controversy surrounding synthetic biology, public outreach and education are needed even at this early stage in the field’s development. Although it is often difficult to persuade scientists to leave the laboratory for even a few hours to participate in a public discussion of their work and its implications for society, such efforts should be encouraged because they generate good will and may help to prevent a future political backlash that could cripple the emerging field of synthetic biology.
_
- European initiatives:
The European Union funded project SYNBIOSAFE has issued several reports on how to manage the risks of synthetic biology. A 2007 paper identified key issues in safety, security, ethics and the science-society interface, which the project defined as public education and ongoing dialogue among scientists, businesses, government, and ethicists). The key security issues that SYNBIOSAFE identified involved engaging companies that sell synthetic DNA and the Biohacking community of amateur biologists. Key ethical issues concerned the creation of new life forms. A subsequent report focused on biosecurity, especially the so-called dual-use challenge. For example, while synthetic biology may lead to more efficient production of medical treatments, for malaria for example, it may also lead to synthesis or redesign of harmful pathogens (e.g., smallpox). The bio-hacking community remains a source of special concern, as the distributed and diffuse nature of open-source biotechnology makes it difficult to track, regulate, or mitigate potential concerns over biosafety and biosecurity. COSY, another European initiative, focuses on public perception and communication of synthetic biology. To better communicate synthetic biology and its societal ramifications to a broader public, COSY and SYNBIOSAFE published a 38-minute documentary film in October 2009. The International Association Synthetic Biology has proposed an initiative for self-regulation. This suggests specific measures that the synthetic biology industry, especially DNA synthesis companies, should implement. In 2007, a group led by scientists from leading DNA-synthesis companies published a “practical plan for developing an effective oversight framework for the DNA-synthesis industry.”
_
- American initiatives:
In January 2009, the Alfred P. Sloan Foundation funded the Woodrow Wilson Center, the Hastings Center, and the J. Craig Venter Institute to examine the public perception, ethics, and policy implications of synthetic biology. On July 9–10, 2009, the National Academies’ Committee of Science, Technology & Law convened a symposium on “Opportunities and Challenges in the Emerging Field of Synthetic Biology”. After the publication of the first synthetic genome by Craig Venter’s group and the accompanying media coverage about “life” being created, President Obama requested the Presidential Commission for the Study of Bioethical Issues to study synthetic biology. The commission convened a series of meetings, then issued a report in December 2010 titled “New Directions: The Ethics of Synthetic Biology and Emerging Technologies.” The commission clarified that the “while Venter’s achievement marked a significant technical advance in demonstrating that a relatively large genome could be accurately synthesized and substituted for another, it did not amount to the “creation of life”. It also noted that synthetic biology is an emerging field, which creates potential risks and rewards. The commission did not recommend any changes to policy or oversight and called for continued funding of the research and new funding for monitoring, study of emerging ethical issues, and public education. Synthetic biology, being a major tool for biological advances, results in the “potential for developing biological weapons, possible unforeseen negative impacts on human health . . . and any potential environmental impact.” These security issues may be avoided by regulating industry uses of biotechnology through policy legislation. Federal guidelines on genetic manipulation are being proposed by “the President’s Bioethics Commission . . . in response to the announced creation of a self-replicating cell from a chemically synthesized genome, put forward 18 recommendations not only for regulating the science . . . for educating the public.”
______
______
Public awareness of synthetic biology:
In the coming decades, synthetic biology may have a substantial impact on the world we live in. Given the scope of what synthetic biologists are trying to achieve, it is reasonable to start an early discourse about the technology, its applications, and the way we deal with it and its products. Few people outside the scientific community have heard of the field, but several projects have started to initiate a proactive discussion between science and society. To achieve the goal of making people aware of the many aspects and potential ramifications of synthetic biology, scientists and researchers must insist on the following:
- Education. Topics related to synthetic biology, such as safety, security, and ethical issues, should be incorporated into the teaching curricula of synthetic biologists from the start of their education.
- Public engagement. As synthetic biology develops into applied technologies, it is important that scientists, stakeholders, and the public communicate in an interactive way. Past debates on genetic engineering suggest that, in order to prevent exaggerated hopes and fears, scientists should adopt an open approach toward the public. Both stakeholders and scientists should engage with members of the public in ethical discussions that go beyond mere campaigning or conveying information. In addition, different preferences and world-views associated with technology and innovation need to be addressed and not dismissed as unscientific.
- Stakeholder involvement. Since developments in synthetic biology are so rapid, and regulation alone is no guarantee against misuse or societal controversies, it is necessary to involve relevant stakeholders in the decision-making process. This will allow for flexible and relatively swift ways of dealing with future problems through a combination of regulations, agreements, codes of conduct, and similar measures. This also requires a distribution of responsibilities. A multi-stakeholder approach for the governance of synthetic biology and its applications should involve scientists, regulators, members of civil society, industry representatives, philosophers, and other relevant groups.
________
________
Advancement in synthetic biology:
______
Synthetic biology turns living cell into bio-computer: 2017 study:
The human body is made up of trillions of cells, microscopic computers that carry out complex behaviors according to the signals they receive from each other and their environment. Synthetic biologists engineer living cells to control how they behave by converting their genes into programmable circuits. Genes can be thought of like an input/output system that already does some simple logic. The inputs are molecules that interact with genes to help turn them on or off. The outputs are what the gene makes after it’s turned on — usually a protein of some sort. For example, the gene for the enzyme that digests lactose naturally turns on whenever there’s lactose around, but not glucose.
Biological Boolean:
Scientists have come up with clever ways to manipulate, combine, and tweak these stretches of DNA to do some pretty interesting things. In 2012, Swiss researchers showed that they could get mammalian cells to do math. They created genes that only turn on if two particular inputs are there at the same time — so that the genes essentially compute an “AND” function. And they made others that compute other functions. By combining basic logical functions — “AND,” “OR,” “NOT,” and combinations of them — they got cells to do binary addition and subtraction like computers do and then show the right answer by glowing red or green. Others have done projects that also involved memory. Researchers at MIT have transformed bacterial cells into artificial, living calculators that can do divisions, square roots and logarithms. In another example, a team from the University of California at San Francisco created a plate of E. coli bacteria that can sense and then trace out an edge of a picture. It’s a demonstration of simple logic that could someday get built up into far more complex code. The logic they programmed is as follows: (1) If you sense light, make a certain cell signalling molecule. (2) If you’re sensing the signalling molecule (meaning you’re near a cell that’s in the light) and are not yourself sensing light, then manufacture a dark pigment.
BLADE in action:
The researchers have dubbed a new tool with a catchy name, BLADE, which stands for “Boolean logic and arithmetic through DNA excision.” But BLADE isn’t just a novelty tool only good at Boolean logic. What it offers is a way to design large-scale biological circuits, so that scientists can reliably control the actions of a cell. With BLADE, scientists could design complex if-then systems into stem cells, where one set of “if” conditions pushes the cell towards one fate (say, a neuron), while others trigger it to turn into insulin-producing beta cells. BLADE can also give cancer therapy a boost. Scientists are already engineering immune cells that can detect cancer biomarkers and specifically target cancer cells. Programming additional biocircuits into these cells could give them even more sophistication and control: for example, AND gates would limit the immune cells to only spring into action when they detect multiple cancer markers, further lowering casualties and side effects. Future projects may result in synthetic organisms that clean up environmental pollution, trap carbon, produce vaccines and medications, fabricate food, perform photosynthesis, terra-form other planets, store large amounts of information or manufacture renewable fuel out of methane and carbon dioxide.
____
____
Engineering multiple cells:
The concept of engineering multiple cells to work in unison is still in its early stages and it is metaphorically very much like the design of early computers and computer coding. In the early days of computing, proof of concept was to tackle the initial questions of, ‘Can we make a system that can reliably and repeatably perform on/off (I/O) logic? How do we do that? Researchers at Rice University in Houston, Texas have created two populations of Escherechia coli (E. Coli); one which produced a type of activator signalling molecule (a molecule that triggers action), and another group which produced a corollary type of suppressor signalling molecule (one that counteracts the first). These two molecule types would be the biological analogs of (I/O) in a computer. When put together, the two groups of E. coli would perform a relatively complex exchange where the ‘activators’ would trigger the ‘suppressors’ to produce their protein, which would then turn off the activator molecules. Representing the next step in the evolution of the concept, the team also bio-engineered the E. coli to fluoresce in a way that was dependent upon the strength of the cell signalling. This research was published in Science; in it the team found that “the two strains generated emergent, population-level oscillations only when cultured together.” This is a fascinating result, and gives measures of the level of communication occurring between the two E. coli strains. They also found a certain periodicity to the fluorescing oscillations, occurring in such a way that it would build up about every two hours, and then fade again. This could be an indication that something deeper is going on within the communicating populations of bacteria that the scientists aren’t aware of yet or measuring, or it could just be an artifact of the biological system itself and its internal limitations and processes. In humans there is periodicity associated with how pancreatic beta cells produce insulin, which may have as much to do with cellular communication as with the mechanics of the production and secretion of the hormone itself. Though these interactions could be used for an incredible diversity of applications, including signalling and monitoring for tissue or bone growth, hormone production and regulation, etc., the most frequently-mentioned use in industry discussions is around disease modification.
_
Engineering microbial consortia: a new frontier in synthetic biology:
Microbial consortia are ubiquitous in nature and are implicated in processes of great importance to humans, from environmental remediation and wastewater treatment to assistance in food digestion. Synthetic biologists are honing their ability to program the behavior of individual microbial populations, forcing the microbes to focus on specific applications, such as the production of drugs and fuels. Given that microbial consortia can perform even more complicated tasks and endure more changeable environments than monocultures can, they represent an important new frontier for synthetic biology. Interest has recently emerged in engineering microbial consortia – multiple interacting microbial populations – because consortia can perform complicated functions that individual populations cannot and because consortia can be more robust to environmental fluctuations. These attractive traits rely on two organizing features. First, members of the consortium communicate with one another. Whether by trading metabolites or by exchanging dedicated molecular signals, each population or individual detects and responds to the presence of others in the consortium. This communication enables the second important feature, which is the division of labor; the overall output of the consortium rests on a combination of tasks performed by constituent individuals or sub-populations. Because members of microbial consortia communicate and differentiate, consortia can perform more complex tasks and can survive in more changeable environments than can uniform populations. Simple engineered consortia might be described through mathematical models more easily than natural systems are, and they can be used to develop and validate models of more complex systems. Furthermore, their behavior can be controlled by externally introduced signals (e.g. circuits can be induced by small molecules such as IPTG). To date, engineers have successfully constructed microbial consortia by implementing cell–cell communication and differentiation of function in traditional, laboratory microbes. To fully exploit the potential of engineered consortia, we must learn to stably engineer organisms that are currently recalcitrant to genetic manipulation. Furthermore, when engineering new technologies, we should prioritize safety by beginning with innocuous or commensal organisms. As a result of engineered communication and differentiation of function, engineered consortia do exhibit complex functions that can be difficult to engineer into single populations. If they are to be used in future technologies, engineered consortia will need to be tested and optimized for their ability to persist and withstand environmental fluctuations. In addition to ‘pushing the envelope’ of synthetic biology, with promising health, environmental, and industrial applications, engineered microbial consortia are potentially powerful and versatile tools for studying microbial interactions and evolution.
_____
_____
Analog synthetic biology:
Every living cell within us is a hybrid analog–digital supercomputer that implements highly computationally intensive nonlinear, stochastic, differential equations with 30,000 gene–protein state variables that interact via complex feedback loops. The average 10 μm human cell performs these amazing computations with 0.34 nm self-aligned nanoscale DNA–protein devices, with 20 kT per molecular operation (1 ATP molecule hydrolysed), approximately 0.8 pW of power consumption (10 M ATP s−1) and with noisy, unreliable devices that collectively interact to perform reliable hybrid analog–digital computation. Based on a single amino acid among thousands of proteins, immune cells must collectively decide whether a given molecule or molecular fragment is from a friend or foe, and if they err in their decision by even a tiny amount, autoimmune disease, infectious disease, or cancer could originate with high probability every day. Even at the end of Moore’s law, we will not match such performance by even a few orders of magnitude.
_
The field of synthetic biology attempts to transfer engineering design principles and experimental techniques into rational biological design. It represents the ultimate limit of Moore’s law: computation with the molecules themselves at the nanoscale through the use of controlled biochemistry and biophysics. Such an approach can blend ‘fabrication’ and ‘computation’ in a seamless fashion. The self-organizing amorphous soup in a cell processes information while it destroys, repairs and rebuilds the structures needed to do so. It is remarkable that it does so through a self-aligned nanotechnology with no explicit wiring. Instead, chemical binding among specific molecules serves to ‘implicitly wire’ them together and causes them to interact via chemical reactions. These reactions cause transformations of state, which are necessary for computation to occur.
_
While significant progress has been made w.r.t. fundamentals and applications in the field of synthetic biology, it has failed to scale significantly in complexity over more than a decade. One important reason for this failure has been its overemphasis on digital paradigms of thought: because digital design is relatively straightforward and scalable, and because molecules and atoms are discrete, it is logical to assume that engineering biology as we engineer switches and logic gates today will bear fruit. The sheer force and powerful success of digital computation over the past few decades has been impressive. Nevertheless, we must not forget that digital computation has not offered an effective paradigm for computing efficiently and precisely with noisy and unreliable devices; that multi-logic-gate computations can impose significant metabolic or toxicity burdens on cells owing to their need to use a lot of parts and power; that the fact that there are five to six orders of magnitude fewer genes per cell than digital transistors per chip means that using genes to only perform logic is likely not an efficient way to attain high complexity; that a library of ‘digital parts’ with good on–off ratios, low standby power consumption and low crosstalk does not exist in biology; that the computing basis functions in cells are not really logic functions and abstracting them as such compromises computational efficiency; and that logic basis functions are not the only universal computation primitives.
_
Nature is not purely digital but in fact significantly analog. While molecules are discrete and digital, all molecular interactions that lead to computation, e.g. association, transformation and dissociation chemical reactions, have a probabilistic analog nature to them. Depending on one’s point of view, computation in a cell is owing to lots of probabilistic digital events or owing to continuous analog computation with noise. Both views are equivalent. Indeed, the noise in analog systems is related to the Poisson rate of the underlying probabilistic digital events; the shot noise of thermally generated diffusion currents caused by these Poisson processes generates noise in all analog systems.
_
Synthetic biology has now recognized that the signals in cells are stochastic (noisy) and analog (graded) in their nature. The ‘1’s and ‘0’s of today’s digital computers are useful abstractions of the analog signals in cells, but are often an oversimplification. Furthermore, as in analog circuits, the wiring of the output of one circuit to the input of another leads to ‘loading’ interactions that degrade overall function and prevents simple modular digital abstractions from being effective. While logic basis functions and positive-feedback loops are certainly used by cells to make irreversible decisions, to organize sequential computation and to perform signal restoration, analog computation is extremely important for the cell’s incredible efficiency w.r.t. the use of energy, time and space. The efficiency arises because analog computation can use powerful input–output basis functions in the technology for addition, multiplication, exponentials, logarithms, power laws and spatio-temporal filtering, which are already naturally present in the differential equations of physics and chemistry. Therefore, it does not need to re-invent these input–output basis functions from scratch with logic. For example, the production fluxes of two genes that encode the synthesis of a common output protein automatically perform addition via a molecular version of Kirchoff’s current law without the need for tedious logic; the binding of two molecules provides a basis function for multiplication; the binding of identical molecules in a dimer provides basic functions for computing squares or square roots; molecular degradation naturally provides basic functions for temporal filtering; diffusion naturally provides a basis function for spatial filtering.
_
The pioneers of digital computation, John von Neumann and Alan Turing, appreciated the great power of analog computation and were investigating it intensely to cope with the limitations of using only logic to compute. Near the end of their lives, they were working on understanding analog computation in brains and in cells, respectively. Analog computation has long been appreciated to be important in the brain, but its importance in cells has been greatly underappreciated. The power of the analog wave function in quantum mechanics enables quantum computers to solve problems that no digital computer can.
_
A 2014 study of analog versus digital computation in living cells:
Authors analyse the pros and cons of analog versus digital computation in living cells. Their analysis is based on fundamental laws of noise in gene and protein expression, which set limits on the energy, time, space, molecular count and part-count resources needed to compute at a given level of precision. They conclude that analog computation is significantly more efficient in its use of resources than deterministic digital computation even at relatively high levels of precision in the cell. Based on this analysis, it is concluded that synthetic biology must use analog, collective analog, probabilistic and hybrid analog–digital computational approaches; otherwise, even relatively simple synthetic computations in cells such as addition will exceed energy and molecular-count budgets. Authors present schematics for efficiently representing analog DNA–protein computation in cells. Analog electronic flow in subthreshold transistors and analog molecular flux in chemical reactions obey Boltzmann exponential laws of thermodynamics and are described by astoundingly similar logarithmic electrochemical potentials. Therefore, cytomorphic circuits can help to map circuit designs between electronic and biochemical domains. Authors review recent work that uses positive-feedback linearization circuits to architect wide-dynamic-range logarithmic analog computation in Escherichia coli using three transcription factors, nearly two orders of magnitude more efficient in parts than prior digital implementations.
_____
_____
Synthetic biology (SB) and artificial intelligence (AI):
Traditionally Artificial Intelligence (AI) research, broadly conceived as the study of intelligence through the construction of artificial models of natural cognitive systems, has been developed in the context of computer science and robotics. Today the scientific and technical advancements of biological sciences, leading to the emergence of Synthetic Biology (SB) conceived as the chemical synthesis of biological parts/systems/processes, allow the scientific community to extend AI research within the field of experimental biology.
_
AI for Synthetic Biology:
I must draw the attention of the AI community to a novel and rich application domain, namely Synthetic Biology. Synthetic biology is the systematic design and engineering of biological systems. Synthetic organisms are currently designed at the DNA level, which limits the complexity of the systems. Synthetic Biology holds the potential for revolutionary advances in medicine, environmental remediation, and many more. For example, some synthetic biologists are trying to develop cellular programs that will identify and kill cancer cells, while others are trying to design plants that will extract harmful pollutants like arsenic from the ground. However, the field has reached a complexity barrier that AI researchers can help it overcome. The state-of-the-art techniques in synthetic biology require practitioners to design organisms at the DNA level. This low-level, manual process becomes unmanageable as the size of design grows. This is analogous to writing a computer program in assembly language, which also becomes difficult quickly as the size of the program grows. The time is ripe to gather researchers from synthetic biology and AI communities to cultivate a multi-disciplinary research community that can benefit both areas. For AI researchers it will be a never before explored novel domain with unique challenges, whereas for the synthetic biology community it will be an opportunity to break the complexity barrier it is facing.
_
Machine Learning:
There are a wide range of applications in which it would be useful to have a small synthetic biology circuit that could reliably classify cell state. For example, in Xie et al. 2011, the authors propose a cancer therapy based on a circuit that uses miRNA (micro RNA) markers to test whether a cell belongs to a particular type of cancer and then kills only those cells. The authors then demonstrate an miRNA classifier that can distinguish between HeLa cells (cervical cancer cell line) and several other cell lines. This is a perfect opportunity to apply machine learning techniques to select the relevant features and use supervised learning algorithms. However, there is a catch. Not every classifier/algorithm can be implemented in a cell because cells don’t have the same computational machinery as computers. For example, the classifier in Xie et al. 2011 is just a Boolean formula. Beal and Yaman 2012 have developed an information-based technique for selecting the markers in an effort to create classifiers as described in Xie et al. 2011. Classifiers with auto-selected features are shown in simulation to be as effective as the biologist-created classifier.
_
Knowledge-Based Systems:
BioCompiler (Beal, Lu, and Weiss 2011) uses design motifs to capture well known design constructs, such as
NOT, AND, OR like primitives. These motifs can be considered as AGRN fragments with well-defined composition hooks. Given a high level description using these motifs, the BioCompiler composes them into an AGRN and optimizes using standard compiler techniques, such as dead code elimination and copy-propagation.
_
Knowledge Representation and Reasoning:
The synthetic biology community has been working on developing standards that can capture details about system designs. For example, the Synthetic Biology Open Language (SBOL) group (SBOL 2013) has been developing a data exchange standard for describing genetic parts, devices, modules and systems. This work also encompasses efforts to model and visually represent these designs.
_
Reasoning under Uncertainty:
Many biological processes are inherently stochastic and there are many sources of noise in cellular systems, however accurate enough models are needed so that synthetic biology can be an engineering discipline. A cornerstone of synthetic biology is that predictive design is possible – putting together two parts whose behavior is known will have a predictable outcome. Towards this end, Beal et al. 2012 and others have invested significant effort to characterize parts and make predictions about composite behavior taking uncertainty into account. Better characterizing the uncertainty will enable tools to accurately reason and make predictions about the system.
_
Heuristic Search and Optimization:
In a wet-lab equipment and resources are constrained and present opportunity for heuristic search. Most of the experiments that are run concurrently might benefit from sharing intermediate products. For example, if two circuits that are being built contain a shared DNA substring, we can coordinate the assembly steps so that this shared substring is produced only once. Assembly Planner (Densmore et al. 2010) for BioBrick assembly is a fine example of such an effort.
_
Use of Artificial Intelligence in the design of Small Peptide Antibiotics effective against Antibiotic-Resistant Superbugs: a 2008 study:
Increased multiple antibiotic resistance in the face of declining antibiotic discovery is one of society’s most pressing health issues. Antimicrobial peptides represent a promising new class of antibiotics. Using peptide array technology, two large random 9-amino-acid peptide libraries were iteratively created using the amino acid composition of the most active peptides. The resultant data was used together with Artificial Neural Networks, a powerful machine learning technique, to create quantitative in silico models of antibiotic activity. On the basis of random testing, these models proved remarkably effective in predicting the activity of 100,000 virtual peptides. The best peptides, representing the top quartile of predicted activities, were effective against a broad array of MDR “Superbugs” with activities that were equal to or better than four highly used conventional antibiotics, more effective than the most advanced clinical candidate antimicrobial peptide, and protective against Staphylococcus aureus infections in animal models.
_
IBM, NSF and UCSF team up to apply AI to synthetic biology, create cell design software:
Using cells as sensors, researchers can develop cognitive maps that help us understand the relationships between cell structures and functions that IBM Watson can further analyze. In a sense, they are using cells to give Watson ‘microscopic eyes’ so we can better understand cellular behavior in different conditions, from complex environments to human diseases. Software, robots, and synthetic biology engineer synthetic organisms (essentially nanorobots) that can be used to create efficiencies.
_
Synthetic biology routes to bio-artificial intelligence: a 2016 study:
The design of synthetic gene networks (SGNs) has advanced to the extent that novel genetic circuits are now being tested for their ability to recapitulate archetypal learning behaviours first defined in the fields of machine and animal learning. Here, authors discuss the biological implementation of a perceptron algorithm for linear classification of input data. An expansion of this biological design that encompasses cellular ‘teachers’ and ‘students’ is also examined. Authors also discuss implementation of Pavlovian associative learning using SGNs and present an example of such a scheme and in silico simulation of its performance. In addition to designed SGNs, they also consider the option to establish conditions in which a population of SGNs can evolve diversity in order to better contend with complex input data. Finally, authors compare recent ethical concerns in the field of artificial intelligence (AI) and the future challenges raised by bio-artificial intelligence (BI).
______
______
Moral of the story:
_
- All life forms are composed of molecules that are, in themselves, non-living. One key underlying process that has enabled primitive life to form is the ability of non-living molecules to self-organise. However, molecular events that underpin highly ordered and precisely regulated cellular physiology are somewhat random. This randomness causes mutations which drive evolution. Despite stochastic nature of the molecular events, precise regulation and control of biological processes are mediated by feedback loops and signalling. Biological complexities include interdependent network of biochemical pathways, transcriptional circuits and spatial temporal signalling. A living cell can be considered as a highly complex factory, which is equipped with “machines” that perform variety of different tasks. Machines can be dismantled and designed. Thus, a new research discipline – the so-called Synthetic Biology, has recently evolved. Synthetic biology researchers aim not only production of living from non-living matter, but also using living matter and turning it into machines, which are traditionally considered non-living. One goal of synthetic biology is to better answer basic questions about the natural world and to elucidate complex biological processes—about how DNA, cells, organisms and biological systems function. How did life begin? How does a collection of chemicals become animated life? And, of course, what is life?
_
- Avoid confusion between genetic alphabet and genetic code. Genetic alphabet means four letters in in DNA (A, T, C and G) and RNA (A, U, C and G). These four letters mean adenine, guanine, cytosine and thymine bases in DNA and adenine, guanine, cytosine and uracil bases in RNA. It is the sequence/order of four nucleobases that determines DNA’s instructions, or genetic code. The genetic code consists of three-letter ‘words’ called codons formed from a sequence of three nucleotides (having three bases from four letter genetic alphabet) which codes for one of 20 natural amino acid or stop signal. There are 64 possible codons i.e. 64 possible permutations or combinations of three-letter nucleotide sequences that can be made from the four nucleotides. Of the 64 codons, 61 represent 20 natural amino acids, and three are stop signals. Gene is a sequence/order of nitrogen bases in a DNA strand that act as instruction to make molecule called protein. Genes can be thought of like an input/output system that already does some simple logic. The inputs are molecules that interact with genes to help turn them on or off. The outputs are what the gene makes after it’s turned on — usually a protein of some sort.
_
- Genome size is the total amount of DNA contained within one copy of a single genome and it is typically measured as total number of nucleotide base pairs (bp). Typical viral genome contains thousand bp, bacterial genome million bp (Mb/Mbp) and human genome 3 billion bp (3 Gb/3 Gbp). Please do not confuse million base pair Mb with megabytes (Mb) and billion base pair Gb with gigabyte (Gb) of digital storage. Base pair and byte are different. Length of short DNA strand is measured as number of nucleotide/base pair it contains. 100 nucleotide length means having 100 nucleotide pairs i.e. 100 base pair length.
_
- DNA digital data storage refers to storing digital data in the base sequence of DNA. This technology uses synthetic DNA made using commercially available oligonucleotide synthesis machines for storage and DNA sequencing machines for retrieval. Scientists can encode vast amounts of digital information onto a single strand of synthetic DNA. About 215 petabytes of data, that is, nearly 215 million, billion bytes can be stored in a single gram of DNA. It also has longevity up to thousands of years, as long as the DNA is held in cold, dry and dark conditions.
_
- Digital data can be stored in DNA and vice versa, information in DNA i.e. sequences in nucleotide bases encrypting genetic code can be stored as digital data. Each DNA base pair can be encoded by two bits and 8 bits make 1 byte. Genetic information of entire human genome (3 billion base pairs i.e. 3 Gbp) can be stored in as little as 4 megabyte (4 Mb) of digital data after lossless compression.
_
- Synthetic biology is an interdisciplinary branch of biology and engineering that uses engineering principles to design, develop and assemble biological components, systems and organisms in a rational and systematic way. Synthetic biology aims at the design and construction of new biological parts (e.g. promoters, terminators, open reading frames), devices (combinations of parts) and systems (biological entities, from biological structures to organisms) that do not exist in the natural world and also the redesign of existing natural biological systems to perform specific tasks for useful purposes. Synthetic biology equipped with engineering-driven approaches of modularization, rationalization and modelling, and engineering tools such as abstraction, decoupling, and standardization has progressed rapidly and generated an ever-increasing suite of genetic devices and biological modules. The first international conference on synthetic biology charted its goals as understanding and utilizing life’s diverse solutions to process information, materials, and energy. One of the common goals of synthetic biology is to make the design of new function vastly more efficient, safe, understandable, and predictable to create useful applications.
__
- With modern genetic engineering, it is possible to recombine, cut and paste genes from one organism into another target organism. Synthetic biology (synbio) is an extreme version of genetic engineering. Synthetic biology is genetic engineering 2.0. Instead of swapping genes from one species to another, synthetic biologists employ a number of new genetic engineering techniques, such as using synthetic (human-made) DNA to create entirely new forms of life or to “reprogram” existing organisms to produce chemicals that they would not produce naturally, by applying engineering principles such as standardisation, modularisation, and reusability. Synthetic biology’s practitioners are computer scientists rather than biologists, who apply far more mechanistic, reductionist perspective to living systems than do traditional genetic engineers. Genetically modified organisms (GMO) are modified natural organisms while synthetic organisms/cells and artificial cells are beyond natural organisms. However some work from genetic engineering overlaps with synthetic biology.
_
- Systems Biology lays the basis for engineering organisms i.e. synthetic biology. However, Systems Biology and Synthetic Biology should be differentiated. While both disciplines consider modelling and simulation as important tools, Systems Biology aims at the quantitative understanding of natural biological systems, and not at the engineering of new functions, or properties.
_
- Although the terms synthetic biology and synthetic genomics appear to be interchangeable; synthetic biology means design and construction of biological components, functions and organisms (that do not exist in nature) and the redesign of existing biological systems (to perform new functions) while synthetic genomics means generation of chemically synthesised whole genomes or larger parts of genomes from short strands of synthetic DNA called oligonucleotides (which are produced chemically and are usually less than 100 nucleotides in length) to allow for simultaneous multiple changes to the genetic material of organisms. Many synthetic genomics techniques have been used in synthetic biology.
_
- Computational biology is the study of biology using computational techniques. Bioinformatics is the creation of tools (algorithms, databases) that work on biological data to solve problems, for example string searching or matching algorithms developed to search for specific sequences of DNA nucleotides.
_
- There is so much overlap between nanotechnology and synthetic biology that attempts to define their respective boundaries are difficult and futile.
_
- Top-down synthetic biology attempts to eliminate the problem of natural complexity by removing it, e.g. by stripping a genome of all genetic material that is not absolutely essential for replication and functionality. Top-down approach reduces the genome to the minimal set of genes (minimal genome) required for survival and replication of the organism in a particular environment and these minimal cells, also termed “chassis”, serve as platform cell factories into which synthetic elements can be added. Top-down approach creates synthetic organisms. Bottom-up synthetic biology broadly falls into two categories: (i) Artificial cells (protocells) are living cells constructed from scratch. Three basic elements are needed for the construction of a living artificial cell to perform the essential functions of life. These include cell membrane, information-carrying molecule DNA or RNA, and metabolism system. By means of the Bottom-up approach, Synthetic Biology becomes independent of microorganisms, which bring along their own evolutionary history, and can also specifically adapt the newly designed structures to the relevant requirements. (ii) In vitro life, where biochemical reactions placed together can carry out the functions of life and act as atypical artificial cells. Cell-free synthetic biology system activates biological machinery without the use of living cells. It allows direct control of transcription, translation and metabolism in an open environment. Cell-free synthetic biology could be used to produce atypical artificial cell entities that possess some functions of a living cell.
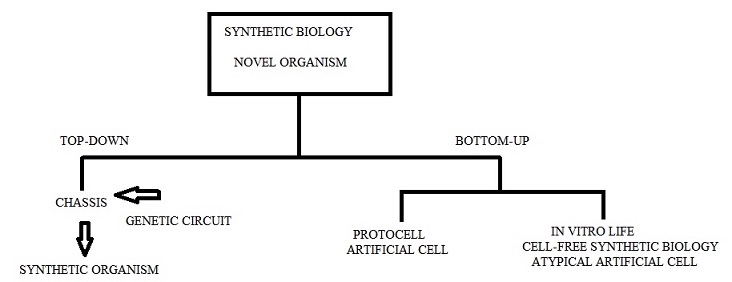
_
- A chassis can be a living organism, or it can be abiotic, providing only the necessary biochemical components for in vitro transcription and translation. The chassis is often referred to as the ’hardware’ in synthetic biology and the synthetic DNA as the software. The synthetic DNA is optimised for the functionality within the chassis whether it is a simple biological switch, an oscillator or a biosensor. By far the most common chassis in use today are bacteria E. coli. and yeast Saccharomyces cerevisiae.
_
- An innovative gene-editing technology known as CRISPR (Clustered Regularly Interspaced Palindromic Repeats) has emerged as a promising technique for gene editing. CRISPR essentially enables researchers to edit the DNA of any species at a precise location. The ability to cut and splice genes so quickly and so precisely has potential applications for the ability to create new biofuels, materials, drugs and foods within much shorter time frames at a relatively low cost.
_
- One of the most important and basic techniques in synthetic biology is gene cloning (DNA cloning). In this process DNA of interest is physically joined to plasmid to create new recombinant plasmid which is inserted in host cell (e.g. E. coli.) for replication so that desired protein is produced by host cell.
_
- DNA sequencing (DNA reading) is any method or technology that is used to determine the precise order of the four bases—adenine, guanine, cytosine, and thymine—in a strand of DNA. Synthetic biologists make use of DNA sequencing in their work in several ways. First, large-scale genome sequencing efforts continue to provide a wealth of information on naturally occurring organisms. This information provides a rich substrate from which synthetic biologists can construct parts and devices. Second, synthetic biologists use sequencing to verify that they fabricated their engineered system as intended. Third, fast, cheap, and reliable sequencing can also facilitate rapid detection and identification of synthetic systems and organisms.
_
- The fundamental tool of synthetic biology is undoubtedly gene synthesis. Gene synthesis by recombinant DNA cloning and polymerase chain reaction (PCR) is now being rivalled by de novo synthesis of DNA (oligonucleotides). This differs from DNA cloning and polymerase chain reaction (PCR) in that the user does not have to begin with preexisting DNA sequences. Now it is possible to make a completely synthetic double-stranded DNA molecule with no apparent limits on either nucleotide sequence or size. For example, with this technology, scientists can download the genetic code of a virus and construct the DNA in a laboratory setting.
_
- Oligonucleotides or oligos are sub-gene length small pieces of DNA usually less than 100 nucleotides in length (100 base pairs). Oligonucleotides may be purchased from commercial oligonucleotide manufacturer or synthesized in a laboratory. They are then subjected to a series of biochemical manipulations that allows them to be assembled into the gene or genome of interest. Today, using machines called DNA synthesizers, the individual subunit bases adenine (A), cytosine (C), guanine (G), and thymine (T) can be assembled to form the genetic material DNA in any specified sequence, in lengths of tens of thousands of nucleotide base-pairs using readily accessible reagents.
_
- De novo synthesis of DNA from nucleosides confers a number of unique advantages. First, engineering new functions often requires vastly modified or wholly new genetic sequences that are most easily accessed by de novo synthesis methodologies. Second, synthesized constructs are often superior to natural sequence for the study of genetic mechanisms because they can be designed to specifically test hypotheses for how sequence affects function. Finally, sequences that are targeted to be amplified or modified from natural sequences can be difficult to access thus synthesis is the only practical way to experimentally study them.
_
- A critical barrier to low-cost, high-throughput de novo DNA synthesis is the frequency at which errors pervade the final product. Oligonucleotide synthesis can have average step-wise yields (ASWY) of 99%, i.e. roughly one error introduced per 100 bases.
_
- Synthetic biology is the convergence of nanoscale biology, computing and engineering. Biology is following the general footsteps of the computer industry — except in this case, DNA is our computer program. Now we can read and write the genetic code, put it in digital form and translate it back into synthesized life. With DNA sequencing, we can read DNA, which provides us with lots of important information. Once we read this information, we have to understand what the code is saying. Machine learning (artificial intelligence) and data analysis are helping us in this regard, but writing the code (DNA synthesis) is where it gets most interesting. After all, writing is where we can be creative! Synbio actually constructs the new genes or genomes it uses, from short strands of synthesized DNA made in a DNA synthesizer from inert chemicals. Synbio can involve natural genes that have been redesigned to be more efficient, natural genes that are revamped to function in a new way or completely new artificial genes—some of which have no counterpart in nature. Software tools combined with CRISPR editing technology allow us edit DNA of any species at a precise location. Bioinformatics software have made computational analysis on DNA sequencing data easier to generate powerful statistical hypotheses to understand how genome sequence controls cellular functions across organisms and populations. Digital manipulation of digital genetic code before synthesis into DNA can be used to optimize protein expression in a particular host, or remove non-functional segments in order to facilitate further replication of the DNA. The emerging field of Synthetic Biology aims to write new genetic information, thereby creating designed non-natural genes, proteins, biological processes and organisms.
_
- A biological part (or simply, part) is a sequence of DNA that encodes for a specific biological function, for example promoters, operators, upstream activation sequences (UAS), ribosome binding sites (RBS), open reading frames (ORF), terminators or protein coding sequences. At its simplest, a basic part is a single functional unit that cannot be divided further into smaller functional units. Basic parts can be assembled together to make longer, more complex composite parts, which in turn can be assembled together to make devices that will operate in living cells. A functional gene or “composite part” usually consists of a promoter, a translation start site (the RBS in prokaryotes), the protein coding ORF and a terminator. Genetic device is a combination of parts that implement a defined function, for example production of a protein. Devices are further combined into a system, which can be defined as the minimum number of devices necessary to perform the behaviour specified in the design phase. Systems can have fairly simple behaviour (e.g. an oscillator) or more complicated behaviour (e.g. a set of metabolic pathways to synthesise a product). Genetic circuit is a system of connectivity of biological parts and their ability to collectively process logical operations. The successful design and construction of the first synthetic genetic circuits — the genetic toggle switch (Gardner et al., 2000) and the repressilator (Elowitz and Leibler, 2000) showed that engineering-based methodology could indeed be used to build sophisticated, computing-like behaviour into biological systems. In these two cases, basic transcriptional regulatory elements were designed and assembled to realize the biological equivalents of electronic memory storage and timekeeping. Just as engineers use Boolean logic gates to build digital devices, synthetic biologists can encode logic operations in networks of these DNA modules. Synthetic genetic circuits are stretches of DNA manipulated to change gene expression within cells and cause the cell to produce a desired product. For example DNA elements are made to act as toggle switches that can be turned on or off, ones that reduce noise in response to negative feedback, and ones that create an oscillating signal, among others. Instead of one gene, a whole system of several genes that interact with each other is transferred to a host organism. These systems, or circuits, are responsible for certain functions within the host organism, such as producing a specific protein or turning on/off a particular cellular function. Systems must be implemented in a chassis, which provides the underlying biology necessary to transcribe and translate the system as well as any enzymatic substrates that would be necessary. Regulatory elements are of pivotal importance for designing predictable system. Regulation is achieved at several levels in biological systems: transcription, RNA processing, translation, protein-protein interactions, and protein-substrate interactions. Spatial and temporal organisation of these control systems ensures their proper function. Thus synthetic biology was born with the broad goal of engineering or ‘wiring’ biological circuitry — be it genetic, protein, viral, pathway or genomic — for manifesting logical forms of cellular control. The natural activity of cells is controlled by circuits of genes analogous to electronic circuits. Synthetic biology makes cells do new things by creating novel internal circuitry to alter their pattern of activity. Using well-understood genetic components that act as molecular switches, synthetic biology devises artificial gene networks.
_
- Different cell populations can be engineered to perform different functions by building different biological circuits in them and when cultured together, due to cell to cell communication & division of labour, they would come up with complex novel function hitherto unattainable in individual cell population. Because members of engineered microbial consortia communicate and differentiate, consortia can perform more complex tasks and can survive in more changeable environments than uniform engineered populations. This is the concept of engineering multiple cells to work in unison.
_
- If the complexity of biology is to be tamed, then standardization becomes of paramount importance. The synbio community is working towards building standard biological parts and methods that can be exchanged from one laboratory to another without the need to re-invent them all the time. The aim is to standardise biology and to make it more reproducible. Standardisation is necessary to accurately reproduce synthetic biology devices and systems.
_
- “BioBricks™” are standardised biological parts (basic and composite), which conform to the BioBrick™ assembly standard. Adhering to this standard guarantees compatibility between parts and/or to BioBrick™ plasmid carriers and allows that any newly composed part will be ready for recombination with other parts adhering to the BioBrick™ assembly standard without the need for further genetic manipulation. Examples of BioBricks are a “promoter” sequence that initiates the transcription of DNA into messenger RNA, a “terminator” sequence that halts RNA transcription, a “repressor” gene that encodes a protein that blocks the transcription of another gene, a ribosome-binding site that initiates protein synthesis, and a “reporter” gene that encodes a fluorescent jellyfish protein, causing cells to glow green when viewed through a fluorescence microscope. A BioBrick must have a genetic structure that enables it to send and receive standard biochemical signals and to be cut and pasted into a linear sequence of other BioBricks, in a manner analogous to the pieces in a Lego set. However many of the components in the BioBrick registry are unreliable. Even if they worked in one context under specific conditions, there’s no real guarantee that they’ll work consistently in others. Ultimately the Lego comparison may be inapt, partly because parts don’t always fit together well in cells and may integrate into them in unpredictable ways. Also many parts are incompatible.
_
- In the area of synthetic biology, a living “artificial cell” has been defined as a completely synthetically-made cell that can capture energy, maintain ion gradients, contain macromolecules as well as store information and have the ability to mutate. Nobody has been able to create such an artificial cell. What is created is living organism with ‘artificial’ DNA where E. coli was engineered to replicate an expanded genetic alphabet; completely synthetic genome introduced into genomically emptied bacterial host cells, and allowed the host cells to grow and replicate; protocell made of DNA and proteins packaged inside lipids; and artificial yeast chromosomes built from synthetic strands of DNA which replicated itself in living yeast cells. Breaking down organisms into a hierarchy of composable parts, although useful as a tool for conceptualization, should not lull the reader into thinking that these parts can be assembled ex nihilo. Because we do not yet know how to confer the properties of life onto an aggregate of physically dynamic but ‘dead’ material systems, composing artificial living systems requires the use and modification of natural ones. Therefore, assembly of parts occurs in a biological milieu, within an existing cellular context.
_
- Synthetic biology will not achieve its potential until scientists can predict accurately how a new genetic circuit will behave inside a living cell. The engineering of biological systems remains expensive, unreliable, and ad hoc because scientists do not understand the molecular processes of cells well enough to manipulate them reliably. The behavior of bioengineered systems remains “noisy” and unpredictable. Genetic circuits also tend to mutate rapidly and become non-functional. Interactions of synthetic components with endogenous players in different pathways within a given cell are inevitably a problem. Cell death and changing extracellular environments also cause problems in engineering cells. Engineers’ efforts in the field of engineering biology are furnished with only a few success stories. This reflects the fact that the ability to engineer biology in a directed and successful manner is still rather limited today and as a consequence, the complexity of things we can efficiently make is still quite small. Researchers are just coming to grips with the complexities of human systems. Synthetic biology tools currently developed may get lost in the noise of complex systems. If the outcome of a simple genetic manipulation can’t be predicted with certainty, it’s going to be very difficult to predict the outcome of a complex engineered biological system within a human cell.
_
- Synthetic biology has failed to scale significantly in complexity due to its overemphasis on digital paradigms to engineer switches and logic gates. Signals in cells are stochastic (noisy) and analog (graded) in their nature, and although ‘1’s and ‘0’s of digital computers are useful abstractions of the analog signals in cells, it is an oversimplification. Analog computation is extremely important for the cell’s incredible efficiency vis-à-vis use of energy, time and space. Analog computing and artificial intelligence can help synthetic biology overcome its complexity barrier.
_
- Synthetic biology projects (SBPs) are divided in vivo SBPs and in vitro SBPs: SBPs entail the complex manipulation of replicating systems, ranging from the sophisticated genetic engineering of organisms to the chemical synthesis of unnatural replication. In vivo SBPs mostly involve bacterial/yeast engineering, have diverse goals, and are generally more suited than in vitro SBPs for large-scale production/conversion of materials. In vitro SBPs entails synthesizing circular DNAs, modified RNAs, proteins containing unnatural amino acids and liposomes; and better understanding secrets of life. Very different types of outputs, from genetically engineered bacteria to chemically synthesized genomes, to chemically assembled cells or even computer models of an artificial metabolism can all be considered intermediate- or end-products of synthetic biology.
_
- Synthetic proteins are man-made molecules that mimic the function and structure of true proteins. Synthetic proteins have genetic sequences that are not seen in natural proteins. Proteins must fold to function. Creating synthetic proteins may help researchers understand protein folding and why certain amino acid sequences are central to human existence, and learn more about cell signalling and immune responses to pathogens.
_
- In conventional tissue engineering and regenerative medicine, actions of cells themselves are still controlled by their evolved ‘developmental programmes’ which imposes a significant limitation on its scope, synthetic biology liberates this field from such limitation.
_
- The evolution of life on Earth has been dictated by the underlying constancy of the nearly universal twenty amino acid genetic code. Synthetic biology technologies have expanded genetic codes with a non-canonical amino acid (ncAA). It has been shown that microorganisms given the ability to encode a 21st amino acid would evolve to utilize this new chemical building block on mutational pathways to higher fitness i.e. use an expanded genetic code to evolve to higher fitness. As a corollary I hypothesize that humans can evolve to super-human beings by expanding genetic code.
_
- Synthetic biology can be regarded as a platform technology that cuts across several key market sectors, such as energy, chemicals, medicine, environment and agriculture. The potential payoff for the ability to build and sell novel living organisms is considered to be so great that venture capitalists, government agencies and multinational corporations are already investing in research and partnerships with startup companies to drive synthetic biology products to market as quickly as possible. One study reported that synthetic biology market reached nearly $3.9 Billion in 2016 and should reach $11.4 Billion by 2021 while another study forecasts synthetic biology market to grow to $38.7 billion by 2020.
_
- Synthetic biology ideas for production of biofuels/ drop-in fuels can be ascribed to two fundamental strategies: the microbial synthesis of fuels from materials produced by plants or their direct microbial photosynthesis from CO2 and water. Millions of dollars are poured into funding synthetic biology biofuels research. So far, progress has been limited.
_
- We need to reduce carbon emissions and toxic inputs, use less land and water, combat pests, and increase soil fertility. Scientists have already developed genetically modified crops that can provide higher yields from less land and more resistance to drought, disease and pests. But synthetic biology plants perform photosynthesis more efficiently by harvesting light from wider regions of the spectrum, or even capture nitrogen directly from the air so they won’t need nitrogen fertiliser. By assembling biological systems from genetic code catalogued in online databases and fine-tuned through computer modelling, scientists could deliver more-nutritious crops that thrive with less water, land, and energy, and fewer chemical inputs, in more variable climates and on lands that otherwise would not support intensive farming.
_
- Anything that can be made in a plant can now be made in a microbe. Yeast cells have been redesigned to produce a compound called artemisinic acid, which is used to make artemisinin. Artemisinin is antimalarial drug derived from the sweet wormwood plant, Artemisia annua.
_
- Synthetic biologists hope that by building biological systems from the ground up, they can create biological systems that will function like factories, producing the products we want, when we want and in the amounts we want. Another synbio product on the market today is synbio vanillin, an alternative to artificial vanilla flavor. Synthetic DNA is designed on a computer and inserted into the DNA of naturally occurring yeast. The synbio yeast are fed sugar and biosynthesize vanillin through a fermentation process.
_
- Feeding nearly 10 billion people by 2050 while fuelling their cars and clearing up their waste threatens to exhaust the planet’s handling capacity. Synthetic biology may provide at least some of the answer. Proponents of synthetic biology claim that the ability to create, manipulate and cheaply manufacture customized or unique life forms will produce many benefits across a wide range of applications, from medicine to energy generation and environmental remediation. They also say synthetic organisms will be able to produce new kinds of pharmaceutical compounds and plastics, as well as detect toxins, break down air and water pollutants, destroy cancer cells, and generate hydrogen and other substances for new energy technologies. Synthetic biology will change the way we create energy, produce food, optimize industrial processing, and detect, prevent, and cure disease. Major efforts toward potential application of synthetic biology include the production of biofuels like ethanol, algae-based fuels, bio-hydrogen and microbial fuel cells; bioremediation like wastewater treatment, water desalination, solid waste decomposition and CO2 recapturing; the production of biomaterials like bioplastics, bulk chemicals, pharmaceuticals, flavourings, fragrances, and compounds for cosmetics; and finally the production of novel cells and organisms, which includes the generation of protocells and xenobiology.
_
- Xenobiology describes novel biological systems and biochemistries that differ from the canonical DNA-RNA-20 amino acid system. It focuses on nucleic acid analogues, expanded genetic alphabet, expanded genetic code, non-natural amino acids and the incorporation of non-natural amino acids into proteins.
_
- Synthetic biology raises many concerns. The behavior of synthetic biological systems is inherently uncertain and unpredictable. The risks created by the development of synthetic biology are of two types: biosafety, in which adverse consequences are the result of accidental or unforeseen events; and biosecurity, in which the insights of synthetic biology are used with malign intent – in biological weapons, for example. Some of the risks of synthetic biology are simply indefinable at present. Although existing national laws and regulations may apply to some aspects synthetic biology, there is no comprehensive regulatory apparatus for synthetic biology at the national or international level. However if synthetic biology is to fulfil its promise, scientists must be trusted to do the right thing. Synthetic organisms can be controlled with physical/trophic containment, kill switch (suicide genes) and incorporating non-natural bases and backbones in nucleic acids.
_
- I would like to differentiate artificial life from synthetic life although these terms are used interchangeably. Artificial life is the strongest form of artificial intelligence where digital “organisms” reproduce, reprogram, evolve, learn and improve; and these “organisms” do not exist physically but only in the virtual world. Synthetic life is the life of synthetic organisms and protocells (artificial cells) who exists physically in the real world. Synthetic DNA is identical to natural DNA albeit synthesized chemically while artificial DNA is also synthesised chemically but having non-natural bases or backbones. So synthetic DNA and artificial DNA are different although both terms are used interchangeably, and both can be used in the creation of synthetic organisms (top-down synthetic biology) and protocells (bottom-up synthetic biology).
_
- Synthetic organisms with advanced genetic circuits are able to learn similar to animal learning and machine learning. This is the concept of bio-artificial intelligence or synthetic intelligence. So now we have three types of intelligence; natural biologic intelligence (e.g. human intelligence), machine intelligence (e.g. artificial intelligence) and synthetic intelligence (e.g. bio-artificial intelligence of synthetic organisms). There is a fantastic possibility of a synthetic bio-computer which performs many of the tasks currently performed by PCs, which is based not on the silicone chip, but on neural networks composed of synthetic human nerve cells. This synthetic intelligence will mimic biological human intelligence.
_
- Two ethical concerns are raised by synthetic biology:
First: Creation of synthetic organisms and protocells provokes fears about scientists ‘playing God’. For example an alga that is capable of producing biofuels from carbon dioxide in the environment. According to synthetic biologists, organisms like these would be considered new species that could not have evolved from nature and would even have to be classified in a separate domain of life.
Second: Creation of entities which fall somewhere between living things and machines blurs the boundary between our understanding of living and non-living matter. For example, bacterial/yeast bio-factories might possess many of the characteristics that we ordinarily take to be definitive of life: homeostatic physiological mechanisms, a nucleic acid genome and protein-based structure, and the ability to reproduce. But they would also possess many of the features characteristic of machines: modular construction, based on rational design principles, and with specific applications in mind.
My view is that God does not exist, so ‘playing God’ makes no sense. Since synthetic biology has already built biological machines and not mere better organisms, the distinction between living things and machines is already blurred, so we have to rethink about what is life anyway. Also ethical concerns about abortion, stem cell research, human-nonhuman chimeras, artificial intelligence and treatment of animals need to addressed even before addressing ethical concerns about synthetic biology.
_____
Dr. Rajiv Desai. MD.
May 7, 2017
_____
Postscript:
People who believe that God exists and created life on earth must read this article. It’s time for them to review their belief. We should be prepared for an era in future when synthesizing and editing human DNA is as easy as writing and editing a Microsoft Word document.
_____
Footnote 1:
Terminology in synthetic biology is confusing and inconsistent. Artificial is often portrayed synonymous with synthetic. Although in English language, artificial is synthetic, I want to differentiate different types of organisms constructed through different approaches of synthetic biology having different biological milieu. So synthetic organisms and artificial organisms are not same, and synthetic DNA and artificial DNA are not same.
_
Footnote 2:
According to Dr. Michael Selgelid, a synthetic biology expert, the power of synthetic biology has put scientists in a situation similar to that of physicists who were involved with the making of the first atomic bombs. He says this is also a “dual use” form of technology, where the intentions are initially good, but could also be used in potentially destructive ways. For instance, this technology could create a virus as deadly and incurable as smallpox, wiping out thousands, if not millions, of people with one slip. However, most researchers and scientists do not want such valuable research and technology tossed out due to fears of misuse. Many researchers would like authorities to closely monitor the science to make sure it is used within its intended purposes. While the risk of biological terrorism may be a real one, scientists say it is unlikely that any potentially dangerous synthetic biology research would be approved, and it is unlikely that scientists working with the proper materials would create a deadly disease just by accident.
________
172 comments on “SYNTHETIC BIOLOGY (SYNBIO)”
Leave a Reply

I cannot thank you enough for the post.Really thank you! Awesome.
Your excitement is transmittable and your hard work and devotion have been invaluable. We can not thank you sufficient for everything that you do!
Everything is very open with a really clear explanation of the challenges. It was truly informative. Your website is extremely helpful. Many thanks for sharing!|
If some one wants expert view regarding running a blog after that i propose him/her to go to see this weblog, Keep up the good work.|
Fantastic goods from you, man. I have understand your stuff previous to and you’re just too fantastic. I actually like what you’ve acquired here, certainly like what you are saying and the way in which you say it. You make it entertaining and you still care for to keep it sensible. I cant wait to read much more from you. This is really a wonderful site.|
Your style is really unique compared to other people I’ve read stuff from. I appreciate you for posting when you have the opportunity, Guess I’ll just book mark this web site.
This site was… how do you say it? Relevant!! Finally I’ve found something that helped me. Thank you.
That is a very good tip especially to those new to the blogosphere. Short but very accurate infoÖ Appreciate your sharing this one. A must read post!
Very informative post.Really looking forward to read more. Want more.
Wonderful post! We will be linking to this great content on our website. Keep up the good writing.
I truly appreciate this post.Much thanks again. Will read on…
Wow, great post.Really looking forward to read more. Really Cool.
You’re so awesome! I don’t believe I’ve read through anything like this before.
So nice to discover another person with some unique thoughts on this topic.
Seriously.. many thanks for starting this up. This site is
something that is required on the internet, someone with a
little originality!
Everything is very open with a very clear description of the challenges. It was really informative.
I like this website because so much utile material on here : D.
Really Appreciate this update, can you make it so I get an alert email when there is a fresh post?
This web site is known as a walk-through for the entire info you needed about this and didn’t know who to ask. Glimpse right here, and you’ll undoubtedly uncover it.
An fascinating discussion is value comment. I feel that it’s best to write more on this topic, it won’t be a taboo subject but usually people are not sufficient to talk on such topics. To the next. Cheers
Wow! Thank you! I always needed to write on my website something like that. Can I take a fragment of your post to my blog?
Quality content is the main to attract the people
to go to see the website, that’s what this website is providing.
This piece of writing will assist the internet users
for creating new blog or even a blog from
start to end.
“Hello my loved one! I wish to say that this article is amazing, great written and come with almost all significant infos. I’d like to see extra posts like this .”